"A good picture is equivalent to a good deed."—Vincent Van Gogh。(Patrick:看了几遍才看明白,主要是突然看到这句话的作者,梵高,这两年去欧洲看了不少梵高的作品。那么再看这句话就明白了,意思是,好的作品会说话,或者说是好的作品有力量。结合下面要说的不同风格的作品,就很好理解了。)
当绘制一幅3D图片的时候,不只是要把每个物件的几何形状表达清楚,还需要使用合适的外观。根据产品不同,可以使用写实风(几乎和实物照片完全相同的外观),也可以使用更有创造性的各种风格化外观。如图5.1所示

上面的图片是来自UE渲染的真实风格场景,由Gokhan Karadayi提供。下面图片来自于Campo Santo的游戏Firewatch,使用的是风格化外观,由Campo Santo提供。
本章所介绍的内容同时适用于写实风和风格化渲染。第15章将介绍风格化渲染,然后本书第9-14章将集中介绍用于真实照片渲染的物理算法。
5.1 着色模型
首先,先要选择一个着色模型,用来描述对象的颜色如何根据表面方向normal、视图方向view和光照等因素的变化而变化。
我们以Gooch shading model(参考文献[561])作为例子来开始,它属于非真实渲染NPR,属于第15章的范畴。Gooch shading model旨在提高技术插图中细节的易读性。
Gooch shading的中心思想在于对比表面法线和光源位置。如果法线指向光源,则使用较暖色调为表面着色,如果法线远离光源,则使用较冷色调。当中间角度的时候,再基于用户提供的表面颜色,在冷暖之间做插值。在这个粒子中,我们增加了一个风格化的高光,是的曲面会有光泽外表。图5.2展示了着色模型。

上图为一个结合了Gooch shading和高光效果的风格化找色模型。上面的图是一个使用了中立表面颜色的复杂物件。下面的图为使用不同表面颜色的球体。(中国龙的mesh由Computer Graphics Archive(参考文献[1172])提供,原始模型来自stanford 3D扫描库)
和大多数着色模型一样,此示例受到曲面方向normal、视图view、光照方向的影响。为了进行着色,这些方向通常表示为标准化(单位长度)向量,如图5.3所示。
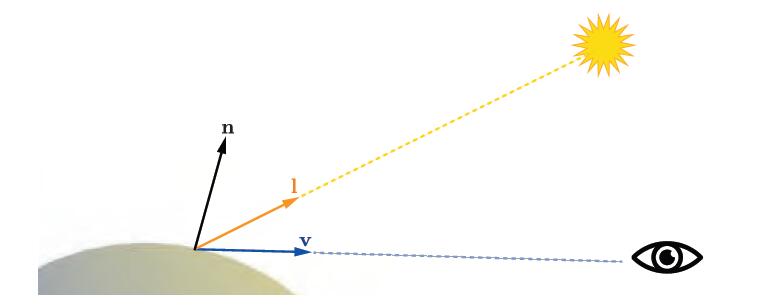
上图展示了用于着色模型的单位向量:表面法线normal、视图view、光照l。
这样的话,我们就定义了光照模型所需要的所有变量,下面为光照模型的公式:
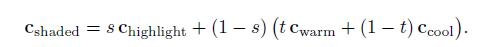
在这个公式中,我们使用了以下的中间计算
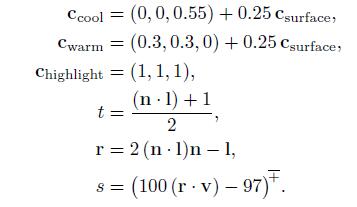
该定义中的很多数学表达式也经常出现在其他着色模型中。clamp操作经常在着色中用于将结果限定在0到正无穷大,或者0到1之间。在这里,用于计算高光混合因子s的公式中可以看到-+符号,这个我们在1.2节介绍过,就是用于表示clapmp(0,1)。点积运算符出现了三次,是一种常见的用于计算两个单位向量夹角余弦的方式,它的结果很精确。比如在着色模型中计算normal和light夹角关系的时候经常会被使用。
还有一个经常被使用的着色运算是使用0-1之间的标量值在两个颜色之间进行线性插值。此操作的公式为tCa+(1-t)Cb,当t的值在0-1之间移动时,在Ca和Cb之间进行插值。该公式在着色模型中出现了两次,第一次是Cwarm和Ccool之间,第二次是上次插值的结果和Chightlight之间。线性插值经常在shading中被使用,所以它有一个内置函数lerp或mix。
公式r = 2(nl)n - l是用于计算光l相对于n的反射矢量。虽然不像前面两个那么常见,但是很多着色语言也会有对应的内置函数reflect。
通过将这些操作以各种不同的方式和参数结合,就得到了各种着色模型用于各种风格(风格化或者写实风)的渲染表面。
5.2 光源
在我们示例着色模型中的光照其实很简单,只是为着色提供了一个主方向。当然,现实世界中的照明可能相当复杂。可以同时存在多盏光源,每个光源都有自己的大小、形状、颜色和强度,如果考虑间接光照的话将会更加复杂。我们在第9章的基于物理的真实着色模型中,会使用到这些所有的因素。
相对比,风格化渲染可能会根据需要,以各种不同的方式使用照明。一些高度程式化的模型可能根本没有照明的概念,或者只使用它来提供一些简单的方向性(比如上面提到的Gooch shading)
光照中下一个比较复杂的地方是需要根据与光照的关系,选择不同的着色模型。这种表面在光下会有一个外观,在不受光的情况下会有另外一个外观。这也就意味着需要区分这两种情况的一些标准:与光源的距离、阴影(第七章)、表面是否背离光源(n和l的角度超过90度),或者是这些因素的合集。
或者换一种方式来思考,我们不再考虑光照是否存在的二元性,而是考虑光照强度的连续渐变。这样的话,就可以从光源完全不存在到光源完全存在进行插值,强度的范围可以用0-1表示。或者还有另外一种方式,将各种影响着色的因素相加,常见的方式是:将着色模型分解成亮部和不亮部,灯光强度Klight线性的影响光照部分:
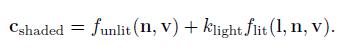
针对RGB的光照Clight可以将公式扩展为
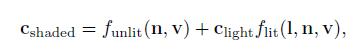
针对多个光源的情况为:
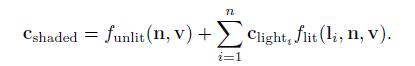
不受光的部分funlit(n,v)相当于二元性着色模型中处理表面不受光影响的部分。根据游戏的风格,可以使用多种风格。比如,funlit()=(0,0,0)也就代表着不受光的表面,表现为黑色。其他的,比如也可以类似Gooch model中那样,使用冷色来表示表面背离光照。通常,着色模型中的这一部分表示某种形式的照明,这些照明不是直接来自显示放置的光源,而是来自比如天光或者周围对象反射的光。这些形式的照明将在第10、11章中讨论。
我们前面提到,如果光照方向l与法线n的角度超过90度,则光照不会影响到表面,也就是说光照来自表面下方。这可以被看作是光照对表面的影响的一种特殊情况。尽管这种情况是基于物理的,但其实对很多非物理的风格化着色模型也很有用。
光对表面的影响可以被看作是一组光线,照射到表面的光线密度与用于表面着色的光照强度相对应。如图5.4所示,该图显示了照明表面的横截面。沿着横截面照射到表面上的光线的间距与L和N之间夹角的余弦值成反比。因此,照射到表面上的光线的总比密度与L和N之间夹角的余弦值成正比,余弦值为L和N两个单位长度向量的点积。在这里我,我们也就可以看到为什么光向量L与实际光的方向相反,因为不然的话,必须先对它求反(Patrick:原来如此)
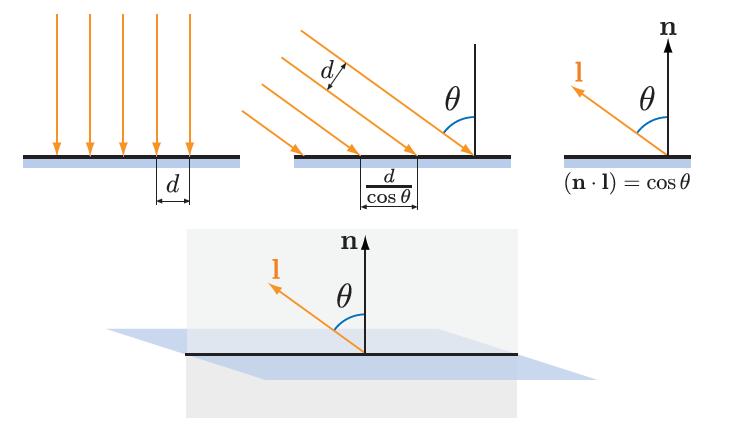
更准确的说,光线密度(或者说光线对着色的贡献程度),当点积为正数时,与点积成正比。当点积为负数时,也就是说,光线是从表面后面发出来的,这样没有效果。所以,当用点积计算光照着色的时候,首先先clamp到0,。在这里可以使用1.2节的符号x+,将负值限制到0,也就是如下公式
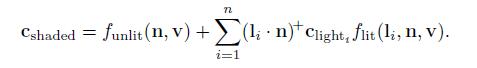
支持多个光源的着色模型,可以使用公式5.5(更通用),或者5.6(基于物理)。这些公式同样也可以用于风格化模型,可以帮助确保整体照明的一致性,特别是对于背光或者阴影的表面。然而还是有一些光照模型不适合这些结构,一些模型要用5.5公式。
最简单的光照模型是将其看成一个常数颜色
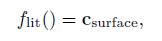
也就得到如下着色模型
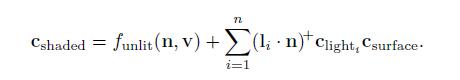
这个模型被称为lambertian光照模型,是由Johann Heinrich Lambert(参考文献[967])于1760年发布。该模型适用于理想情况下的漫反射表面,也就是毫无光泽的表面。这里我们先简单的介绍一下它,然后再第9章会更详细的介绍。Lambert模型本身可以用于简单的着色,同时也是很多着色模型中的关键组成部分。
从上述公式中,我们可以看到,光源是通过两个参数影响光照模型:光照的方向l,以及光照的颜色Clight。所以,可以根据光源的这两个参数,将光源分成各种不同类型。
下面我们将来聊一些常见的光源,它们有个共同点:在给定的表面位置,每个光源仅从一个方向l照亮表面。换句话说,从阴影表面位置看,光源是一个小点。对于现实世界中的光源,这并非完全正确,但是大多数光源相对于被其照亮的表面的距离来说,都很小,所以也是一个合理的近似值。在7.1.2节和10.1节中,会讨论那些从各个方向对一个点产生影响的光源,面光源。
5.2.1 方向光
方向光是光源中最简单的类型。l和clight在场景中都是恒定的,clight可以通过阴影减弱。方向光没有位置。当然,实际光源肯定是有位置的,然而由于方向光是抽象的,当与灯光距离比较大的时候,比如,一个很远的灯光照亮桌面上的一个小物件的时候,可以看成是方向光。另外一个例子是使用太阳的场景,基本都会认为太阳是方向光,除非讨论的场景是整个太阳系。
方向光的概念可以稍微扩展一下,以允许在光方向l保持不变的情况下,改变clight的值。这通常是想借助光效,实现场景中的一些特殊效果。比如,将一个区域定义成两个嵌套的区域,在这两个区域过度的时候进行平滑插值得到clight。
5.2.2 精准光源
精准光源是指有位置的光源。与现实世界的光源不同,这种光源也没有尺寸和形状。Punctual来自拉丁语中的Punctus,是点的意思。用来表示单一的,有位置的所有类型的光源。点光源代表着向各个方向均匀发光的光源。聚光灯和点光源是两种不同类型的精准光源。光的方向l取决于当前正在绘制的表面点P0,以及精准光源的位置Plighting
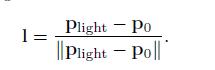
这个公式也是向量归一化的一个示例:向量除以向量的长度,以得到一个相同方向的单位长度向量。这也是一个常见的操作,在大多数着色语言中有对应的内置函数。但是,有时也需要此操作的中间结果,这样就需要把这个公式拆成好几步,如下所示:
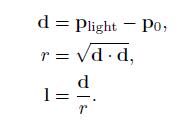
我们知道点积就是两个向量的长度相乘,然后乘以它们夹角的余弦值。而0°的余弦值为1,所以向量和自身的点积等于向量长度的平方。所以,为了计算出向量的长度,我们通常对其自身进行点积运算,然后再进行开方。
通常我们需要中间变量r,也就是光源和当前着色点之间的距离。因为我们有时候会用r距离作为衰减因子,这个将在后面进行讨论。
Point/Omni Lights
在所有方向均匀发光的精确光源被称为点光源或者Omni光源。对点光源来说,Clight的值随着距离r的变化而变化,唯一的变化源是上面提到的距离衰减。图5.5显示了这种变暗现象发生的原因,原理和图5.4的余弦系数差不多。但是与5.4的余弦系数不同,针对平行光,垂直于平行光方向移动物件,物件上的点与光源的夹角始终不变,但是点光源不一样。来自点光源的光线之间的间距与从表面到光源的距离成比例关系,所以该点与光源的夹角也在变化。(Patrick:原来如此)所以随着间距的增加,变化是分为两个维度的,所以光线密度与距离的平方成反比。这样,我们就可以通过r0点光源Clight0计算出最终的Clight
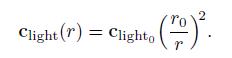
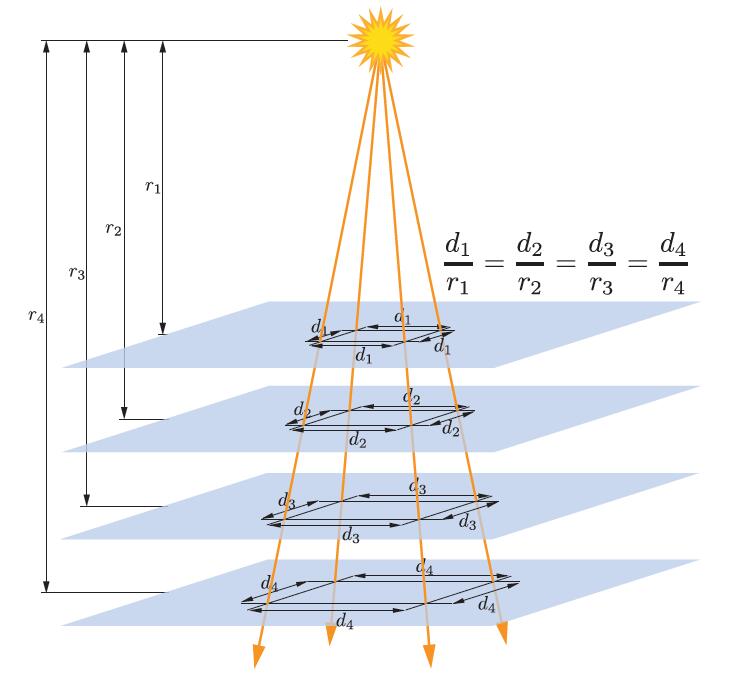
如上图所示,光线之间的距离随着距离r的变大而变大。所以光线密度/强度与r的平方成反比。
上面这个公式被称为inverse-square light attenuation。尽管技术上没毛病,但是在实际着色中可能会出问题。
首先,第一个问题出现在短距离的情况下。当r趋近于0的时候,clight将无限大。当r等于0的时候,就会遇到除0的问题。通常的解决方案是加一个很小的值做除0保护(参考文献[861]):
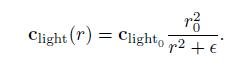
这个很小的值的具体取值取决于应用程序,比如Unreal取极小值为1厘米。(参考文献[861])
在CryEngine(参考文献[1591])和Frostbit(参考文献[960])中,将r clamp到Rmin中:
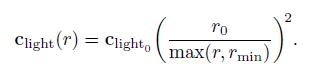
在这里,Rmin有一个物理意义:物理光源的半径,当r小于rmin的时候,物体表面在光源中,这不可能(Patrick:这个比较有道理,R0=Rmin,然后无限靠近光源的时候,Clight=Clight0)
相反,平方反比衰减的第二个问题在相对较大的距离上。问题并非在视觉上,而是性能上。因为尽管光强度随着距离的增加而减小,但它永远都不会到达0。而为了有效的渲染,我们希望灯光在某个有限距离达到0强度(详见第20章)。有许多不同的方法可以对平方反比方程进行修改来实现这一点。理想情况下,修改应当尽可能少。而为了避免在光的有效边界处出现尖锐的切口,在相同的距离处,修正函数的导数和值最好同时达到0。一种解决方案是用具有所需特性的开窗函数乘以平方反比方程。UE(参考文献[861])Frostbite(参考文献[960])都使用了这样的功能(参考文献[860])
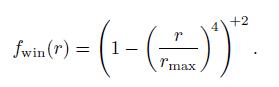
公式中的+2意思为,先将值clamp到0,然后再对其进行平方。图5.6中显示了平方反比曲线的例子,方程式5.14中窗函数的例子,以及它们相乘的结果
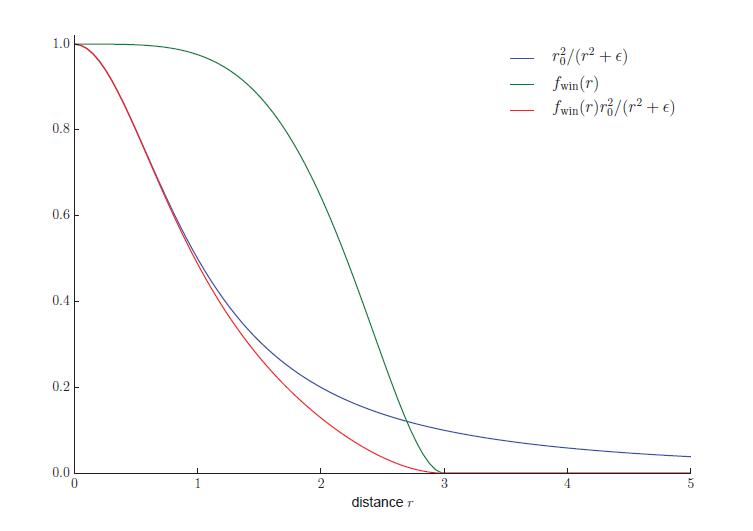
上图中将公式中的Rmax设置为3。
需要根据应用程序的需要选择使用的方法。比如,当距离衰减函数以相对较低的空间频率(比如lightmap或顶点光源)采样时,在Rmax处导数等于0尤为重要。Cryengine不使用lightmap或顶点光照,因此它使用了更简单的调整,在0.8*Rmax到Rmax的范围内采用线性衰减。
在某些应用中,平方反比衰减并非最优选,而选择了其他的一些函数,所以我们将5.11-5.14概括成下述公式:
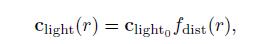
其中Fdist(r)是距离函数。这种函数被称为距离衰减函数。在某些情况下,是由于性能原因而不使用平方反比衰减函数。比如Just Cause 2这个游戏就需要计算量比较少的光源。从而引入了一些计算量比较少,而同样足够平滑以避免顶点光照瑕疵的函数(参考文献[1379])
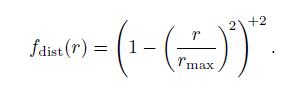
还有一些别的情况,是为了实现一些比较有意思的效果,才选择不同的衰减函数。比如UE中就有两种衰减函数,用于真实和风格化的游戏:一个是平方反比模型,正如5.12公式中一样,另外一个是指数衰减函数用于创建各种各样的衰减曲线(参考文献[1802])。Tomb Raider古墓丽影(2013)的开发者就使用了spline-editing工具(参考文献[953]),从而对衰减曲线进行更强的控制
聚光灯
与点光源不同,真实世界中所有的光源的照明强度,都随距离和方向不同而不同。这种变换可以通过一个方向性衰减函数Fdir(l)表示,它与距离衰减函数相结合,来定义光强度的整体空间变化。
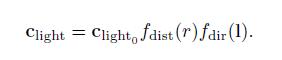
不同的Fdir(l)会产生不同的光照效果。比如聚光灯,是将光线投射到一个圆形的圆锥体中。聚光灯的方向衰减函数围绕聚光灯方向向量s具有旋转对称性,可以通过s和光照方向l的夹角Θ的函数表示。这里的光矢量需要被颠倒,因为我们将光照方向l定义为物体表面到光源,而在这里,我们需要光源到物体表面的矢量。
大多数聚光灯函数会使用由Θs的余弦值组成的表达式。聚光灯通常由一个umbra angle Θu,意味着当Θu>Θs的时候,Fdir(l)=0。该角度可用于与前面看到的最大衰减距离Rmax类似的方式进行剔除。聚光灯还通常会有一个penumbra angleΘp,定义了一个inner cone,在该点光照是完全强度的。如图5.7

如上图所示,Θs为光线方向-l与聚光灯方向s之间的夹角。Θp代表着penumbra,Θu代表着umbra angle。
聚光灯可以使用不同的方向性衰减函数,虽然它们大致相同。比如Frostbite(参考文献[960])使用了函数Fdirf(l),three.js浏览器图形库(参考文献[218])中用到了函数Fdirt(l):
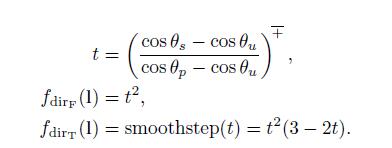
符号X-+代表着clamp到[0,1]。而smoothstep函数则是一个三元多项式,常被用于平滑插值,是大多数着色语言的内置函数。

上图展示了刚才我们所说的光源类型。从左到右,方向光、没有衰减的点港元、平滑过度的聚光灯。注意,当灯光和表面之间的角度发生变化的时候,点光源会逐渐变暗。
其它精准光源
除此之外,还有许多其它的精准光源。
Fdir(l)将不仅限于上述的简单的聚光灯衰减函数。还可以通过测量真实世界中的光源得到的复杂列表模式,来表示Fdir(l)。照明协会Illuminating Engineering Society(IES)为此类测量定义了标准文件格式。可以从很多照明制造商处获取IES配置文件,而且已经被游戏KillZone:Shadow Fall(参考文献[379、380])所使用的,除此之外,还有Unreal(参考文献[861])和Frostbite(参考文献[960])游戏引擎等等都使用了该技术。Lagarde(参考文献[961])总结了如何解析和使用该文件格式。
游戏古墓丽影 Tomb Raider 2013(参考文献[953])有一种精准光源,它的衰减函数是根据世界坐标轴X、Y、Z轴不同区分的。在古墓丽影中,光的强度也可以随着时间变换而沿着一条曲线变化,比如,拾取一个火把。
在6.9节中,我们还会聊一下,如何通过纹理改变光的强度和颜色。
5.2.3 其它光源类型
方向光和精准光源主要是通过如何光照方向L来进行区分。除此之外,还可以使用其它方法来计算光照方向以定义不同类型的灯光。例如,Tomb Raider古墓丽影定义了胶囊灯,使用线段来作为光源,而非点(参考文献[953])。对于每个着色像素来说,光照方向为该点到光源线段中最近的点的矢量。
着色方程式还需要l和Clight作为参数,而这些参数可以通过很多方法得到。
以上聊到的光源都是抽象的。真实世界中的光源都是有尺寸和形状的,且针对物体表面上的照射是从多个方向的。在渲染行业,这种光源被称为面光源,在实时渲染领域,其使用频率也越来越高。面光源的使用主要集中在两个方面:模拟部分遮挡面光源导致的阴影边缘软化技术(详见7.1.2节),模拟面光源对表面着色效果的影响技术(详见10.1节)。其中第二个方面针对光滑的镜面表面影响最为明显,在这些表面上,光线的形状和大小都可以通过其反射清晰的辨别出来。方向光和精准光源虽然不像过去那样无处不在了,但是不太可能被废弃。目前,已经开发出了比较简单的公式模拟面光源的近似值,这种公式耗能低,所以可以得到更广泛的应用。GPU性能的提高也使得可以使用越来越复杂的技术。
5.3 实现着色模型
然后这些着色和光照方程需要在代码中实现。被接种,我们讲讨论一些设计和编写此类实现的关键注意事项。然后会介绍一个简单的实现示例。
5.3.1 运算频率
当设计一个着色模型的时候,需要先根据运算频率将一些运算进行区分。首先,针对在整个DC中,都保持不变的运算,可以将其由应用程序在CPU端执行,尽管GPU也比较擅长运算。然后将CPU运算的结果,通过图形API中的uniform传入。
即使这个类型的数据,也可能分为很多不同的可能性。最简单的例子是着色方程中的常量表达式,然而其实这些可以通过硬件配置或者安装选项等表示。这些计算应当在shader编译的时候就完成,这种情况下甚至不需要通过uniform传入。或者,也可以在离线预计算的时候、安装的时候或者应用程序加载的时候运算。(Patrick:这是指啥?静态分支?)
另一种情况是,着色运算的结果在应用程序运行期间会发生变化,但速度太慢,不需要每帧都更新。例如,光照取决于虚拟游戏世界中的时间。如果光照计算的成本很高,可以尝试通过多帧进行分摊(Patrick:不同频率的cascade shadowmap我明白,多帧一起算OC我也明白。但是光照运算也可以分摊?比如光线追踪中每帧发一条射线,然后多帧混合)
其它的还有,逐帧更新的运算,比如V和P矩阵。逐物件更新的运算,比如依赖位置运算的光照参数。逐DC更新的运算,比如材质球属性。按照频率对uniform进行分组可以有效的提高性能,通过最小化变量更新的方式降低GPU开销。
当某个被需要的运算在一个DC中会发生变化的时候,则不能通过uniform将该运算的结果传入shader,而是需要用到第3章中提到的着色器来计算,如果需要,还可以通过varying来进行不同着色器之间的数据传输。理论上,着色计算可以在任何可编程阶段进行,而每个阶段对应不同的运算频率:
- Vertex Shader:逐pre-tesselation顶点运算。
- Hull Shader:逐surface patch运算。
- Domain Shader:逐post-tesselation顶点运算。
- Geometry Shader:逐图元运算。
- Pixel Shader:逐像素运算。
实际上,大多数着色计算是逐像素进行的。虽然这些通常在pixel shader中实现,但computer shader的使用也越来越多,在第20章会给出一些例子。其他阶段主要用于几何运算,比如transform和变形。为了理解为什么着色计算要逐像素计算,下面我们对比一下逐顶点和逐像素计算的结果。在旧的文本中,也被称为Gouraud shading(参考文献[578])和Phong shading(参考文献[1414]),这些术语现在已经不用了。这个比较中使用的着色模型类似公式5.1,但是经过修改,可以使用多个光源。等我们说完细节之后,会给出完整的模型。
下图5.9可以看出两种顶点密度的模型,分别使用逐顶点着色和逐像素着色的区别。对于龙的那个模型,顶点密度很高,两种着色的差别很小。而对于茶壶,使用顶点着色的话会出现明显的错误,比如高光部分。而对于两个三角形平面来说,顶点着色完全不正确。这些错误的原因是因为着色方程的某些部分,特别是高光部分,在网格表面呈非线性变化。这使得,如果使用顶点着色,以线性插值的方式得到结果的方式,结果是不对的。
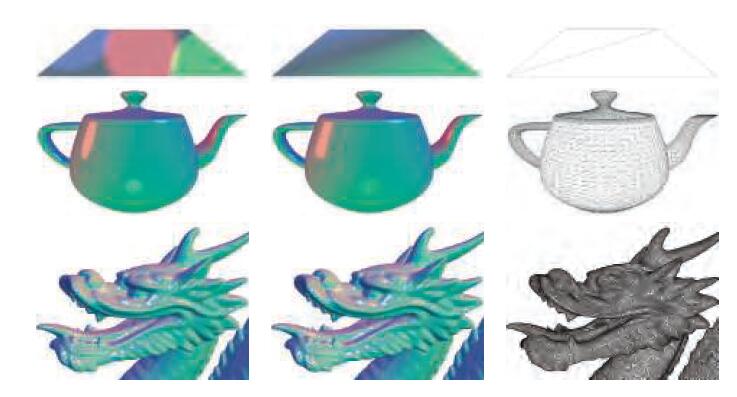
上图为逐顶点和逐像素,以5.19着色模型,针对三种不同顶点密度模型所得到的对比图。左侧为逐像素的结果,中间为逐顶点的结果,右侧为模型的wireframe,可以看到其顶点密度。(中国龙的模型来自Computer Graphics Archive(参考文献[1172]),而原始模型来自Stanford 3D Scanning Repository)
理论上,可以在PS中只计算高光部分,其他部分在VS中进行计算。这样的话效果没区别,性能上理论上还会有所节省。但实际上,这种混合方式往往并非最优解。着色模型中线性变换的部分,往往是计算量最小的部分,以这种方式拆分着色计算,往往会导致更多的开销,比如重复计算以及额外的varying变量,这些消耗甚至可能超过节省的部分。
如前所述,VS主要负责非着色部分,比如几何体transform和变形。将生成的几何曲面属性转换为适当的坐标系,由VS输出,在三角形中线性插值后,作为varying输入传给PS。这些属性通常包括位置、法线以及可选的切线(如果需要做法线映射)
需要注意的是,即使VS中对法线做了归一化处理,但是插值后的向量依然可能是非归一化的。如图5.10所示。所以在PS中还需要对法线进行重新归一化。而VS中的法线归一化依然不可缺少。因为如果顶点之间的法线长度变换很大,比如做顶点混合的时候,这个将会扭曲插值。这可以在图5.10的右侧看到。所以,需要在插值之前和之后,也就是在VS和PS中都进行归一化。
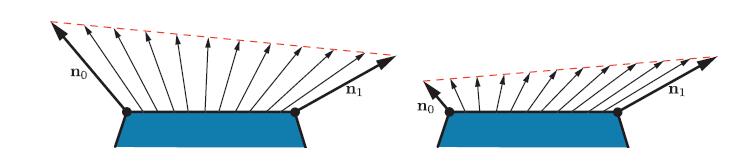
在左侧,我们可以看到,单位法线在曲面上的线性插值会产生长度小于1的插值向量。在右侧,我们看到长度显著不同的法线的线性插值,会导致插值方向向两条法线中较长的方向倾斜。
与法线不同,指向特定位置的向量(比如view向量、精准光源的灯光向量)通常不进行插值。而在PS中通过插值得到的曲面位置来计算这些向量。这些计算中,只有必须在ps中进行的归一化之外,只需要一个向量减法即可,这个计算量很小。如果出于什么原因,比如将这个运算放到VS中,则不要对其进行归一化,否则将会出现不正确的结果,如图5.11所示。
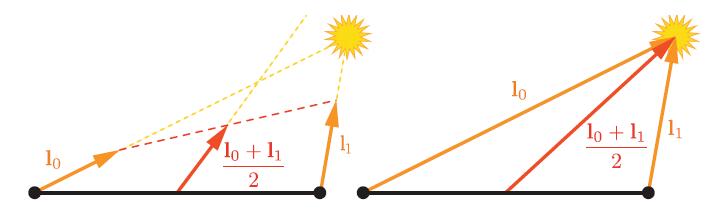
上图为对两个灯光向量进行插值。左图为,在插值之前先归一化,会导致插值后方向错误。右图可以看到,直接对非归一化的向量进行插值,结果是对的。(Patrick:这个挺有意思的)
前面我们提到VS将几何体转换到适当的坐标系中。摄像机和光源的位置由应用程序转换到相同的坐标系中。这样的话,将最大程度降低PS的计算量。但是哪个坐标系是合适的?可能是世界坐标系,也可能是相机的视图坐标系,甚至可能是模型的局部坐标系。具体使用哪个坐标系,通常是基于系统性考虑(比如性能、灵活性和简单性)。比如,如果渲染场景中包含大量灯光,则可以选择世界空间以避免过多的变化灯光位置。或者,可以使用相机坐标系,来更好的优化依赖view向量的PS操作,这样的话精度可能还会得到提高(详见16.6节)
尽管大多数着色器都是按照上述描述的原则,但是凡事均有意外。比如,一些应用程序使用逐图元的渲染以实现风格化的效果。这种风格被称为flat shading。图5.12显示了两个例子。

以上是两个使用flat shading的风格化效果:上面是Kentucky Route Zero,下面是That Dragon,cancer(上图来自Cardboard Computer,下面来自Numinous Games)
理论上,flat shading可以在GS中实现,但是一般都是通过VS实现的。通过将每个图元的属性与其第一个顶点关联,并禁用顶点值插值来完成。禁用插值(可以分别对对每个顶点进行设置)会将第一个顶点的值传给图元中的每个像素。(Patrick:这个厉害了)
5.3.2 例子
下面我们将介绍一个着色模型实例。该实例的着色模型类似5.1公式的扩展Gooch model,但是经过了修改,可以接受多个光源。模型为:
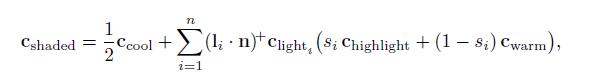
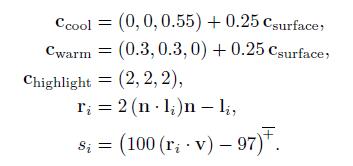
该公式也符合多光源的5.6公式,如下所示
其中光照部分和非光照部分为
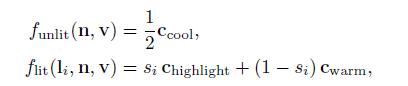
一般情况下,材质属性,比如Csurface的值被存储在顶点数据或者纹理中。但是在这里为了简单,我们假设Csurface是常量。
此实现会使用到shader的动态分支功能来循环所有光源。(Patrick:这个居然是动态分支?)虽然这种方式在简单场景效果不错,但是不能很好的扩展到具有许多光源的大型和几何复杂的场景。第20章将专门介绍处理大量光照的渲染技术。此外,为了简单起见,我们只支持一种光源:点光源。
着色模型并非单独实现,而是要在更大的渲染框架的上下文中才能实现。当前例子是在一个简单的WebGL 2 的应用程序中实现,它是由Tarek Sherif(参考文献[1623])的"Phong-Shaded Cube" WebGL 2模型改编而来,当然,该模型还适用于更复杂的框架中。
下面我们来讨论一些GLSL的shader code以及JavasScript的WebGL API。目的并非是学习WebGL API,而是展示一般的实现原则。我们将按照"由内到外"的顺序实现,先PS,然后VS,最后看图形API调用。
在看shader代码之前,先看下shader的输入和输出。正如3.3节所描述的那样,GLSL的输入分为两类。一类是uniform,由应用程序传入,在一个DC中保持常量。第二类是varying,这些变量可以在VS和PS之间传输。下面是PS中的varying输入,在GLSL中通过in来表示,对应的PS的输出由out表示

该PS只有一个输出,就是最终的颜色。PS的输入与VS的输出相对应,并在光栅化的时候被插值。当前PS有两个varying输入,曲面位置和法线,都是位于世界空间坐标系中。uniform的数量就会多很多,为了简洁期间,我们就展示两个光源相关的uniform

由于这些都是点光源,所以每个点光源的定义都包括位置和颜色。为了符合GLSL std140 data layout数据布局标准,它们被定义成了vec4,而非vec3。这样的话,虽然在std140 layout下会导致浪费一些空间,但是这样的话,就确保了CPU和GPU布局一致,避免了如果布局不一致可能会导致的性能消耗,这就是我们在本实例中使用vec4的原因。(Patrick:这个厉害了,而且UBO在metal和vulkan中布局的不是很好,见下图)。光源的结构数组是由一个uniform block定义,这是glsl的特性,这样就可以将一组uniform变量绑定成一个buffer,这样传输会更快一些。数组长度为光源的最大限制数量。这样的话在shader编译之前,会将shader源代码中的MAXLIGHTS替换成对应的数值(比如10)。而uLightCount这个uniform才是当前DC光源的真正数量。

下面我们来看PS部分

可以看到,有一个lit函数,被main函数调用。总的来说,上述是5.20和5.21两个公式的GLSL实现。注意,Funlit()和Cwarm是作为uniform常量被传入,因为在整个DC中,它们都保持常量,这样的话通过应用程序计算,可以节省一些GPU运算。
这个PS中使用到了一些内置的GLSL函数。reflect函数将一个向量(在这里是光照向量)根据另外一个向量表示的平面(在这里是表面法线)进行反射。由于我们希望光向量和反射向量都指向远离曲面的地方,所以在其传递到reflect函数之前,对前者取反。clamp函数有三个输入,其中两个定义了第三个变量将被clamp的范围。在大多数GPU中,当clamp到0到1之间内,都有对应的函数(比如hlsl中的saturate),这样的话可以快速处理,且基本是无消耗的,免费的。这也就是为什么我们在这里使用clamp的原因(虽然我们只需要将其clamp到0即可,我们知道它不会超过1)。函数mix有三个输入,将在其中两个输入之间进行线性插值,在本例中是对warm颜色和highlight高光颜色,基于第三个参数(范围0-1)进行线性插值。在HLSL中这个函数是lerp,用于线性插值。最后,normalize是用于归一化,实现方式就是将向量除以向量长度。
下面来看下VS。由于上面已经介绍了不少uniform,这里就不再赘述了。这里看下varying的输入和输出的定义

正如前面所提到的那样,VS的输出与PS的varying输入相匹配。而VS的输入包含了数据在顶点数组中布局的指令。下面是VS的代码:

这些都是VS中的一些常见操作。shader中先将位置和法线转换到世界空间,然后将其传给PS着色使用。然后,顶点位置被转换到clip空间,赋给了gl_Position,这是光栅化使用的一个特殊的内置变量。gl_Position是VS中必须有的一个输出变量。
另外,可以看到在VS中并没有对法线进行归一化。因为在原始mesh中存储的法线长度本身就为1,而在VS中并没有对其进行比如顶点混合、不均匀缩放等会改变其长度的操作。模型矩阵中有缩放因子可能会改变法线长度,但是是统一的改变所有法线的长度,所以不会出现5.10右侧图片导致的问题。
此例子中的应用程序使用WebGL的API进行渲染和着色设置。其中每个shader都会独立被设置,然后绑定到一个program object上。下面是PS的构建代码:

这里使用到了fragment shader。这个属于被WebGL(和它所基于的OpenGL)所使用。正如本书前面提到的,尽管Pixel shader不太精确,但是使用面积比较广,所以本书使用这个术语。此代码中也用于将MAXLIGHTS 字符串替换成适当的数值。大多数渲染引擎都会执行类似预编译的着色操作。
应用程序还会执行更多的操作,比如设置uniform,初始化顶点数组,clear、draw等,这些都可以在program(参考文献[1623])中查看这些代码,有很多的API指南会去解释这些代码。我们这里的目标是解释shader是如何在它们的编程环境中被当做一个个单独的处理单元。因此,我们的演练到此结束。
5.3.3 材质系统
很少有渲染框架只实现一个shader的。通常,都需要一个专门的系统来处理应用程序所使用的各种材质、着色模型和shader。
正如前面所说,shader适用于GPU可编程着色。因此,它是一个底层的图形API资源,而不是艺术家直接交互的东西。相对应的,艺术家一般直接操作材质球。虽然材质球有时候还会描述一些非视觉方面的属性,比如碰撞等(Patrick:材质球还可以干这个事情?),但是本书中我们不对这一块进行讨论。
虽然材质球是通过shader实现的,但并非一一对应关系。在不同的渲染情况下,同一个材质可能使用不同的shader,而同一个shader也可以被多个材质球共享。最常见的情况就是参数化材质球。通常情况下,参数化材质球需要两种类型的材质:材质模板和材质实例。每个材质模板描述一类材质,并具有一组参数,这些参数可以根据参数类型指定数值、颜色、纹理等。每个材质实例对应一个材质模板以及一套默认值。一些渲染框架,比如UE(参考文献[1802])包含一套更复杂的层次结构,其中材质模板可以从多个级别的其他模板中派生。
参数可以通过uniform在运行时传入shader,也可以在编译前通过替换值的方式传入shader(Patrick:不知道Unity是替换的,还是通过uniform的,但无论是哪个,其实都是静态分支吧)。常见的编译时参数是布尔开关,用它来控制材质球中使用哪个分支。可以通过材质球中的UI界面设置,也可以由程序直接控制。比如,可以在视觉效果可以忽略不计的情况下,降低远处对象的着色运算量。
虽然材质参数可以与着色模型的参数一一对应,但是情况往往并非如此。比如可以将给定着色模型的某个参数(比如表面颜色)设置成常量值,这样将减少一个材质参数。相应的,着色模型的参数也可能会需要通过一系列复杂的操作来计算得到,这些操作以多个材质参数,比如插值得到的顶点参数或者纹理作为输入。而在某些情况下,比如表面位置、法线方向甚至时间等都会影响到着色计算。基于表面位置和法线方向的着色在地形材质中尤为常见。比如基于高度和法线可以用于控制雪的效果,在高海拔和几乎水平的表面混合白色的表面颜色。基于时间的着色在动画材质中很常见,比如闪烁的霓虹灯标志。
材质系统最重要的任务之一是将各种材质球函数划分为单独的元素,并控制这些元素的组合方式。在许多情况下,这种类型的组合是有用的,比如:
- 组合表面着色和几何处理,比如刚体变换、顶点混合、morphing变形、表面细分、instancing、clip等。这些功能各不相同:表面着色取决于材质,几何处理取决于网络。因此,可以将它们分开编写,然后由材质系统组合。
- 组合表面着色和合成操作,比如alpha test、alpha blend。这与移动GPU尤其相关,后者通常在PS中执行。通常需要将这些操作独立于表面着色所使用的材质。
- 组合着色模型和得到着色模型参数的计算。这样的话,就可以只实现着色模型一次,然后与各种计算着色模型参数的方法结合使用。
- 组合分支和shader的其他部分。这样可以将每个feature都独立实例。
- 组合光照模型和根据光源得到其参数的计算:针对每个光源计算当前片元的Clight和L。延迟渲染(详见20章)等技术改变了这个结构。支持多种类似技术的渲染框架的复杂度更高了。
如果图形API提供这种类型的着色程序代码模块作为核心功能,将会非常方便。但是遗憾的是,与CPU不同,GPU shader不允许代码片段编译后链接。每个program都会被编译成一个单元。着色器阶段的分离可以实现一些有限的模块化,但这只是我们上面列表中的第一条:表面着色(通常在PS中执行)组合几何处理(通常在其他shader中执行)。但是由于每个材质球还需要执行其他操作,所以这样并不完美。考虑到这些限制,材质系统实现所有这些类型组合的唯一方法就是在源码级别。这里主要将设计字符串操作,比如连接和替代,通常通过C样式的预处理指令执行,比如include、if、define。
早期的渲染系统中shader变体很少,基本都是全部手写的。这样的好处是,可以根据每个shader的特点来优化每个变量。但是随着变体数量的增加,这种方法很快变的不切实际。当考虑到所有不同的部分和选项的时候,变体的数量是巨大的。这也就是为什么模块化和可组合型如此重要。
在设计处理shader变体的系统的时候,第一个要解决的问题是:是选择在运行时通过动态分支,还是在编译时通过条件预处理进行分支选择。在旧的硬件上,动态分支特别慢,基本不可能,所以不会选择动态分支。(Patrick:加入一个wave对应64个thread,有动态分支的时候,会有32个thread走其中一个分支,另外一个thread走另外一个分支。wave和thread的概念见下图)所有的变量将在编译时处理,甚至是不同类型不同数量的光(参考文献[1193])。
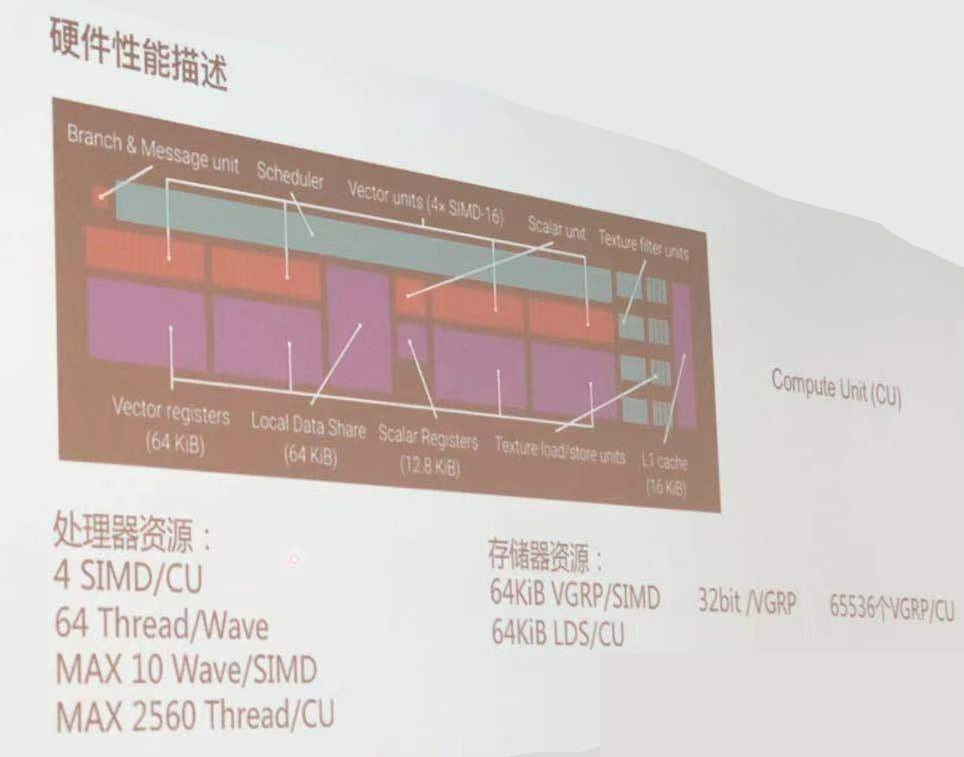




相比之下,当前GPU可以很好的处理动态分支,尤其在当前DC下,针对所有像素都使用相同分支的时候。所以现在,比如灯的数量,都是在运行时处理的。(Patrick:灯的数量不是uniform么,这个不是常量是静态分支么?静态分支和直接替换shader源代码还不一样?)但是,向shader中添加大量的变量也会产生其他的一些成本:寄存器计数增加,占用率相应降低,从而降低性能。有关更多详细信息,详见18.4.5。因此编译时变量仍然有用,因为它可以避免一些永远不会执行到的复杂逻辑。
举个例子,假如一个应用程序中支持三种不同类型的灯。其中两种很简单:点光源和方向光。第三种类型是通用聚光灯,它支持表格照明模式和其他复杂功能,需要大量的代码实现。但是很少使用聚光灯。在过去,会根据这三种灯光的类型和计数做出各种排列组合编译不同的shader变体,以避免动态分支。虽然现在不这样做了,但是还是可以拆成两个变体,一个适用于有聚光灯的时候,另外一个适用于没有聚光灯的时候。这样第二种变体的代码比较简单,就可以得到更低的寄存器占用率,得到更高的性能。(Patrick:所以使用uniform的静态分支和shader源代码替换的唯一区别就是:使用uniform的话,某个分支虽然永远不走,但是其中用到的变量还是需要占用寄存器的。)
现代的材质系统同时使用运行时和编译时shader变体。虽然整个负担不再只在编译时处理,但是总体的复杂性和变化的数量在不断增加。因此,仍需要编译大量的shader变体。比如,在Destiny中:The Taken King中一帧中会超过9000个已编译的着色变体(参考文献[1750])。Unity中由接近1000亿个可能出现的变体。即使是只编译实际使用的变体,但依然要重新设计shader编译系统,来处理大量可能的变体(参考文献[1439])
材质系统设计师采样不同的策略来解决这些问题。尽管这些策略有时会互斥(参考文献[342]),但这些策略依然经常会在一个系统中被结合起来使用。这些策略包括:
- 代码重用,在共享文件中实现函数,使用#include预处理指令,从任何需要它们的shader中访问这些函数。
- Subtractive,一个被经常成为uber shader或者super shader的shader(参考文献[1170,1784])。使用编译器预处理条件和动态分支的组合来删除未使用的部分,并在互斥的分支之间切换,从而实现了大量的功能。
- Additive。各种功能被定义为具有输入和输出连接器的节点,这些连接点可以被组合在一起。这个类似于代码重用策略,但更加结构化。节点的组合可以通过文本(参考文献[342])或可视化图形编辑器完成。后者旨在使非工程师(比如TA)更容易创造新的材质模板(参考文献[1750,1802]),而通常只有部分着色可以访问可视化图形创作。例如,在UE4中,蓝图编辑器只能用于操作着色模型输入的计算(参考文献[1802])(Patrick:真的诶。。UE4怎么改着色/光照模型呢。)。如下图5.13
- Template-based。定义一个借口,然后将不同的实现插入其中。这比加法策略更正式,通常用于更大的功能块。这种方式最常见的例子,就是将着色模型参数的计算与着色模型本身的计算进行分离。UE(参考文献[1802])有两个材质domain,一个用于计算着色模型输入参数的,一个用于计算光源的Clight的(Patrick:这个我貌似没注意到过。)需要注意的是,延迟着色(详见20章)强制执行类似的代码,其中G-buffer为接口。
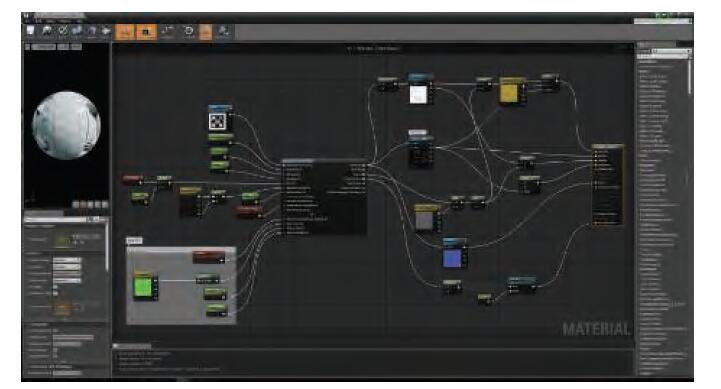
上图为UE的材质编辑器。注意看到右侧的节点,此节点的输入连接器对应于渲染引擎使用的各种着色输入,包括所有着色模型参数。(材质样本由Epic Game提供)
在WebGL Insights(参考文献[301])一书中的几章讨论了各种引擎如何控制器shader管线(Patrick:Shader管线是什么,好吧,应该就是管线,从应用程序传入数据阶段到depth/stencil test、dither等结束)。除此之外,现代材质系统还有一些其他重要的设计考虑,比如使用最少的代码支持多平台。这些不同包括不同平台性能上、功能上甚至语言上的不同。Destiny系统(参考文献[1750])就用来解决这种问题的典型解决方案。它使用一个专门的预处理层,这层接受自定义着色语言编写的shader。这样的话,就可以编写平台无关的shader,然后自动转成不同的shader和实现了。UE(参考文献[1802])和Unity(参考文献[1436])都有类似的系统。
材质系统也需要确保良好的性能。除了shader变体之外,还有一些其他优化。Destiny系统和UE都会自动检测当前DC那些参数可以被看成常量(比如前面实例中的冷暖计算),并将其移除shader。(Patrick:不知道Unity会不会这么做,这样的话会省寄存器吧)。还有就是,Destiny会判断更新频率(比如每帧、每个光照、逐物件),然后再适当的时候更新每组常量,以减少API开销。(Patrick:这就是SRPBatcher吧)
所以,实现一个shader是一个决定哪部分可以简化,计算各种表达式频率以及用户如何修改和控制外观的问题。shader管线的最终输出是颜色和blend信息。下面的AA、透明度、图像处理将说明如何组合和修改这些值,以显示到屏幕上。
5.4 抗锯齿
想象一下,一个大的黑色三角形在一个白色的背景板上缓慢的移动。可以认为屏幕上的一个像素被三角形部分覆盖,而在移动的过程中,该像素的强度应该是平滑的发生变化。但是,基本上在所有类型的渲染器中,实际上情况是,当像素的中心被覆盖的时候,像素颜色直接从白色变成黑色。即使是最标准的GPU渲染也不例外。参见图5.14最左列。

上面的三张图片,显示了针对同一个三角形、线段、点采用不同级别抗锯齿的效果。下面一行是上面一行的放大图片。最左边的一列针对每个像素只使用了一个样本,这意味着不使用抗锯齿。中间的一列针对每个像素使用了四个样本,而最右边的一列针对每个像素使用了八个样本(在一个4*4的格子中,采取一半的数据)
三角形会以像素的形式展示,而像素只有两种可能性,要么在那里,要么不在那里。绘制的线条也有类似的问题。因此,边缘会有锯齿状的外观,这种视觉效果被称为“锯齿”,而动起来的时候,看起来像是像素在流动/爬行(Patrick:其实就是摩尔纹)。更正式的说法,这个问题被称为走样,而避免这个效果被称为反走样。
采样理论和数字滤波是一个很大的主题,大到可以填满一整本书(参考文献[559、1447、1729])。这是渲染行业的一个关键领域,所以我们在这里也会介绍一些采样和数字滤波的一些基本理论。我们将重点放在实时反走样技术。
5.4.1 采样和数字滤波理论
渲染图像本质上是一个采样的过程。这是因为图像的生成就是对三维场景进行采样以获得图像中每个像素(一组离散的像素数组)的颜色值的过程。如果使用纹理映射(详见第6章),就需要对纹素进行重新采样,以在不同条件下获得良好的效果。针对序列帧动画,通常以相同的时间间隔进行采样。本节介绍采样、重建和过滤的相关主题。为了简单起见,大多数材料都将使用一维方式进行呈现。当然这些概念同样适用于二维图片。
下图5.15展示了如何以均匀间隔(即离散化)对连续信号进行采样。这个抽样过程的目的是以数字方式表达信息,这样做可以减少信息量。但是需要对采样信号进行重构以恢复原始信号,这是通过过滤采样信号来实现的。(Patrick:这个蛮有意思的)
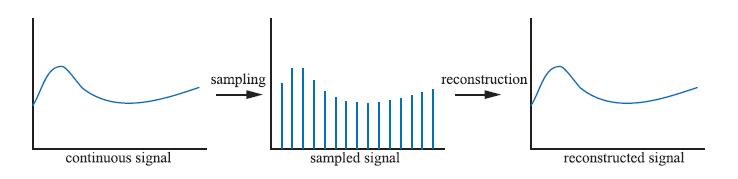
上图为对连续信号(左)进行采样(中),然后通过重构(右)恢复原始信号。(Patrick:所以我在想,针对贴图的滤波方式,如果开启mipmap的话,其实只要用point就好了吧,因为理论上这个贴图的尺寸和屏幕上的像素数是一一对应的,当然用Bilinear效果更好,而且因为texture cache的原因,性能也ok,Trilinear应该就没必要了,性能也会有问题。)
采样后,可能会出现走样,为了消除这个效果,我们就需要进行反走样来生成效果更好的图像。在旧的西部片中,一个典型的走样的例子是由相机拍摄的旋转的马车轮。由于轮子的转速比摄像机记录的频率高,所以马车轮可能看起来旋转的非常慢(甚至有时向前有时向后),甚至可能看上去根本不像旋转。如下图5.16所示,这种效果的产生是因为车轮的图像是以一系列的时间戳拍摄的,可以被称为时间走样。
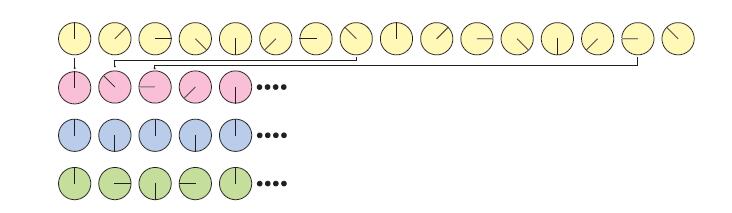
最上面一行显示了一个旋转轮(原始信号)。而在第二行中,对其采样频率不够,导致看上去像是在向相反的方向移动。这样是由于采样率太低而导致的走样实例。而在第三排中,采样率的问题,导致完全不发确定车轮的旋转方向。这就是Nyquist极限。在第四排中,采样率高于前面两排,这样可以看到车轮正在朝着正确的方向旋转。
计算机图形学中最常见的走样的例子是由于以下三种情况产生的"锯齿":光栅化线段或者三角形的边缘,闪烁的高光,被压缩的具有棋盘格图案的纹理(详见6.2.2)(Patrick:后面这两种情况是什么)
当信号采样频率过低时,就会出现走样。如图5.17,为了正确采样(通过采样数据重建原始信号),采样频率必须是原始信号最大频率的两倍以上。这通常被称为采样定律,对应的采样频率被称为Nyquist rate(参考文献[1447])或者Nyquist极限,由瑞典科学家Harry Nyquist(1889-1976)提出。如图5.16也可以看出Nyquist极限。定律中使用了最大频率这一术语,代表着原始信号的最大频率。换句话说,相邻样本之间必须足够平滑。
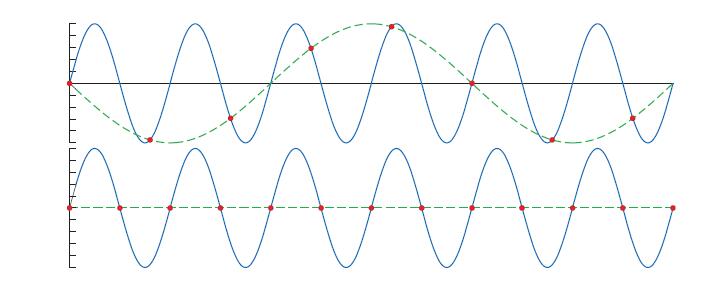
上图中蓝色实线为原始信号,红色圆圈为均匀间隔的采样点,绿色虚线为重构信号。上面一行的采样率过低,因此重构的信号频率会比较低,发生了走样。而下面一行的采样率刚好是原始信号频率的两倍,重建的信号在这里是一条水平线。可以看出来,如果采样率稍微增加,完全可能重建原始信号。
然而3D场景基本不会出现band-limited。三角形的边缘,阴影的边缘以及其他一些现象都可能会出现不连续变化的信号,从而产生无限的频率(参考文献[252])。所以,无论采样点多密,依然可能会由于重要信息比较小,导致采样不对。因此,使用点采样去渲染场景的时候,不可能完全避免走样,虽然我们基本都是使用点采样。然而,有时可能知道信号是否是band-limited。比如采样一个纹理应用到物件表面上。相对于像素的采样率,可以计算出纹理的采样率。如果低于Nyquist极限,则不需要特殊操作,如果过高,则需要使用各种算法(详见6.2.2)(Patrick:应该就是当没有mipmap的时候,如果纹理过大,所占屏幕面积过小,则需要用bilinear等过滤算法)
Reconstruction重建
下面我们将讨论,针对band-limited信号,如何从采样信号中重构原始信号。为此,必须使用滤波器。图5.18中显示了三种常见的滤波器。需要注意的是,滤波器的面积应该始终为1,否则重建的信号可能会增大或缩小。
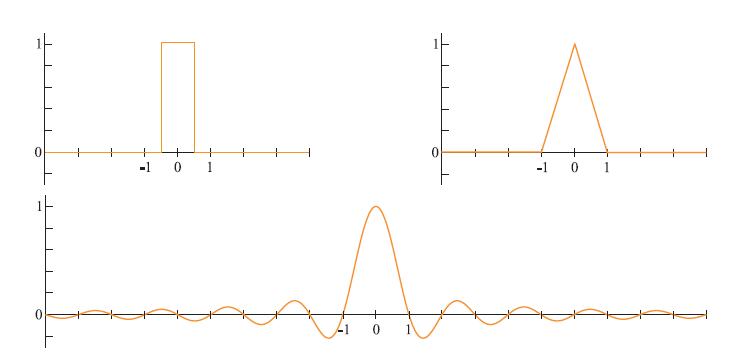
左上角的图为box滤波器,右上角的图为tent滤波器,下图为sinc滤波器(被clamp到X轴上)
如图5.19所示,box滤波器使用最近点用于重建信号。这是最糟糕的选择,因为这样的话还原的信号是不连续的阶梯。尽管如此,由于它很简单,所以经常被用于计算机图形学。如图所示,box滤波器将被放置在每个采样点上,然后进行缩放,使得滤波器最顶端与采样点重合。之后,这些被缩放后的框组合在一起,就得到了右侧所显示的重建信号
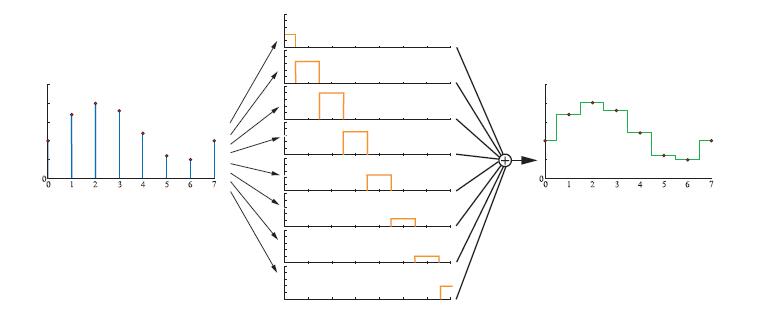
如上图所示,左侧的采样信号通过box滤波器重建。将滤波器放置在每个采样点上,然后沿着Y方向缩放,使得滤波器的高度和采样点相同。有图为重建的信号。
box滤波器可以被其他任何滤波器取代。如图5.20所示,tent滤波器,也被称为三角形滤波器。该滤波器针对相邻采样点之间进行线性插值,因此比box滤波器更好,因为重建的信号是连续的。
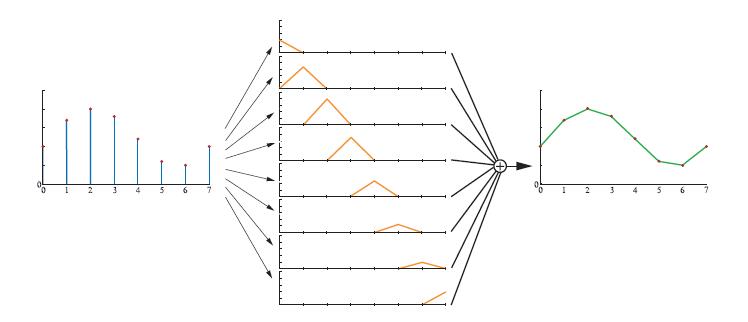
采样信号被tent滤波器重建,右侧为重建后的信号。
然而,tent滤波器重建信号的平滑度比较差,采样点会有比较突然的坡度变化。为了得到完美的重建,必须使用理想的低通滤波器。信号的频率分量是正弦波:sin(2πf),其中f为该分量的频率。(Patrick:这句话没看懂,应该是:重建信号为正弦波,f为频率?)。低通滤波器会去除频率高于滤波器定义的某个频率的所有频率。直观的说,低通滤波器去除了信号的尖锐部分,对信号进行了blur。理想的低通滤波器是sinc滤波器,也就是图5.18的底部。
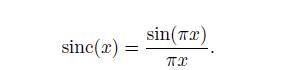
傅里叶分析(参考文献[1447])解释了为什么sinc滤波器是最理想的低通滤波器。因为,在频域空间,低通滤波器是一个box滤波器,当其与信号相乘时,会出去滤波器宽度以上的所有频率。然后将box滤波器从频域转为空间域,就得到了正弦函数。同时,乘法运算被转换成了卷积函数,这个属于虽然我们没有描述,但是在本节中将一直使用。
如图所示,使用sinc滤波器重建信号可获得更平滑的结果。如图5.21所示,采样信号引入信号中的高频分量(突变),低通滤波器的任务是去除这些分量。实际上,sinc滤波器过滤掉了所有频率高于采样率/2的正弦波。如公式5.22所示,当采样频率为1.0(采样信号的最大频率必须小于1/2)的时候,sinc函数是最完美的重构滤波器。一般来说,假设采样频率为fs,即相邻样本之间的间隔为1/fs。对于这种情况,完美的重构滤波器为sinc(fsx),它消除了所有频率高于fs/2的频率。这个在重采样中很有用(详见下一节)。然而,由于sinc滤波器的宽度是无限的,而且在某些领域是负的,所以在实际应用中很少有用。(Patrick:这里挺复杂的)
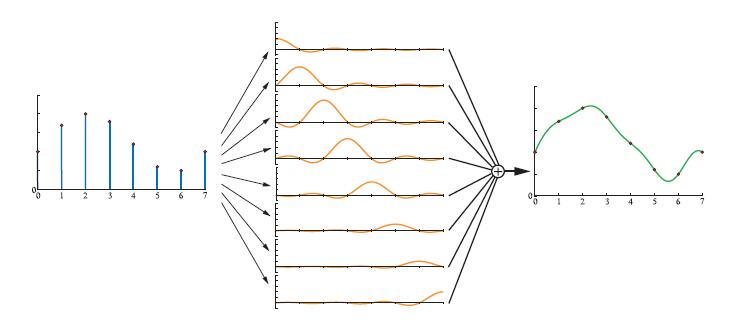
上图为使用sinc滤波器去重建信号,sinc滤波器是最理想的低通滤波器。
一方面是质量比较低的box和tent滤波器,一方面是不实用的sinc滤波器,我们需要在两者之间取一个中间值。最广泛使用的滤波器(参考文献[1214、1289、1413、1793])介于这两者之间。所有的这些滤波器都余sinc函数类似,但是又都有所限制。最接近sinc函数的滤波器在部分区域会出现负值,然而负值通常是不需要的,所以通常使用一些没有负值产生的滤波器(通常被称为高斯滤波器,因为它们要么来自高斯曲线,要么类似高斯曲线)。第12.1节更详细的讨论了滤波器的函数和使用。
使用了任何滤波器后,都会得到一个连续的信号,然而在CG领域,不能直接显示连续信号,但可以使用它们将连续信号重新采样到其它尺寸,即放大或者缩小信息。接下来讨论这个问题
Resampling重采样
重采样是用于缩放采样信号。假设原始采样点位于整数坐标,即采样点之间有单位间隔。假如重采样后,希望新的采样点间隔为a。当a>1为缩小(降采样),a<1为放大(升采样)
两者中比较简单的是升采样,所以我们先聊升采样。假如采样信号如前一节所示被重构,得到一个连续的重构信号,那么现在要做的就是以期待的间隔对重构信号进行重新采样。这个过程如图5.22所示
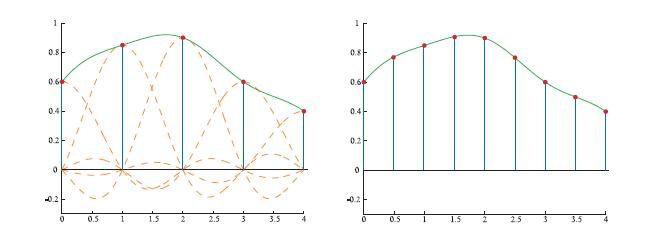
左侧为采样信号和重构信号,右侧为以两倍的频率重采样重构信号,也就是放大。
但是这个技术并不适用于降采样,否则将无法避免走样,所以需要使用sinc的滤波器从采样信号中创建连续信号(参考文献[1447、1661])。这样就可以按照所需要的间隔进行重新采样了。如图5.23所示。这样,增加低通滤波的宽度,将重采样的频率降低到原来的一半,除去了更多高频信息。这种方式,类似于先模糊(去除高频信息),然后以较低分辨率重新采样图像。
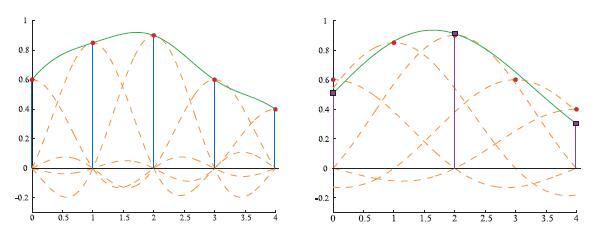
左侧为采样信号和重构信号,右侧为宽度为原来两倍的滤波器,这样的话,就是降采样
下面,将以采样和滤波理论为框架,讨论实时渲染中反走样的各种算法。
5.4.2 屏幕空间反走样
(Patrick:这里会涉及FSAA、SSAA、MSAA、CSAA、EQAA、CFAA、TXAA、MFAA、TAA、HRAA、SMAA、FXAA、MLAA、SRAA、GPAA、GBAA、DEAA、DLAA,一波把AA说明白。这里参考阅读了ACM SIGGRAPH 2011 Course、KlayGE游戏引擎以及《Gpu Gems》《Gpu Pro》《Gpu Zen》系列读书笔记)当没有很好的采样和滤波的时候,三角形的边缘就会出现明显的走样现象。阴影边界、高光或者其他颜色快速变化的地方都可能会出现类似的问题。本节的算法有助于提高这些情况的渲染质量。它们都是针对屏幕进行处理,也就是仅对渲染管线的输出进行处理。没有一种AA算法是完美的,每种技术在质量、捕捉尖锐细节、移动物件、内存消耗、GPU消耗等方面都各有不同的优化和劣势。
在图5.13中的黑色三角形示例中,其中一个问题是采样率低。如果在每个像素的网格单元中心处取一个样本,只能知道该中心点是否会被三角形覆盖。而如果在网格单元中通过更多的采样点进行采样,并以某种方式混合这些样本,就可以计算出更好的像素颜色,如图5.24所示。
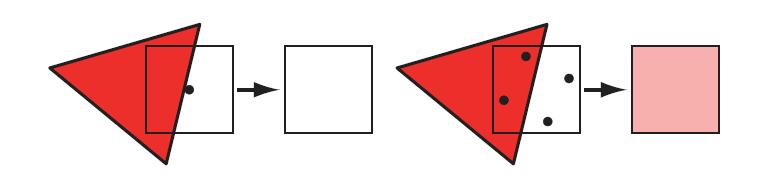
如上图所示,通过一个位于像素中心的采样点,采样一个红色三角形,由于三角形无法覆盖样本,所以即使大部分像素被红色覆盖,但依然认为是白色。而在右边,针对每个像素使用四个样本,可以看到其中两个样本被红色三角形覆盖,所以像素颜色会被认为是粉红色。
基于屏幕的抗锯齿方案,一般是使用一定的采样模式对屏幕上的信息进行采样,然后通过加权和的方式计算出该像素的颜色值p:
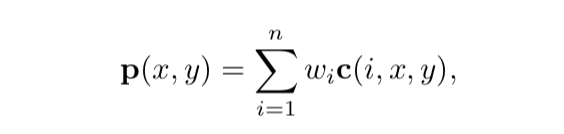
其中n为在采样模式中定义好的,像素采样的样本数。函数C(i,x,y)为一个样本颜色,Wi是一个权重,范围在[0,1],所有样本的数据共同用于计算出该像素的颜色。每个采样样本点的位置是根据其在序列1,2,..,n中的位置计算出来的,也可以基于像素位置(x,y)的整数部分。换句话说,每次采样在屏幕网格中的位置都不同,并且每个像素所使用的采样模式都可以不同。实时渲染(以及大多数其他渲染系统)中的采样一般采用点采样。因此,可以把函数c看作是两个函数。首先,函数f(i,n)定位屏幕中采样样本所在的浮点位置(xf,yf),然后对屏幕上的该位置进行采样,获取到该精确点的颜色。关于采样模式的选择,以及采样的时候是对像素中的哪个位置进行采样(中心点还是其它地方还是点采样等),一般是逐帧(或逐应用程序)进行设置。
(Patrick:对普通纹理的采样一般是点采样,最多会使用不同的filtermode,比如bilinear等,而对shadowmap的采样,一般会自带一次filter,具体要看第7章shadow部分。)反走样公式中的另外一个变量Wi,是每个采样样本的权重值。这些值的和为1。实时渲染中使用的大部分采样模式中,会对每个样本赋予相同的权重值,即Wi = 1/n。图形硬件中的默认模式为点采样,也就是针对像素的中心点进行采样,是上面抗锯齿公式中最简单的一种情况,也就是只有一个样本,该样本的权重为1,采样函数也就总是返回被采样像素中心点的数值。
针对每个像素计算一个以上完整采样的抗锯齿算法,被称为超级采样supersampling(或者过采样oversampling)。其中最简单的就是full-scene antialiasing(FSAA),也被称为supersampling antialiasing(SSAA),方法就是先以更高的分辨率渲染场景,然后针对相邻采样点通过过滤算法计算得到最终的图像。举个例子,比如需要一张1280*1024的图片,那么先在offscene绘制一张2560*2048的图片,然后对每个2*2的区域取平均数显示到屏幕上,本质上就是使用box滤波器针对每个像素使用四个样本生成所需要的图像。也就是图5-25中的2*2网格采样。这种方法成本高昂,因为所有的样本都需要完全着色和填充,每个样本都还需要一个对应的z-buffer。FSAA的主要特点就是简单。该方法还有低配版本,也就是仅在一个屏幕轴上进行两倍采样,也可以被称为1*2或者2*1的超采样。通常为了简单起见,会使用power of 2的分辨率以及box过滤器。NVIDIA的dynamic super resolution(DSR)特性是一种更精细的超采样形式,其中场景以更高的分辨率渲染,并使用13个样本采样点的高斯滤波器生成显示图像(参考文献[1848])
(Patrick:这个方法基本没啥意义,FSAA在绘制的时候会产生大约4倍的GPU消耗,再加上映射到屏幕时的过滤算法,还不如直接绘制一个高分辨率的图片显示到屏幕上,只有在GPU过剩的时候才有意义。网上有一篇针对NV DSR特性的测评:1080p一秒变4K?NVIDIA全新DSR技术实测-太平洋电脑网。总的来说,可以通过设置分辨率的大小和过滤算法,达到抗锯齿的效果,但是由于过滤的原因,画面会变得柔,且会丢失一些细节。但是帧率会大幅度降低,性能还不如直接使用高分辨率模式。且对于游戏内的UI没有进行等比例缩放的游戏来说,会发现字太小,根本看不清楚,这个问题是致命的。)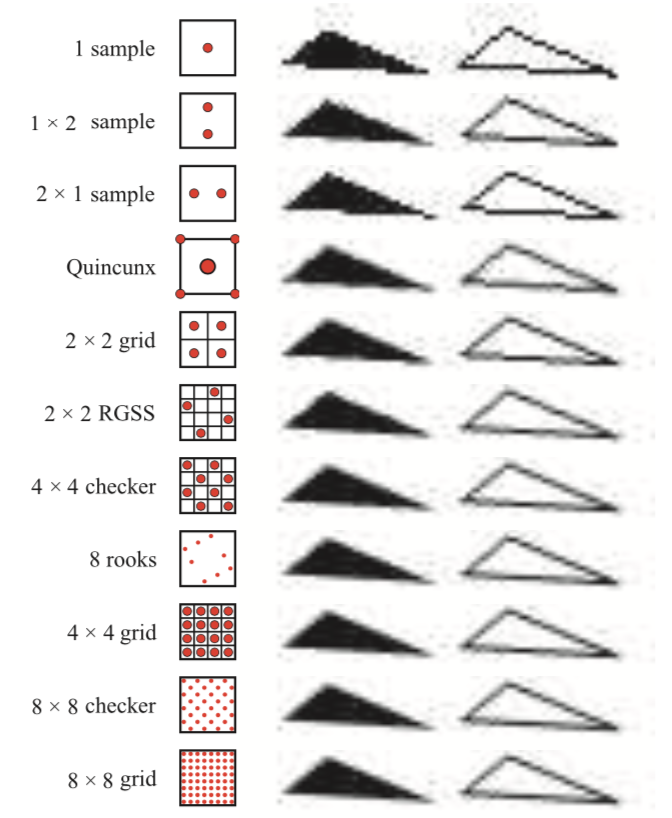
上图为一些采样模式的比较,以每个像素对应样本数从少到多的顺序进行排列。Quincunx中的所用采样都使用的是中心样本点,5次采样中最中心那次采样的权重为1/2。2*2 rotated guid RGSS采样会比2*2grid更好的处理近似水平边缘的锯齿。同样的,尽管8 rooks模式比4*4grid使用的样本少,但能更好的处理近似水平边缘的锯齿。
有一个与supersampling相关的采样方法,是基于accumulation buffer(参考文献[637,1115])。此方法使用与所需图像相同分辨率,但是每个通道具有更多颜色位的buffer。为了获取场景的2*2采样,需要根据需要在屏幕x或者y方向移动半个像素,以生成四个图像。生成的每个图像基于网格单元内的不同采样位置。这样的话,每帧必需重新渲染场景几次,并将结果复制到屏幕上。这种算法对于实时渲染来说成本也很高昂,只能说对于不在意性能,只追求更高质量图像的时候非常有用,因为可以在每个像素的任意位置放置任意数量的样本采样点(参考文献[1679])。accumulation buffer过去是一个单独的硬件,OpenGL API直接支持它,但是在3.0版本中开始抛弃该机制。在现代GPU中,可以通过对输出buffer设置更高精度的颜色格式,在PS中实现accumulation buffer的这种机制。
(Patrick:这种算法比FSAA性能上稍微好一点。 相同点: 1.color buffer其实大小一样,一块2*2尺寸的buffer,与一块1*1尺寸的高精度buffer的尺寸完全一样。 2.最终还是需要通过滤波器根据多个点生成最终像素。 优势: 1.Z-buffer不再需要一块大尺寸buffer。 2.在渲染的时候PS中需要根据四个点进行计算,可以有效的进行合并算法。 3.渲染的时候若干点的位置可以随意,不用像FSAA那样间隔必需完全一样,这样就可以实现图5-25中RGSS、rooks、checker的采样模式了。)supersampling超采样以及accumulation buffering之类的技术是通过完整计算的着色和深度得到的样本值。由于每个采样样本都必须通过PS计算,这种方式整体增益比较低,消耗还比较高。
Multisampling antialiasing(MSAA)针对每个像素只会计算一次表面着色,并在样本之间共享该结果,这样可以减少高计算成本。像素可以为每个片元提供4个(x,y)采样位置,每个位置都有自己的颜色和z深度,但是对于应用于该像素的片元计算,PS只会计算一次。如果该片元覆盖了MSAA中所有的采样样本的位置,则在像素中心点进行采样。如果片元覆盖的采样样本点比较少,则可以移动采样的位置,以更好的表示覆盖的位置。举个例子,这样的话就可以避免超出纹理边缘的采样了。这种位置调整被称为质心采样或者质心插值,如果启动的话,是由GPU自动完成的。质心采样可以避免采样超出三角形范围的问题,但是会导致导数计算返回错误值(参考文献[530,1041])。参照图5.26。
MSAA比supersampling快,因为其PS只会执行一次。它根据片元所覆盖的采样点位置,得到最终采样点位置,并对该点进行采样,然后在所有覆盖的采样点位置中共享计算结果。还可以根据进一步的分离sampling和coverage,使用更少的内存,更快的渲染,进一步提升抗锯齿的速度。NVIDIA在2006年引入了coverage sampling antialiasing(CSAA),随后AMD引入了enhanced quality antialiasing(EQAA)。这些技术的原理是只保存部分采样信息。比如,EQAA的2f4x模式,只保存2个颜色和深度信息,将这2个信息用于4个采样位置。颜色和深度信息不再保存在特定的位置,而是保存在一个表格中。然后四个采样位置只需要一个位来制定其与表格中的哪个信息关联。如果超过了存储的颜色数,则会删除一个已经存储的数据,并将其对应的样本标记为未知。未知的样本不会用于计算最终的颜色(参考文献[382,383])。对于大多数场景,很少有一个像素中包含三个或者更多个颜色完全不同的可见不透明片元,所以该方案在实践中表现还不错(参考文献[1405])。然而,为了获取更高的质量,游戏Forza Horizon 2依然采用4xMSAA,尽管EQAA的性能更好(参考文献[1002])
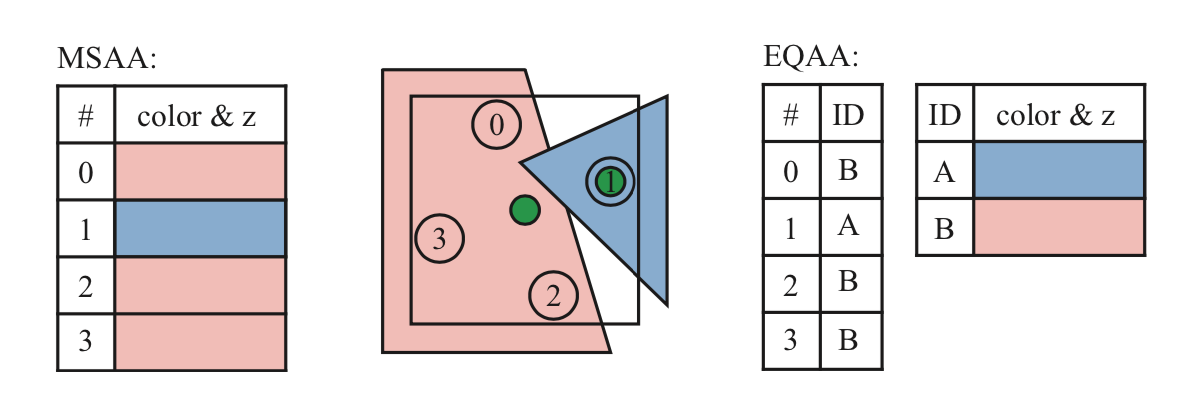
上图中,中间一个图表示有一个像素,会被两个物件覆盖。其中红色的物件会覆盖3个采样位置,蓝色的会覆盖一个。PS的求值位置显示为绿色。由于红色三角形覆盖像素的中心,因此该位置用于着色器求值。蓝色对象的PS在采样位置1的地方进行PS求值。对于MSAA,所有四个位置存储单独的颜色和深度。右侧显示EQAA的2f4x模式。其中4个采样点有4个ID数,对应了包含2个颜色和深度信息的表格。
(Patrick:这里有点复杂。用我自己的话描述一下。 针对MSAA,会有一个4倍大小的buffer,当绘制蓝色三角形的时候,发现片元只覆盖了像素的采样点1的位置,没有覆盖像素的中心点,所以,则在采样点1的位置进行蓝色三角形的PS计算,并保存在MSAA对应的一个buffer 1中。当绘制红色三角形的时候,发现片元覆盖了像素的中心点以及三个采样点,则在像素中心点位置进行红色三角形的PS计算,并保存在MSAA对应的另外三个buffer 0,2,3中。最后这个4倍MSAA的buffer要经过resolve变成普通的buffer。 针对2f4x的EQAA,会有一个2倍大小的buffer和一个两位的标记位对照表,当绘制蓝色三角形的时候,会把采样点1位置的PS计算后的结果,保存在表格中A位置,然后给采样点1的标记位设置为A。然后绘制红色三角形的时候,会把像素中心点位置的PS计算后的结果,保存在表格B位置,然后给采样点0、2、3的标记位设置为B。 如果该像素只被2个或者2个以内的可见不透明物件覆盖,就像本例中一样,则两者的结果完全一样。且EQAA更省内存。否则,MSAA的效果会更好。 顺便,聊一下片元和像素。虽然片元着色器和像素着色器是一个东西,但是片元和像素绝对不是一个东西。片元是根据绘制物体的形状,有各种不同形状的。像素则是正方形的。 如果有memoryless的话,MSAA的4倍buffer只存在于local memory中,resolve后再保存到GPU内存中,不会多占用GPU内存。MRT中的depth buffer如果在后面不再使用,则可以这样使用。 如果有tile shader的话,将MSAA的4倍buffer在tile中进行resolve,也可以不会多占用GPU内存。MRT中的color buffer等后面会使用到的buffer,则可以这样使用。 这里还得到一个知识点,MSAA的话DDX、DDY的数据就不准确了,虽然只是边缘处会有影响,但是延迟贴图等就要再测试一下了。)当所有的几何图形渲染到一个multisample buffer上后,需要进行resolve操作。这个过程将所有样本颜色平均到一起的到最终像素的颜色。需要注意的是,如果对HDR颜色进行multisampling,可能会出现问题。最好是在resolve之前先进行tonemap来避免产生奇怪的颜色(参考文献[1375])。这个过程可能很昂贵,可以使用简单的近似值或者其它方式用于tone map(参考文献[862,1405])。
(Patrick:好吧,这是MSAA的又一个问题,MSAA和HDR共同使用的问题。)MSAA默认会使用box滤波器。在2007年,ATI提出了custom filter antialiasing(CFAA)(参考文献[1625]),使用窄的或者宽的tent filter,这样可以略微眼神到其它像素单元。这种模式后来被EQAA取代。现代GPU中PS或者compute shader可以访问MSAA的采样样本,并根据需要使用任意过滤器,包括可以从周围像素的样本中采样的过滤器。宽的filter可以减少锯齿,但是会丢失锐利的细节。Pettineo(参考文献[1402,1405])发现cubic smoothstep和B-spline过滤器使用2或3像素宽的过滤器可以得到总体上最好的效果。需要注意的是,即使是用自定义着色器模拟默认的box滤波器resolve,依然需要比GPU默认box filter resolve更长的时间,而如果使用更宽的过滤器内核也就意味着增加了更多的样本访问成本。
NVIDIA内置的TXAA支持的过滤器,相当于根据超过一个像素的宽区域进行重建的机制,实现一种更好的结果。它和新的multiframe antialiasing(MFAA)机制都用到了temporal antialiasing(TAA),这是一种通用的技术,它使用以前帧的结果来改善图像。在某种程度上,由于允许程序员逐帧设置MSAA的采样模式,使得该技术称为可能(参考文献[1406])。这种技术可以解决类似火车旋转车轮之类的走样问题,还可以提高边缘渲染的质量。
想象一下,这种采样模式是根据一系列图像,这些图像在渲染的时候会针对每个采样样本在像素内进行一些偏移。这些偏移是通过在投影矩阵中附加一个微小的平移完成(参考文献[1938])。生成和平均的图像越多,结果越好。这种使用多个图片的概念被用于temporal antialiasing算法。先通过MSAA或者其它算法生成一张图片,然后将之前的图片与其混合。通常只会使用2到4张图片进行混合(参考文献[382,836,1405])。旧图片的权重可以采取指数形式减小(参考文献[862]),但是,如果观看者和场景不动,那么可能会产生帧闪烁的效果,因此,通常只用权重相同的当前帧和上一帧。由于每帧的采样位置使用的是同一个像素中的不同位置,所以这样的加权和比单一帧在边缘上的处理效果更好。因此,可以说使用最近两帧平均在一起可以得到更好的结果。每帧不需要额外的采样样本,这正是这种方法如此吸引人的原因。甚至可以使用temporal sampling生成一张低分辨率的图像,然后再升到屏幕分辨率(参考文献[1110])。另外,光照计算或者其它需要多个采样样本才能得到好结果的算法,也可以通过每帧采样少量样本的方法,因为结果会在多帧中做混合(参考文献[1938])。
在不增加采样成本的情况下为静态场景提供抗锯齿的时候,这种temporal antialiasing的算法有一些问题。如果帧的权重不相等,静态场景中可能会出现一些闪烁。快速移动的物件或者快速移动摄像机的时候也可能会出现重影,这是由于前一帧的原因,导致在对象后面留下轨迹。解决重影的一个办法是指对移动缓慢的对象执行这种抗锯齿(参考文献[1110])。还有一个办法是使用reprojection重投影(详见12.2节),更好的将前一帧和当前帧的对象关联起来。这种方案中,将物件的移动向量保存在一个单独的velocity buffer中(详见12.5节)。这些向量适用于将前一帧与当前帧进行关联使用的。比如,从当前像素位置减去该向量以找到该对象的表面位置在前一帧上的颜色像素。那些上一帧有,而在当前帧没有出现的表面,在前一帧中的颜色像素则会被丢弃(参考文献[1912])。由于temporal antialiasing没有额外的采样,也不需要过多的额外工作,近几年人们对这种算法产生了浓厚的兴趣,并广泛使用。其中还有一部分原因是因为延迟渲染(详见20.1)与MSAA以及其它的一些multisampling不兼容(参考文献[1486])。随之而来的,根据应用程序的不同内容和目标,出现了大量不同的方案(参考文献[836,1154,1405,1533,1938])。比如,在Wihlidal的演示(参考文献[1885])中,可以看到EQAA、temporal antialiasing以及大量基于棋盘格采样模式的过滤器结合起来,在降低PS执行调用次数的同时保证质量。Iglesias-Guitian等人(参考文献[796])总结了前人的工作,提出了使用像素的历史数据以及预测的方式最小化滤波的方案。Patney等人(参考文献[1357])扩展了Karis和Lottes在UE4中针对VR应用程序实现的TAA方案(参考文献[862]),加入了针对眼睛移动进行补偿,所需要的各种不同尺寸的采样(详见21.3.2节)。
(Patrick:延迟渲染并非无法兼容MSAA,只是代价太高,而且法线等不能直接lerp,得到的结果可能是错误的。请系统的说明下。网上搜索到的都讲得比较含糊,谢谢。延迟渲染为什么不支持MSAA?另外,在这个文章中,也提到了MSAA的另外一个问题,它解决不了高频高光。)Sampling Patterns采样模式
有效的采样模式是减少走样、时间以及其它方面的关键因素。Naiman(参考文献[1257])表明,人类最受近似水平和近似垂直边缘上的锯齿干扰,其次是45度倾斜边缘。rotated grid supersampling旋转网格超级采样(RGSS)使用旋转的方形图案在像素内提供了更多的垂直和水平采样点。图5-25显示了这种模式的一个示例。
(Patrick:结合上一段的说明。其中accumulation buffer、MSAA、CSAA、EQAA、TXAA、MFAA、TAA都可以使用RGSS。FSAA,也就是SSAA,其实也可以使用,就是舍弃了很多计算好的像素。)RGSS是一种Latin hypercube拉丁超立方体或者N-rooks的采样,其中N个采样样本被放置到n*n的网格中,每行和每列都有一个采样样本(参考文献[1626])。使用RGSS,四个采样样本分别位于4*4子像素网格的单独行和列中。与常规的2*2采样模式相比,这种模式特别适合用于捕获近似水平和垂直的边缘,因为这种边缘可能覆盖偶数个样本,因此提供的有效级别更少。(Patrick:我觉得这里是不是偶数不重要,主要是每个片元覆盖的采样数都一样,这样每个片元颜色都差不多,没有差异化,就看着锯齿感比较强烈)
N-rooks是创建良好采样模式的开始,但它还不够。比如,样本可能都是沿着像素网格对角线的位置,这样对于几乎和对角线平行的边,会产生较差的结果。参见图5.27。为了获得更好的采样,我们需要尽量避免两个样本彼此靠近。我们还需要一个均匀的分布,将样本均匀的分布在整个区域。为了形成这样的模式,分层采样技术,比如拉丁超立方体采样将于其它方法相结合,比如jittering抖动,halton sequences哈尔顿序列,以及Poisson disk泊松盘采样(参考文献[1413,1758])
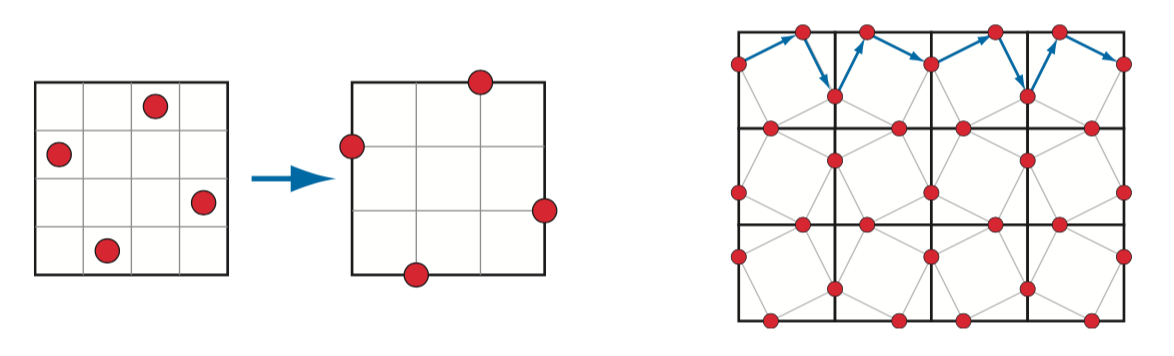
上图为N-rooks采样。左侧为一个传统的N-rooks模式,但是它在捕获沿其直线对角线的三角形边方面表现不佳,因为随着三角形的移动,所有的采样位置都位于三角形的内部或者外部。而右侧的模式,则可以更有效的捕获这种边或者其它边。
实际上,GPU厂商通常会将这些采样模式写入硬件中,一进行multisampling antialiasing。图5.28展示了GPU中使用的一些MSAA模式。对于temporal antialiasing,程序员希望可以使用coverage pattern,因为采样的位置可以逐帧变化。比如,Karis(参考文献[862])发现基本的Halton sequence哈尔顿序列比GPU提供的任何MSAA模式都要好。Halton序列在空间中生成的样本看起来是随机的,但是差异很小,也就是说,它们在空间上分布均匀,没有一个是聚集的(参考文献[1413,1938])
上图为AMD和NVIDIA所使用的MSAA采样模式。绿色方块为着色采样的位置,红色方块是采样和保存的位置。从左到右为:2*,4*,6*(AMD),8*(NVIDIA)采样(由D3D FSAA Viewer提供)
虽然网格模式更好的模拟了三角形是如何覆盖一个网格单元,但是它并不理想。场景可以由屏幕上任意小的对象构成,这意味着没有任何采样模式可以完美的捕获它们。如果用这些微小的物件或者特征组成一个图形,以恒定的间隔采样它,会产生摩尔纹以及其它干扰图形。supersampling中用到的网格模式特别容易产生走样。
一种解决方案是使用随机采样,可以提供一个更随机的模式。图5.28中的模式就可以。想象一下远处有一把细齿梳子,每个像素上都有几根梳子的齿子。如果使用传统的模式,会导致当片元覆盖或者不覆盖采样样本的时候,产生严重的伪影。如果使用一个不那么有序的采样模式则可以解决这个问题。随机化可以通过噪声取代重复的走样现象,更容易被人类的视觉系统所接受(参考文献[1413])。看上去结构不那么规律的模式帮了大忙,但是它依然有缺点,就是当每个像素都使用相同模式的时候,还是会出现锯齿。一种解决方案是每个像素都使用不同的采样模式,或者是随着时间的推移更改每个采样位置。交错采样,索引采样。交错采样是指,一组像素中的每个像素都使用不同的采样模式,这种方案在过去的几十年中,偶尔会有硬件支持。比如,ATI的smoothvision允许每个像素使用16种采样,也就是说最多有16个不同的用户定义的采样模式组成一组,然后不停的重复(比如在一个4*4的像素tile中,每个像素都使用不同的采样模式)。Molnar(参考文献[1234])和Keller、Heidrich(参考文献[880])发现,使用交错随机采样可以最小化的减弱了每个像素使用相同采样模式所导致的走样。
(Patrick:划重点,这里说明了摩尔纹是如何产生的,以及如何避免)还有一些其它的GPU算法值得注意。比如NVIDIA的老的Quincunx方案(参考文献[365]),是一个实时抗锯齿方案,让采样样本影响一个以上的像素。Quincunx是指将五个物件,按照四个在角,一个在中心的方式,类似骰子上五个点的那一面。Quincunx multisampling antialiasing使用这种模式,将四个外部采样放在像素的对应处,见图5.25。每个角的采样值都分布到其四个相邻像素。不再使用每个采样样本相同权重的方式(大多数实时方案都会使用平均权重的方式),这里中心采样点的权重为1/2,角上的采样点的权重为1/8。由于这种共享,其实每个像素只需要2个采样样本,而且结果比两个采样样本的FSAA方案好(参考文献[1678])。这种模式类似于使用了一个2维的tent过滤器,关于滤波器我们前面一节有聊过,tent滤波器肯定是比box滤波器好。
Quincunx也可以被通过针对每个像素单次采样的方式应用于temporal antialiasing(参考文献[836,1677])。每帧相对上一帧在每个轴上移动半个像素,移动方向在帧之间交替。前一帧提供像素四角的点采样,通过双线性插值的方式快速计算出对每个像素的贡献,然后和当前帧取平均。这样的话,前后两帧的权重依然相等,也就意味着静态场景不会出现闪烁的情况。但是针对移动物件的问题依然存在,但是这种方案代码简单,且比每个像素只有一个采样点的情况,效果更好。
如果只在一帧中使用的话,Quincunx也通过在像素边界共享样本的方式,将成本降低到两次采样。RGSS模式更适合捕获近水平和近垂直的边缘。FLIPQUAD模式作为第一个为移动图形所设计的模式,综合了这两种模式的优势(参考文献[22])。优势在于针对每个像素只有2次采样,效果和RGSS类似(RGSS需要针对每个像素进行四次采样)。这种模式如图5.29所示。Hasselgren等人还探索了其它利用样本共享的一些廉价采样模式(参考文献[677])
上图中的左侧,显示了RGSS模式,每个像素四个样本。然后通过将这些采样样本的位置移动到像素边缘,这样可以跨边缘进行采样共享。但是,要实现这一点,其它的每个像素都必须使用一个镜像的采样模式,如右图所示。这种采样模式被称为FLIPQUAD,每个像素需要两个采样样本。
和Quincunx一样,两个采样点的FLIPQUAD模式也可以使用temporal antialiasing,在两帧中展开。Drobot(参考文献[382,383,154])在他的hybrid reconstruction antialiasing(HRAA)中发现了当采样两个采样点时,哪个模式最好的问题。他尝试了基于temporal antialiasing的5种采样模式,最终发现FLIPQUAD模式最好。checkerboard棋盘格模式也被用于temporal antialiasing。EI Mansouri(参考文献[415])讨论了使用2个采样点的MSAA来创建棋盘格渲染,以达到在降低走样的时候,减少shader的运算量。Jimenez(参考文献[836])使用SMAA、temporal antialiasing以及一系列其它技术,找到了一种根据渲染引擎负载变化而改变反走样质量的方案。Carpentier和Ishiyama(参考文献[231])在边缘采样,并将采样网格旋转45度。将temporal antialiasing和FXAA(这个一会再讨论)相结合,在高分辨率显示器上进行精确渲染。
(Patrick:HRAA是整套AA处理框架用于Far Cry4,包含各种AA。SMAA的是基于形态学的AA,相关下载链接为:SMAA: Enhanced Subpixel Morphological Antialiasing)Morphological Methods形态学方法
锯齿通常是由边缘造成,比如几何体、尖锐的阴影或者明亮的高光。利用这一点,锯齿与结构有关,可以更好的得到一个抗锯齿的结果。2009年,Reshetov(参考文献[1483])提出了一种算法,称之为morphological antialiasing形态学抗锯齿(MLAA)。morphological形态学是指与结构或者形状有关。早在1983年,Bloomenthal(参考文献[170])就对这一领域开始了研究。Reshetov的论文提出了给multisampling的研究增加一个方向,强调了对边缘的检测和重建(参考文献[1486])
(Patrick:MLAA相关下载链接为:Practical Morphological Anti-Aliasing、Morphological Antialiasing)这种形式的抗锯齿是作为后处理的方式执行的。也就是说,先以通常的方式完成渲染,然后将结果再进行一次抗锯齿操作。自2009年来,已经开发出了多种技术。其中一些技术会依赖一些额外的buffer,比如法线或者深度buffer,这样的话得到的结果更好,比如subpixel reconstruction antialiasing(SRAA)(参考文献[43,829]),但是这种方法只适合于消除几何体的抗锯齿。分析方法,比如geometry buffer antialiasing(GBAA)以及distance-to-edge antialiasing(DEAA),有着关于三角形边缘位置的额外信息,比如边缘距离像素中心的距离有多远(参考文献[829])
(Patrick:Klayge的网站上有SRAA和GPAA的相关介绍:anti-alias的前世今生(三):hybird-aa)。其中GPAA需要将所有物体的边缘再渲染一次到RT上,然后在Blend回去。GBAA是其优化,渲染时额外生成一个Geomerty Buffer存储边缘信息,MRT,节省DC。)而最常用的方案其实只需要颜色buffer,这样的话,可以对阴影、高光以及由于前面的后处理产生的锯齿(比如轮廓边缘渲染,详见15.2.3)进行抗锯齿处理。比如,directionally and localized antialiasing方向局部抗锯齿(DLAA)(参考文献[52,829])就是基于这样的技术,针对近垂直的边缘进行水平方向上的模糊,对于近水平上的边缘进行垂直方向上的模糊。
更精确的边缘检测可以帮助着到包含任何角度边缘的像素,并确定它的覆盖范围。对潜在的边缘附近的像素进行检测,目的是尽可能重建原始边缘所在的位置。可以用边缘对像素的影响来决定混合多少周边像素的颜色。通过图5.30可以看到这整个流程。
上图为morphological antialiasing形态学抗锯齿。左侧为有锯齿的图像。目标是要确定边缘的可能方向。中间的这个图,意思是算法通过检查相邻像素来记录边缘的可能性。通过采样,显示出了两种可能的边缘位置。而在右侧途中,使用最佳猜测边缘,将相邻颜色按照估计的覆盖率比例混合到中心像素中。这个流程对图像中每个像素都会重复进行此过程。
Lourcha等人(参考文献[798])通过对MSAA的采样点进行边缘检查,得到更好的结果。需要注意的是,与基于样本的算法相比,边缘检测和混合需要更高的精度。比如,每个像素使用四个采样样本的技术,只能为对象的边缘提供五种可能:不覆盖采样、一个覆盖采样、两个、三个、四个。然而边缘位置可能有更多的位置,这样可以提供更好的结果。
还有一些可能会导致基于图像的算法失效的情况。首先,加入两个对象之间的色差低于算法的阈值时,就无法检测边缘。然后,当有三个或者三个以上的表面重叠像素在一起的时候,就不太好处理。具有高对比度或者高频元素(颜色在像素之间快速变化)的表面,可能会因此丢失边缘(Patrick:这就是所谓的使得画面变得更柔,丢失细节)。尤其是,当针对文字使用morphological antialiasing的时候,文字的质量就会降低。物件的角点可能会因此变成圆形。针对边缘是直角的曲线也会受到不好的影响。单个像素的改变会导致重建边缘的时候发生很大的变化,这样会导致帧与帧之间产生明显的伪影。改善这个问题的一个方法是使用MSAA coverage mask来提升边缘检测(参考文献[1484])。
Morphological antialiasing形态学抗锯齿方案仅使用所提供的信息。比如,宽度小于一个像素的对象(比如电线或者绳子),总是有可能出现无法像素中心位置的情况。在这种情况下,采集更多的采样样本可以提升质量,单单依靠基于图像的抗锯齿技术是不行的。此外,执行的时间也可以根据内容变化。比如当观看草地的时候可以比观看天空的时候处理时间长三倍(参考文献[231])
尽管如此,基于图像的方法由于其适中的内存占用和处理成本,在很多应用中用于抗锯齿处理。仅颜色的版本也使得可以与渲染管线进行分离,使其很容易被修改或者关闭,甚至可以作为GPU驱动的选项公开出来。两种最流行的算法是fast approximate antialiasing快速近似反走样(FXAA)(参考文献[1079,1080,1084])和subpixel morphological antialiasing(SMAA)(参考文献[828,830,834]),部分原因是它们都为各种机器提供了相同的免费的远嘛支持。连个算法都只需要颜色输入,SMAA的优势在于能访问MSAA采样样本。每个算法都有自己不同级别的设置,可以在速度和质量上进行权衡。成本基本上都在1-2ms之间,主要是因为这是视频游戏愿意花费的成本。最后,这两种算法都还可以利用temporal antialiasing(参考文献[1812])。Jimenez(参考文献[836])提供了一种改进的SMAA算法,比FXAA快,并介绍了对应的temporal antialiasing机制。最后,我们向读者推荐Reshetov和Jimenez(参考文献[1486])关于形态学技术的文章以及在视频游戏中如何使用。
5.5 半透明,alpha,合成
半透明物件允许光线通过的方式有很多种。对于渲染算法,它们大致上可以分为基于灯光的半透明效果和基于视图的半透明效果。基于灯光的效果是指半透明对象导致灯光减弱或者转向,从而导致场景中的其他对象以不同的方式被照亮和渲染的效果。基于试图的半透明效果是半透明对象本身被渲染的效果。
在本节种,我们将它讨论最简单的基于视图的半透明,其中半透明充当其后面对象颜色的衰减器。在后面的章节中,我们将向西讨论基于视图和灯光的半透明效果,比如磨砂玻璃、光线弯曲(折射)、由于透明对象的厚度而导致的光衰减以及由于视角而导致的反射率和透射率变化。
一种给人以透明错觉的方法被称为screen-door transparency过滤网门(参考文献[1244])。其思想是用像素对齐的棋盘格填充模式渲染半透明三角形。也就是说,在绘制的时候根据规则丢弃一些像素(Patrick:原文every other pixel of the triangle is rendered实在没看懂,所以用自己的话说了。),使得后面的对象部分可见。通常屏幕上的像素足够接近,使得棋盘格图案本身不可见。这种方法的一个主要缺点是,通常在一个区域只能有一个透明对象。比如,在蓝色对象上渲染半透明的红色和绿色,则三种颜色其实只能看到两种。这里的棋盘格的过滤比例是50%。还可以使用其他比例,但是这样的话可能就会导致棋盘格可见了。(参考文献[1245])
(Patrick:这一段有点复杂,其实不如去看奶牛上余羊的一个例子:让角色半透明:从 Ordered Dithering 说起(一)、让角色半透明:后期模糊(二)、让角色半透明:树形结构(三)。这种方案,透明层数越多效果越差。)也就是说,这种技术的一个优点就是简单。半透明对象可以在任何时候以任何顺序呈现,不需要特殊硬件。把对应的像素当作不透明处理,使得所有半透明导致的问题都消失了(Patrick:比如延迟渲染不支持半透明,那么ok,把半透明当作不透明处理,就ok了)。这种思路也被用于带cutout纹理的边缘锯齿的处理上,但是是被用在subpixel级别,被称为alpha to coverage(详见6.6节)。
由Enderton等人(参考文献[423])推荐,随机透明度使用subpixel scrren-door mask与随机采样结合。一个虽然有噪声,但是合理的图片,是通过随机点画模式来表示片元的alpha coverage。如图5.31。为了使得结果看起来合理,需要针对每个像素采用大量的采样,也就是需要大量的内存用于所有子像素的采样。而吸引人的是,这样的话,就不再需要blend,抗锯齿,半透明以及其他会导致对像素进行部分覆盖的现象,只需要这一种机制就可以解决。

上图为随机透明度。放大区域显示的是产生的噪声。(图片来自NVIDIA SDK11(参考文献[1301])示例,由NVIDIA公司提供)
大多数半透明的算法是将半透明物件的颜色与其后面物件的颜色混合在一起。为此,推出了alpha blend的概念(参考文献[199,387,1429])。当在屏幕上渲染对象的时候,RGB的颜色buffer和z的深度buffer与每个像素关联在一起。还可以为对象覆盖的每个像素定义一个alpha值。alpha是用于描述给定像素的不透明度,以及片元对像素的coverage。alpha为1.0的时候,意味着物件是半透明,并完全覆盖对应的像素。0.0意味着像素完全不被coverage,也就是说该片元是完全透明的。
像素的alpha值可以表示不透明度、覆盖率或者两者,具体取决于环境。比如,肥皂泡的边缘可以覆盖像素的3/4,并且几乎是透明的,使得9/10的光进入眼睛,也就是说它是1/10不透明的。alpha值为0.75*0.1=0.075。但是,加入使用MSAA或者类似的抗锯齿方案,则样本本身会考虑覆盖范围。3/4的采样样本会受到肥皂泡的影响,在对应的每个样本中,将使用0.1不透明度值作为alpha。
5.5.1 blending顺序
为了使物件看起来是透明的,需要将其以alpha小于1.0的形式绘制在已有场景上。该物件所覆盖到的每个像素都会收到一个由PS计算得到的RGBA值。将该值与像素上原有值进行混合,混合的时候通常使用over操作,如下:
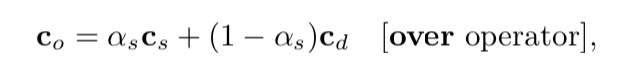
其中Cs是半透明物件的颜色(s->source),As是物件的alpha。Cd是该像素blending之前的颜色(d->destination)。Co是将半透明物件over到场景后的颜色。在这个例子中,Cs和As是通过渲染管线计算并输出出来,该像素的原始颜色被最终颜色Co所取代。如果传入的RGBA是不透明的,也就是As=1.0。则方程就可以简化为用对象的颜色直接完全替换像素的颜色。举个blending的例子。一个红色的半透明物件被绘制到一个蓝色背景上。假如该物件的某些像素的RGB为(0.9,0.2,0.1),背景颜色为(0.1,0.1,0.9),半透明物件的透明度为0.6。这两个颜色的混合是:0.6 * (0.9, 0.2, 0.1) + (1 - 0.6) * (0.1, 0.1, 0.9),输出结果为(0.58, 0.16, 0.42)。
over操作可以使得物件看起来是半透明的。针对半透明使用这样的操作没有问题,在场景中,我们认为一些物件是半透明的,是因为我们能透过它看到后面的物件(参考文献[754])。使用over操作模拟了薄纱织物的真实效果。织物后面的物件被部分模糊了——因为织物的部分是不透明的,挡住了后面的物件。而实际上,松散织物的alpha覆盖率随着角度的变化而变化(参考文献[386])。我们这里的重点是,alpha模拟了材质覆盖像素的程度。
但是针对其它的一些半透明现象,over操作就不太合适了,比如有色玻璃或塑料。在现实世界中,透过一个红色滤光片观看一个蓝色物件,通常会使得蓝色物件看起来很暗,这是因为蓝色物件反射的光线在穿过红色滤光片的时候,基本无法穿过。见图5.32。而如果使用over的话,结果是红色和蓝色的部分想加。这里其实最好是将两种颜色相乘,并添加上半透明对象本身的颜色。第14.5.1节和第14.5.2节将讨论这种物理透射率。

上图可以看到红色薄纱织物和红色塑料片,所产生的不同半透明效果。请注意看阴影也不同。(照片由Morgan McGuire提供)
(Patrick:这个蛮有意思的,薄纱织物相当于有孔的不透明,可以用screen-door transparent实现,颜色通过over操作,阴影可以看到归根结底还是有孔的不透明。塑料片是真的半透明,颜色通过两种颜色相乘,阴影是一整片全部暗了。)在基本的blend操作中,over是半透明效果中最常见的一种方式(参考文献[199,1429])。其它的还有additive blending,其中像素只是简单的求和。如下:
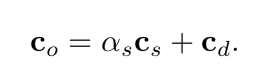
这种blending模式比较适合用于发光效果,比如闪电或者火花,它们不会衰减后面的像素,只会使得像素变亮(参考文献[1813])。但是这种模式不像是正确的半透明,因为不透明的表面压根没起到过滤作用(参考文献[1192])。对于一些层状的半透明表面,比如烟或者火,additive blending有提升颜色饱和度的效果。
为了正确的渲染半透明物件,我们需要在绘制完不透明物件后再绘制它们。我们可以先把blending关闭,绘制所有的不透明物件,然后再打开blending后,绘制不透明物件。理论上我们可以适中保持blending打开,因为不透明的alpha值为1.0,也可以起到只用source color,忽略destination color的效果,但是这样的话会增加消耗,且没有任何实际收益。(Patrick:这里需要画重点,看来虽然blending是硬件操作,但是还是会有消耗的。所以还是通过glEnable和glDisable把blend根据需要打开或者关闭吧。也不知道硬件里面有没有把blend one zero默认当作disable blend做处理,还是真的执行了一次相加操作。)
Zbuffer的一个限制是针对每个像素只能存储一个物件。如果多个半透明物件重叠在相同的像素中,单靠Zbuffer无法保存并resolve所有可见物件的效果。在任意像素点上绘制半透明物件的时候,需要按照从后到前的顺序。如果不这样做的话可能会出现错误的效果。实现这种排序的一个方法是根据单个对象的质心沿视图方向的距离对其进行排序。这种粗略的排序可以完成工作,但是在很多情况下会出现问题。首先,这个排序是个近似值,可能会出现被认为距离更远的物件实际上在距离更近的物件前面。除非将每个mesh分解成单独的块,否则不可能在所有视图角度,逐mesh的解析相互穿插的物件。详见5.33的左图。即便是针对凹面的单一mesh,当其在屏幕上,沿着视图方向与自身穿插的时候也会出现排序问题。

如上图中的左侧,使用ZBuffer进行半透明渲染绘制。将mesh按照一个不那么准确的顺序绘制,导致出现了严重的错误。右侧中,使用depth peeling得到了正确的结果,代价是需要额外的pass(图片由NVIDIA公司提供)
尽管如此,由于它的简单性和速度,且不需要额外的内存或者特殊的GPU支持,执行粗略的透明排序这个方案依然被大量使用着。如果使用这个方案,最好是在渲染半透明物件的时候关闭Z-buffer。也就是说,依然按照正常使用ZBuffer进行ZTest,但是半透明物件不再改变ZBuffer的深度值,ZBuffer中始终保存距离摄像机最近的不透明物件的深度值。这样的话,至少所有半透明物件都会被绘制,而不会在相机旋转的时候由于更改了半透明物件的渲染顺序而突然出现或者消失。还有一些其它技术用于改善效果,比如对半透明物件渲染两次,先渲染背面,再渲染正面。(参考文献[1192,1255])
也可以修改over的公式,使从前往后绘制可以得到相同的结果。这种blending被称为under操作:
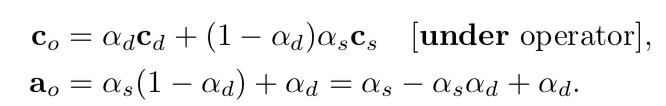
需要注意的是,under操作需要destination保存一个alpha值,这个over操作不需要。也就是说destination(正在混合的较近的透明表面)不是不透明的,所以需要一个alpha值。under操作和和over操作类似,只是将source和destination进行交换。需要注意的是,alpha的公式与顺序无关,source和destination的alpha可以交换,最终得到的alpha值不变。
alpha的公式是根据将片元的alpha当作coverages得到的。Porter和Duff(参考文献[1492])提到,由于我们不知道每个片元coverage区域的形状,那么假设每个片元都是按照其alpha的比例覆盖另一个片元。比如,如果As=0.7,像素会被分成两个部分,其中0.7的部分被source片元覆盖,剩下的0.3部分没有被覆盖。如果不考虑其他情况,destination的片元(比如,Ad=0.6)按照比例与source片元覆盖。这个公式有几何意义,如图5.34所示。
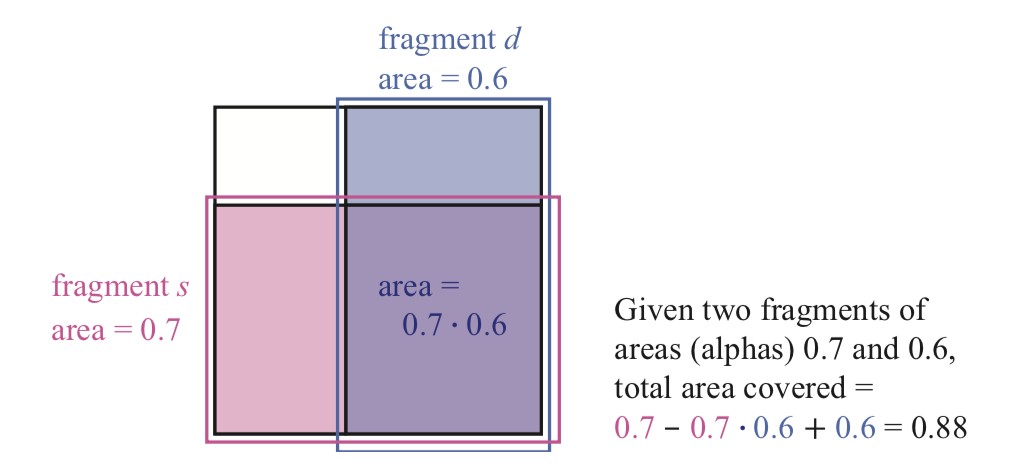
如上图所示,一个像素和两个片元s和d。将两个片元按照两个不同的轴对齐,每个片元都按照比例覆盖另外一个片元,即它们不相关。两个片元覆盖的区域也就等于under公式的alpha部分,As - As * Ad + Ad。这意味着将两个区域相加,然后减去它们重叠的区域。
5.5.2 Order Independent Transparency
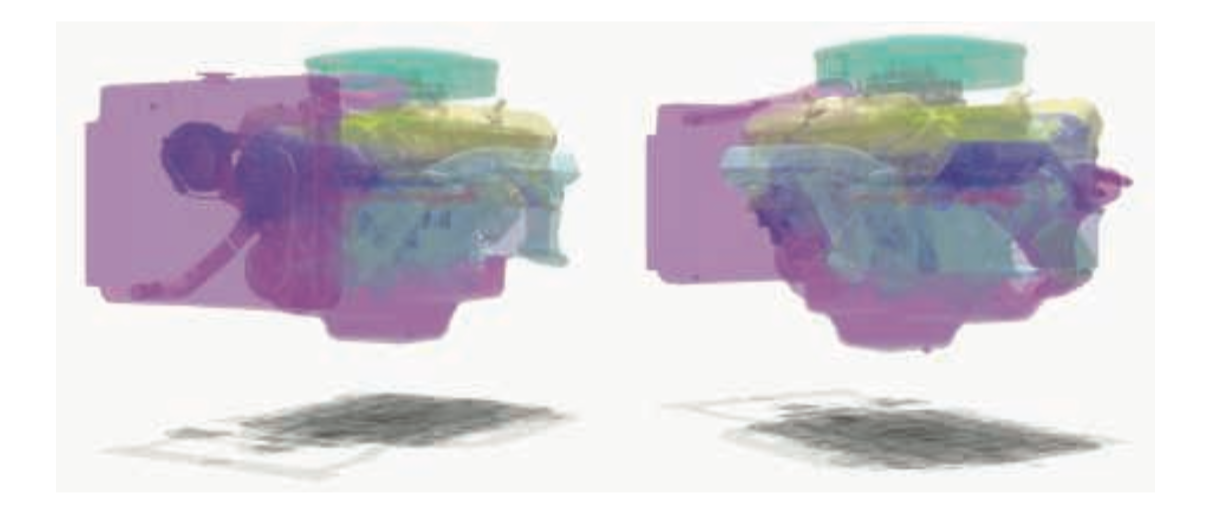
under操作可以被用于将所有半透明的物件绘制到一个单独的颜色buffer上,然后再将该颜色buffer通过over操作,绘制到场景的不透明视图上。under操作还可以被用于一种order-independent transparency(OIT)算法depth peeling(参考文献[449,1115])上。Order-independent代表着应用程序不需要执行排序。Depth peeling的原理是使用两个Z-buffer和多个pass。首先,第一个pass是绘制所有包含半透明物件在内的所有物件的深度Z,并保存在第一个Zbuffer上。第二个pass绘制所有半透明的物件。如果有一个物件的深度和第一个ZBuffer中的深度一样的时候,我们知道了这是离摄像机最近的半透明物件,并将它的RGBA值保存到一个单独的颜色buffer中。然后将该层peel剥离出来,方法是找到比第一个深度Z大,但是最靠近第一个深度的半透明物件。该Z深度是第二靠近摄像机的半透明物件的深度。持续的进行这样的peel pass,并使用under的方式叠加半透明layer。若干pass之后,将半透明物件blend到不透明图像上。见5.35。
(Patrick:这里虽然用到了最靠近摄像机的半透明物件和第二靠近摄像机的半透明物件这样的词语。但其实这样并不严谨,是layer更严谨。因为是使用ZEqual的方式,所以其实并非一个物件一个物件的绘制,而是用ZEqual的方式先绘制最靠近摄像机的那一层半透明,然后再第二层。)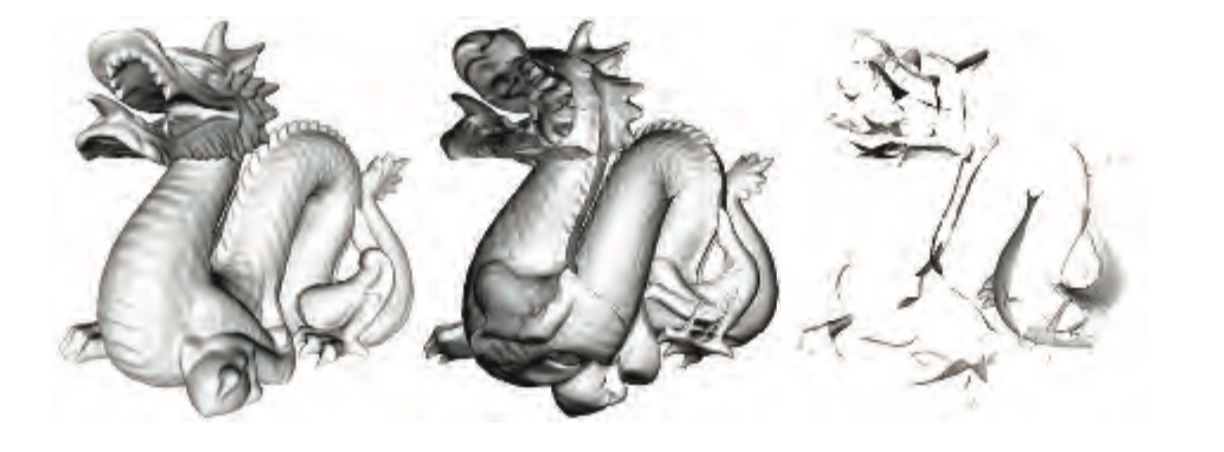
每个depth peel pass绘制一层transparent layer。上图左侧为第一个pass,展示了直接对眼睛可见的那一层。中间那个图片为第二个layer,展示了每个像素中第二靠近摄像机的半透明表面,在本例中是物件的背面。右侧的为第三个layer,是第三靠近的半透明表面。最终结果可以在624面的图14.33中看到。(图片由Louis Bavoil提供)
(Patrick:depth peeling还会有个问题,就是开销不稳定,因为pass数量依赖于相机角度等。depth peeling的文档见Interactive Order-Independent Transparency)这个方案已经开发了好几种变体。比如Thibieroz(参考文献[1763])给出了一种从后往前的算法,这种算法的优势在于可以直接将半透明的颜色进行混合,也就不需要额外的alpha通道了。然而depth peeling有个问题就是需要知道一共多少个pass足以捕获所有的半透明layer。一种硬件的解决方案是提供一个像素绘制计数器,可以得知渲染了多少个像素,当一个pass没有渲染任何像素的时候,渲染就完成了。使用under操作的优势在于最重要的半透明layer(离眼睛最近的那一层)最先被渲染。每一个半透明表面都会增加它所覆盖像素的alpha值,当alpha的值为1.0的时候,该像素基本上已经称为了不透明,更远处的物件产生的效果也就可以忽略不计了(参考文献[394])(Patrick:这是针对under操作说的,所以我在想,游戏引擎是否可以设计成从前往后绘制,每个像素只绘制三层左右,因为游戏中的粒子太多层太耗了,效果也不明显)。从前往后的peeling可以当其中一个pass的渲染像素数少于最小阈值的时候进行截断,或者只绘制固定数量的pass。这一点针对从后往前绘制的peeling无效,因为最近(基本上也是最重要)的layer在最后绘制,如果提前结束会丢失重要效果的。
虽然depth peeling很有效,但是它的速度很慢,因为半透明物件中每一个peeled layer都是一个单独的渲染pass。Bavoil和Myers(参考文献[118])提出了dual depth peeling方案,在每个pass中剥离最近和最远的两个depth peel layer,从而将渲染pass减少一半。Liu等人(参考文献[1056])提出了一种bucket 排序算法,可以在一个pass中捕获32个layer。这种方法的一个缺点是它需要大量的内存来保持所有层的排序顺序。如果再加上MSAA或者其他抗锯齿算法,会把内存的需求提高到一个天文数字。
(Patrick:dual depth peeling的文档见Order Independent Transparency with Dual Depth Peeling。大概原理就是使用3个RT的MRT的概念,RT0保存vec2(-nearDepth, farDepth),RT1保存使用under操作的front transparent layer color,RT2保存使用over操作的back transparent layer color。第一个pass中先绘制所有半透明物件的深度,记录下最近和最远的两个layer的深度保存在RT0,第二个pass中绘制所有半透明物件,根据RT0的深度值,将最近和最远两个人layer的color根据under、over操作绘制到RT1和RT2上,然后将第二近和第二远的深度保存在RT0。依次下去,最中间一层通过深度对比可以捕获到,然后混合到RT1或者RT2都可以。也可以参照一个demoDual Depth Peeling 在WebGL中的实现例程和VTK Technical Highlight: Dual Depth Peeling。bucket排序算法的话,32个layer就需要至少32个RT,这个内存消耗太大了。)渲染半透明物件可能会导致交叉问题并非是因为我们缺乏算法,而其实这是一种针对GPU的优化。在1984年,Carpenter提出了A-buffer(参考文献[230]),是另外一种形式的multisampling。在A-buffer中,每个被渲染的三角形都为其完全或者部分覆盖的屏幕网格单元创建了一个coverage mask。每个像素都保存了一系列片元。不透明的片元可以剔除后面的片元,类似Z-buffer。半透明的片元全部都被保存了起来。当所有的都准备好后,根据这些片元,通过resolve所有的采样,就可以得到一个最终结果。
DX11公开了一个新的功能,使得在GPU创建一系列片元这种想法成为了可能(参考文献[611,1765])。使用的功能包括unordered access views(UAVs)和原子操作,如第3.8节所述。通过MSAA的抗锯齿是通过访问coverage mask以及针对每个采样样本评估PS来实现的。该算法是通过渲染每个半透明表面,并将片元计算出来插入到一个长的数组中。除了颜色和深度之外,还生成了一个单独的指针结构体,将该像素的每个片元和之前的片元保存在了一起。然后执行了一个单独的pass,绘制了一个全屏的四边形以保证所有的像素都被一个ps处理到了。该shader根据链接检索到该像素中所有的半透明片元。每个片元都与前面的片元依次排序。然后按照此顺序从后向前blend,以得到最终的像素颜色。因为是通过ps进行的blend,所以如果需要,可以为每个像素指定不同的blend模式。随着GPU和API的不断发展,原子计算的成本越来越低,这样这个方案的性能也就不断得到提高。(参考文献[914])
A-buffer的优点在于,根据每个像素对应多少片元分配内存,GPU中的链表实现也是如此。但是,在某种意义上也是一个缺点,因为在开始渲染这一帧之前,所需的存储量是未知的。当场景中有头发、烟雾或者其他可能产生大量重叠的半透明物件的时候,会产生大量的片元。Andersson(参考文献[46])提到,针对复杂的游戏场景,可能会多达50个比如半透明物件(比如树叶)和多达200个半透明粒子重叠在一起。
GPU通常会预先分配buffer和数组等内部资源,链表也不例外。用户需要先决定需要多少内存,当在使用的时候遇到内存不足的情况,会导致明显的错误。Salvi和Vaidyanathan(参考文献[1532])提出了一种解决这个问题的方案,multi-layer alpha blending,使用了Intel推出的一个被称为pixel synchronization像素同步的工呢个。如图5.36。这个功能提供了比原子操作开销更小的programmable blending功能。他们的方法重新规划了存储和blend,这样的话当内存不够的时候得到完美的降级。粗略的排序有利于这个方案。DX11.3提出了rasterizer order views(详见3.8节),任何支持这种buffer的GPU都支持这种半透明方案。移动设备中有一种类似的技术被称为tile local storage,使得移动设备支持multi-layer alpha blending(参考文献[153])。这个机制会产生一定的性能损耗,因为这种类型的算法挺耗的。(参考文献[1931])

如上图中的左上侧,通过传统的从后往前绘制的alpha blend,会由于错误的渲染顺序导致渲染错误。在右上侧,通过A-buffer渲染得到一个完美的没有交叉的图片。左下角图片是使用multi-layer alpha blending。右下角为A-buffer和multi-layer图片的区别对比图,为了可见还做了乘以4处理(参考文献[1532])。(图片是由Intel的Marco Salvi和Karthik Vaidyanathan提供)
(Patrick:文档地址为:Multi-Layer Alpha Blending)这种方案是基于Bavoil等人(参考文献[115])提出的k-buffer,其中将前几个可见层尽可能的保存下来和排好序,更深的层则被尽可能的合并和抛弃。Maule等人(参考文献[1142])使用k-buffer,通过加权平均法计算这些较远的层。加权和(参考文献[1202])和加权平均(参考文献[118])半透明技术与顺序无关,只有一个pass,可运行在几乎所有GPU上。问题是它们不考虑物件的顺序。因此,如果使用alpha来表示coverage,一个红色丝巾绘制在一个蓝色丝巾上会得到紫色,而不是正确的看到一个略带蓝色的红丝巾。通常这种方案,如果对几乎不透明的物件进行处理,会得到一个糟糕的结果,但是这个算法在可视化方面依然很有用,针对高度透明的表面和粒子非常有用。如图5.37。

上图展示了,随着不透明的增加,对象顺序变得越来越重要(图片由Dunn(参考文献[394])提供)
半透明的加权和公式为
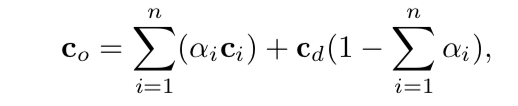
其中n是半透明表面的数量,Ci和Ai代表了一组半透明的数值,Cd是场景不透明部分的颜色。在渲染半透明表面的时候,这两个求和分别累加和存储,在半透明渲染结束的时候,在每个像素的地方进行公式计算。这个方法的问题在于,第一个求和公式算出的颜色超过(1.0, 1.0, 1.0),以及背景颜色由于alpha的和超过1.0,而为负的情况。
通常会首选加权平均公式,因为它解决了上述问题
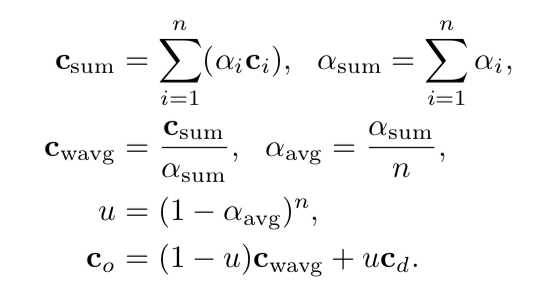
第一行表示在半透明渲染期间,生成的两个保存求和信息buffer中的结果。每个半透明表面都根据自己的alpha值作为权重影响Csum,几乎不透明的表面的颜色影响更大,几乎透明的表面的颜色基本没有起到作用。然后将Csum除以Asum,可以得到一个平均半透明颜色。Aavg是所有alpha值相加取平均后的结果。数值u是对n层半透明物件的平均alpha值进行n次处理后,对destination(不透明场景)可见度的估计。最后一行是over操作,其中1-u代表着source alpha。
加权平均的一个限制是,对于相同的alpha,它将所有的颜色均匀的混合,而没有考虑顺序。McGuire和Bavoil(参考文献[1176,1180])提出了weighted blended order-independent transparency,以给出更令人信服的结果。在它的公式中,到表面的距离也会影响权重,离摄像机更近的表面影响更大。另外u也不是对alpha取平均后计算得到,而是通过对(1-Ai)相乘后,然后用1减去而得到,这样可以得到一组曲面的真实alpha覆盖率。(Patrick:这里应该是写错了,(1-Ai)相乘后得到u,u为不透明物件的覆盖率,然后1-u为半透明曲面的覆盖率)如图5.38所示,这种方法产生了更具视觉说服力的结果。
上图为从两个不同摄像机位置观看同一个引擎波形,这里都使用到了weighted blended order-independent transparency进行渲染。将距离列入权重的一部分可以更有助于澄清那些表面更接近观察者(参考文献[1185])(图片由Morgan McGuire提供)
缺点是,在大环境中彼此靠近的物件,在距离的权重上几乎相同,使得结果与加权平均值得到的结果相差不大。此外,随着相机与半透明物件的距离改变,深度权重的影响可能随之改变,但这种变化是渐进的。
McGuire和Mara(参考文献[1181,1185])将这个方案进行了扩展,使其包含了一个合理的transmission透射颜色效果。如前所述,本节中提到的所有的半透明算法都是通过对颜色进行blend而非过滤它们,模拟像素覆盖。为了提供颜色过滤效果,使用PS读取不透明场景,然后每个半透明表面在其所覆盖的像素乘以其颜色,得到的结果保存在第三个buffer中。这个buffer中不透明物件被半透明物件颜色所影响,然后在resolve半透明buffer的时候,用这个buffer代替不透明场景。这个方法之所以有用,是因为与由coverage产生的透明度不同,色彩transmission传输与顺序无关。
还有一些其他算法使用到了这里介绍到的几种技术中的元素。比如Wyman(参考文献[1931])根据内存需求、插入、合并方法,是否使用alpha或者几何覆盖率以及如何处理丢弃片元对以前的工作进行了分类。他提出了两个新的方法,寻找以前研究中的空白。他的stochastic layered alpha blending随机分层alpha blend方法使用k-buffer,weighted average加权平均和随机透明度。他的另外一个算法是Salvi和Vaidyanathan方法的变体,使用了coverage mask而非alpha。(Patrick:Wyman的官网是Chris Wyman's Papers List,其中stochastic layered alpha blending的链接为Stochastic Layered Alpha Blending)
鉴于半透明内容的复杂类型、渲染方式以及GPU能力,没有一个完美的解决方案用于渲染半透明物件。我们希望有兴趣的读者参考Wyman的论文(参考文献[1931])和Maule等人对交互式半透明物件相关算法的调查(参考文献[1141])。McGuire的介绍(参考文献[1182])给出了一个更广阔的视野,莞产了其他相关现象,比如体积光、色彩transmission传输以及折射,这些都会在本书的后面章节进行更深入的讨论。
5.5.3 Alpha预乘和合成
over操作也可以被用作将图片或者人造物件blend在一起。这个过程被称为compositing合成(参考文献[199,1662])。在这种情况下,该物件上每个像素处的alpha值与RGB颜色值保存在一起。由alpha通道形成的图片被称为蒙版。它显示了物件的轮廓形状。示例可见203面图6-27。该RGBA图像可被用于与其他此类元素或者背景混合。
使用合成RGBA数据的一种方法是alpha premultiplied预乘(也被称为associated alphas)。也就是说,RGB值在使用之前乘以alpha值。这使得公式上的合成更加有效:
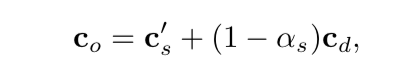
公式中的C‘s是预乘的源通道,代替了公式5.25中的As*Cs。Alpha预乘还可以在不改变混合状态的情况下使用over和additive blending,因为在blending的时候,源颜色是通过相加的方式进行处理的(参考文献[394])(Patrick:additive中主要是destination不做乘法吧。)。请注意,Alpha预乘中RGBA的值,RGB分量一般不会超过alpha值,尽管这样的话可以用于产生特别明亮的半透明值。
渲染合成图像与alpha预乘天生吻合。默认情况下,在黑色背景上渲染抗锯齿不透明对象会产生一个预乘值。假设一个白色(1,1,1)的三角形的边缘在某些像素上覆盖率为40%。使用(非常精确的)抗锯齿,像素其实是被设置为0.4的灰色,也就是说该像素的颜色为(0.4,0.4,0.4)。如果存储alpha值的话,也将是0.4,因为这就是这个三角形在这个像素中覆盖的大小。所以RGBA值为(0.4,0.4,0.4,0.4),也就是一个预乘的数值。
另一种存储图像的方式是使用un-multiplied alpha非alpha预乘,也被称为un-associated alpha,或者被称为令人费解的nonpremultiplied alpha。un-multiplied alpha是指:RGB值没有与alpha相乘。针对上面这个白色三角形的例子,un-multiplied颜色为(1,1,1,0.4)。这个方法的优点在于可以保存三角形原始的颜色,但是在显示之前始终需要乘以存储的alpha。在执行过滤和混合的时候,最好使用预乘数据,否则会因为使用了un-multiplied alpha导致线性插值等操作出错(参考文献[108,164]),导致在物体边缘生成了黑色条纹这样的伪影(参考文献[295,648])。第6.6节将进行进一步讨论。alpha预乘也可以用于更干净的理论。(参考文献[1662])
图像处理软件中,un-associated alpha可以在不影响底层图像原始数据的情况下给一个图像打标记。此外,un-associated alpha也就意味着颜色通道中的全部精度范围都可以被使用。也就是说,在将un-multiplied RGBA值从计算机图形学所使用的linear空间中转过来或者转过去的时候,必须要特别注意。比如,没有浏览器可以正确的做到这一点,也不太可能做到这一点,因为这种行为是不正确的(参考文献[649])。支持Alpha的图像文件格式包括PNG(仅支持un-associated alpha),OpenEXR(只支持associated),TIFF(两种alpha类型都支持)。
还有一个与alpha通道有关系的概念是chroma-keying(参考文献[199])。这是视频制作中的一个术语,颜色在绿色或者蓝色的幕布前拍摄,然后与一个背景进行blend。在电影工业中,这个过程被称为green-screening或者blur-screening。这里的思路是,一个特定的颜色色调(用于胶片工作)或精确的数值(用于计算机图形学)被指定为透明,只要被检测出来,则将背景混合上去。这样的话,图像可以通过RGB颜色获取一个轮廓形状,而不再需要alpha值。此方案的缺点是,这个方案中的任何物件要么是完全透明的,要么是完全不透明的,alpha实际上只有1.0或者0.0。例如,GIF格式就允许将一个颜色指定为完全透明。
5.6 Display Encoding
当我们计算光照、纹理或者其他操作的效果时,是会假设使用的值为线型。也就是说,这意味着加法和乘法都能按照预期工作。然而,为了避免各种视觉伪影,显示器buffer和纹理一般会使用非线性编码,这一点我们必须要考虑进去。最简单的方法是:将shader输出的[0,1]范围的颜色值,进行power(x,1/2.2)操作,执行所谓的gamma矫正。对输入的纹理和颜色执行相反的操作。在大多数情况下,可以让GPU来做这个事情。本节会解释这种方法如何操作,以及为什么这样操作。
我们从cathode-ray tube(CRT)开始说起。在数字成像的早期,CRT显示器是一种标准。这些器件在输入电压和显示亮度之间呈现幂的关系。当应用于一个像素的电压增加的时候,radiance发射的辐射不会线型增加(这一点令人惊讶),而是成power正比的增加到大于1的功率。假如power为2。设置为0.5的像素的发光亮为设置为1像素发光亮的1/4,即power(0.5,2)=0.25。尽管LCD与其他显示技术有不同于CRT的固有音调响应曲线,但它们是用转换电路制造的,所以可以模拟出CRT的现象。
这个power函数几乎与人类视觉的亮度敏感度相反(参考文献[1431])。这种幸运的巧合的结果是,编码在感知上大致是一致的。也就是说,在可显示的范围内,一对编码值N和N+1之间的感知差异大致是恒定的。通过阈值对比度的测量,我们可以在各种条件下检测到约1%的亮度差异。当颜色存储在有限精度的显示buffer中,这种接近最优的值分布,最小化了带状伪影(详见23.6节)。这样的好处也适用于纹理,它们通常使用相同的编码。
这种display transfer function显示器传输函数描述了显示器buffer中的数字信号与从显示器发出的radiance level辐射率之间的关系。因此,也被称为electrical optical transfer function电光传输函数(EOTF)。display transfer function显示器传输函数是硬件的一部分,对于计算机显示器、电视、电影放映机有不同的标准。对于整个流程的另外一端,图像和视频捕获设备,也有一个标准的传输函数,被称为optical electric transfer function光电传输函数(OETF)(参考文献[672])。
当对准备显示的线性颜色进行编码的时候,我们的目标是为了消除display transfer function显示器传输函数的影响,这样的话我们计算出来的数值都会发出相应的radiance level亮度级别。比如,我们计算出的数值加倍,我们希望输出的radiance亮度也加倍。为了保持这种联系,我们应该应用display transfer function显示器传输函数的逆来抵消其非线性效果。这种消除显示器响应曲线的过程也被称为gamma矫正,原因也就很明显了。当解码纹理的时候,我们也需要应用display transfer function显示器传输函数来生成一个用于着色的线性数值。图5.39展示了在整个显示过程中的编解码。
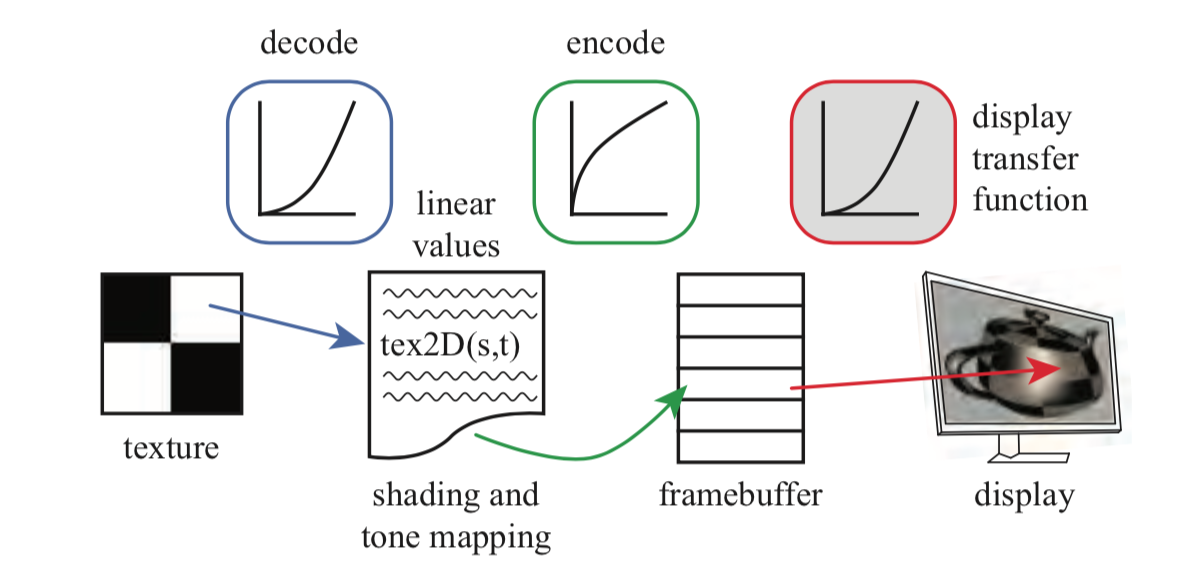
如上图所示,左侧中为一个被GPU着色器所使用的PNG颜色纹理,其非线性值通过蓝色曲线被编码称为一个线性数值。在进行着色和tone mapping(详见8.2.2节)之后,最终颜色被通过绿色曲线编码并保存在framebuffer中。这个值以及display transfer function显示器传输函数决定了最终输出的radiance辐射量(红色)。绿色和红色的函数相抵消,所以最终发出的辐射量与计算所得到的线性数值成正比。
个人电脑显示器的标准传输函数是由一种被称为sRGB的颜色空间规范定义。大多数GPU对应的API在从纹理读取数值或者写入color buffer的时候都可以自动的进行sRGB转换(参考文献[491])。如第6.2.2节所述,mipmap的生成也会考虑sRGB编码。通过先转换为线性值,然后进行插值,这样纹理值之间的双线性插值将得到正确的结果。在进行alpha blending的时候,也会先将framebuffer中存储的数值根据RT是否为sRGB,先进行解码操作转换到线性空间,然后在与新的线性数值进行blend,最后在对结果编码进行保存。
(Patrick:有很多人问我如果没有sRGB格式,是否可以模拟线性空间。关于这一段,很好的解释了。没有sRGB格式的话,上述两个事情都无法完成,一是无法将destination RT中的数据根据格式转换到线性空间,二是纹理双线性插值的结果和真实线性空间双线性的结果不一样。)有一点非常重要,就是一定要在渲染的最后阶段,也就是把值写入framebuffer用于显示的时候,再进行转换。假如进行了显示器编码后,又进行了后处理操作,这些效果其实是基于一个非线性数值进行的处理,所得到的结果一般是错误的,且通常会导致伪影。可以将显示器编码看成是一种压缩格式,一种展示数值效果最好的格式(参考文献[491])。可以以下面这种方式理解这一块,当我们进行物理计算的时候,需要使用线性数值,而当我们想要显示结果或者准备访问可显示的图片(比如color纹理)的时候,我们需要适当的进行编码或者解码操作,将数据移动到其显示编码格式,或者从显示编码格式移出来。
如果需要手动执行sRGB转换,可以使用标准转换公式或者几个简化版本。实际上,显示器是由针对每个颜色通道的若干位控制的,比如,消费者级别的显示器一般每个颜色通道有8位组成,组成一组[0,255]的数据。我们先不关心这些位数,而是把显示编码级别表示位一个范围[0.0,1.0]。线性数值的范围也是[0.0,1.0],用浮点数表示。下面,我们用x表示线性数值,y表示存储在framebuffer中的非线性数值。为了将线性数值转换成sRGB非线性数值,我们需要应用sRGB显示传输函数的逆函数:
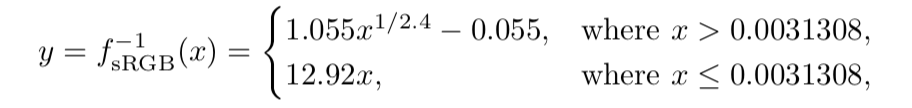
x表示线性空间RGB三通道中的一个通道。这个公式将被应用于每个通道,然后这三个通道共同用于显示。当手动执行这些函数的时候一定要非常注意。经常容易出现的错误有两种,一是把sRGB颜色和线性颜色搞混淆了,二是执行两次编码或者解码。
这两个转换表达式的底部是一个简单的乘法运算,这是由于数字硬件需要使变换完全可逆而产生的(参考文献[1431])。顶部表达式适用于几乎所有的输入值X(X的范围是[0.0,1.0]),将数值进行power操作。考虑到偏移和缩放,这个函数类似于下面这个更简单的公式(参考文献[491]):
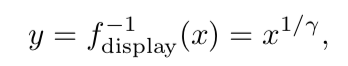
其中r为2.2,而希腊字母r,则是gamma矫正名称的由来。
和计算出来的数值在显示之前一定要进行编码操作一样,由相机或者摄像机拍摄到的图片在使用之前也一定要先转换到线性空间。在显示器或者电视中看到的任何颜色都是显示编码后的RGB值,这些数值可以通过截屏或者color picker获取。这些数值以文件格式(如PNG、JPEG和GIF)存储,这些格式可以不经过转换,直接发送到framebuffer上用于在屏幕上显示。换而言之,你在屏幕上看到的都是经过显示编码的数据。这些数据在被用于着色计算之前,我们需要将其转换成线性值。将显示的sRGB值转换到线性值的公式为:
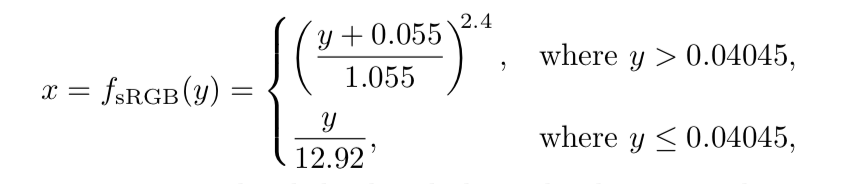
这里的y是显示中一个通道的数值,比如,存储在图像或者framebuffer中的内容,数据的范围为[0.0,1.0]。这个解码函数刚前面的公式刚好相反。这就意味着,如果shader中访问的一个纹理从输入到输出没有做任何处理,则会将该图片和被处理之前显示的一样,正如我们所预期的那样。解码函数和display transfer function显示器传输函数相同,这是因为纹理中存储的数值都已经被编码且正确显示。我们不是转换为提供linear-response显示,而是计算得到一个线性数值。
相应的简化版本的display transfer function显示器传输函数与公式5.31相反:
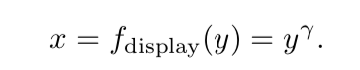
有时候,你会看到一对更简单的转换公式,尤其是在移动和浏览器应用程序上(参考文献[1666]):
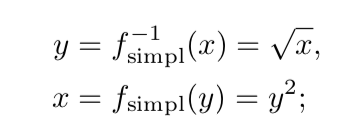
也就是说,取线性值的平方根进行转换用于显示,然后将该值本身相乘以进行逆运算。虽然只是粗略的估计,但是使用这种转换总比完全忽略问题好。
如果不注意gamma的话,实际上相当于会使用一个较低的linear值,会导致屏幕比较暗。一个相应的错误是,由于没有进行gamma矫正,某些颜色的色调会进行偏移。假设r为2.2。我们希望从显示的像素发射出与线形计算值成正比的radiance辐射,也就意味着需要将线性数值提升到power(x,1/2.2)。线性数值0.1会因此变为0.351,0.2变为0.481,0.5变为0.73。如果未编码,按照原来的数值使用,则会导致显示器发出的radiance亮度低于所需要的亮度。需要注意的是,0.0和1.0无论如何转换都不会发生变化。在使用gamma矫正之前,暗的表面通常会被做场景的人人为提亮,然后再会被显示器转换压下来。
忽略gamma矫正还会有一个问题,对于物理线性radiance辐射值计算正确的着色器计算,被用在非线性值上。如图5.40所示。

上图上显示了两个重叠的聚光灯照亮一个平面。左侧的图,针对0.6和0.4的灯光值,在相加的时候没有进行gamma矫正。在非线性值上进行加法操作,导致错误。可以看到,左侧的图中的重叠部分与右侧的相比,异常的明亮。在右图中,这些值在相加的时候进行了gamma矫正。灯光本身的亮度是成比例的,而它们叠加的地方也适当的结合在一起。
忽略gamma矫正也会影响抗锯齿的质量。假如,三角形覆盖了四个屏幕网格单元(如图5.41)。三角形的标准radiance亮度为1(白色),背景为0(黑色)。从左到右,网格单位被覆盖了1/8,3/8,5/8,7/8。如果使用box滤波器,希望得到的像素线性亮度值为0.125,0.375,0.625,0.875。正确的方法是对线性数值进行抗锯齿,然后将显示编码后的结果用于四个结果值。如果不这样做的话,表示的像素亮度将太暗,如图的右侧那样,导致边缘出现了可见的变形。这种现象被称为roping绳索,因为它的边缘看起来有点像一根扭曲的绳子(参考文献[167,1265])。图5.42展示了这种现象。
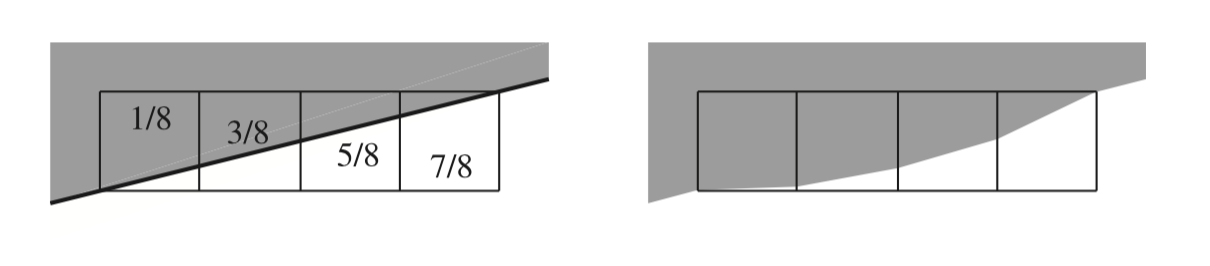
在左侧,四个像素被黑色(显示为灰色)背景上的白色三角形覆盖,真实的显示了覆盖的区域。如果不执行gamma矫正,就会向右侧图那样,中间色调的变暗将导致边缘的感知失真。

左图中,抗锯齿操作进行了gamma矫正,中间,部分进行了矫正,右侧,全部没进行gamma矫正(图片由Scott R.Nelson提供)
sRGB标准创建于1996年,已经成为大多数计算机显示器的标准。然而,显示技术从那时候开始就不断在发展。显示器更亮,且可以显示更广泛的颜色范围。第8.1.3节将讨论色彩显示器和亮度,第8.2.1节将讨论high dynamic range高动态范围显示器的显示编码。Hart的文章(参考文献[672])是特别透彻的讲述了高级显示器的详细信息。
更多资源
Pharr等人(参考文献[1413])更深入的讨论了采样模式和抗锯齿。Teschner的课程笔记(参考文献[1758])展示了各种采样模式的生成方法。Drobot(参考文献[382,383])回顾了之前关于实时抗锯齿的研究,解释了各种技术的属性和性能。最新的SIGGRAPH教程(参考文献[829])包含了大量关于形态学抗锯齿方法的信息。Reshetov和Jimenez(参考文献[1486])回顾了游戏中所使用到的形态学和相关temporal antialiasing的信息。
针对半透明的研究,我们再次推荐读者去阅读McGuire的演讲(参考文献[1182])以及Wyman的工作(参考文献[1931])。Blinn的文章“what is pixel?”(参考文献[169])在讨论一些定义的同时,对计算机图形学的几个领域都进行了出色的说明。Blinn的书Dirty Pixels和Notation,Notation,Notation(参考文献[166,168])包含了一些关于过滤器和抗锯齿相关的介绍性文章,以及关于alpha,compositing合成和gamma矫正相关的文章。Jimenez的演讲(参考文献[836])详细描述了用于抗锯齿的最新技术。
Gritz和d'Eon(参考文献[607])对gamma矫正做了一个很好的总结。Poynton的书(参考文献[1431])对gamma矫正以及其他与颜色相关的主题进行了详细的报道。Selan的白皮书(参考文献[1602])比较新,介绍了display encoding显示编码和它在电影工业中的应用,同时也介绍了很多其他相关的信息。
虽然并非全部原创,但还是希望转载请注明出处:电子设备中的画家|王烁 于 2019 年 7 月 22 日发表,原文链接(http://geekfaner.com/shineengine/Translation5_RealTime_Rendering_4th_Edition1.html)