- 7.1 Planar Shadows
- 7.2 Shadows on Curved Surfaces
- 7.3 Shadow Volumes
- 7.4 Shadow Maps
- 7.5 Percentage-Closer Filtering
- 7.6 Percentage-Closer Soft Shadows
- 7.7 Filtered Shadow Maps
- 7.8 Volumetric Shadow Techniques
- 7.9 Irregular Z-Buffer Shadows
- 7.10 其它应用
- 更多资源
"All the variety, all the charm, all the beauty of life is made up of light and shadow."—Tolstoy。翻译过来就是,生命中的一切多样性、一切魅力和美好,都是来自于光和影。
阴影可以提高图像的真实度,以及可以从视觉上提示对象的放置。本章主要介绍阴影的基本原理,并描述了最重要和最流行的实时算法。我们还简要讨论了一些不太受欢迎但是包含重要原则的方法。在本章中,我们不会花时间讨论所有的方法,因为有两本综合性的书深入研究了阴影(参考文献[412、1902])。相应的,我们讲重点放在调查已发表的文章和演示文稿,然后经过实战来测试这些技术。
图7.1展示了本章所使用的术语。其中occluders遮挡器将阴影投射到reveivers接收器上。Punctual light精准光源,即没有区域的光源,只产生fully shadowed region完全阴影区域,即hard硬阴影。如果使用area或者volume light,则会产生soft软阴影。每个阴影都可以有一个完全阴影区域(umbra本影),和一个部分阴影区域(penumbra半影)。软阴影的阴影边缘是模糊的。但是,需要注意的是,仅适用低通滤波器模糊硬阴影的边缘通常无法正确渲染它们。(Patrick:然而其实一般都会这么做来造假吧。还有一种做法就是王者荣耀那样,详见Unity平面阴影(王者荣耀阴影实现),也是造假。)如图7.2所示,正确的软阴影的做法是,当遮挡器越接近接收器的时候,阴影越尖锐。软阴影的本影区域不等同于由punctual light生成的硬阴影。其实软阴影的本影区域随着光源的增大而减小,如果光源足够大,接收器距离遮挡器足够远,它甚至可能没有本影。大家更喜欢软阴影,因为其半影边缘更容易让观众知道,它确实是个阴影。而硬阴影通常看起来不太真实,优势会被误解为是实际物件的几何特征,比如曲面上的折痕。但是,硬阴影的渲染速度比软阴影快。

上图展示了阴影方面的术语,light source光源,occluder遮挡器,receiver接收器,shadow阴影,umbra本影,penumbra半影。

上图中既有硬阴影也有软阴影。箱子的阴影是尖锐的,因为遮挡器靠近接收器。人的阴影在接触点是尖锐的,随着与遮挡器的距离增加而软化。远处的树枝投射柔和的阴影(参考文献[1711])(图片来自育碧公司的"Tom Clancy's The Division")。
比半影更重要的是,需要有阴影。如果没有阴影作为视觉提示,场景往往无法令人信服,也难以感知。正如Wanger所展示的(参考文献[1846]),通常情况下,拥有一个不准确的阴影,比没有阴影好,因为眼睛对阴影的形状是相当宽容的。例如,在地面上绘制一个黑色的圆圈,就可以将角色固定到地面上。
在下面的部分,我们将跳过这些简单的建模阴影,而介绍场景中自动实时根据遮挡器计算阴影的方法。第一节,将处理在平面上投射阴影的特殊情况,第二节,将讨论更通用的阴影算法,也就是在任意曲面上投射阴影。硬阴影和软阴影都将被涉及到。最后,将提出一些适用于各种阴影算法的优化技术。
7.1 Planar Shadows
阴影中有一种简单的形式,就是将物件投射到平面上。本节介绍了几种平面阴影的算法,每种算法在阴影的柔和度和真实性方面都有所不同。
7.1.1 Projection Shadows
在这种方案中,3D对象会被多渲染一次以生成阴影。可以通过一个矩阵,将物件上的顶点投射到平面上(参考文献[162、1759])。如图7.3中,光源的位置在l点处,将顶点v进行投影,投影到点p处。我们将导出阴影平面y=0时的投射矩阵,然后将此结果推广到任何平面上。
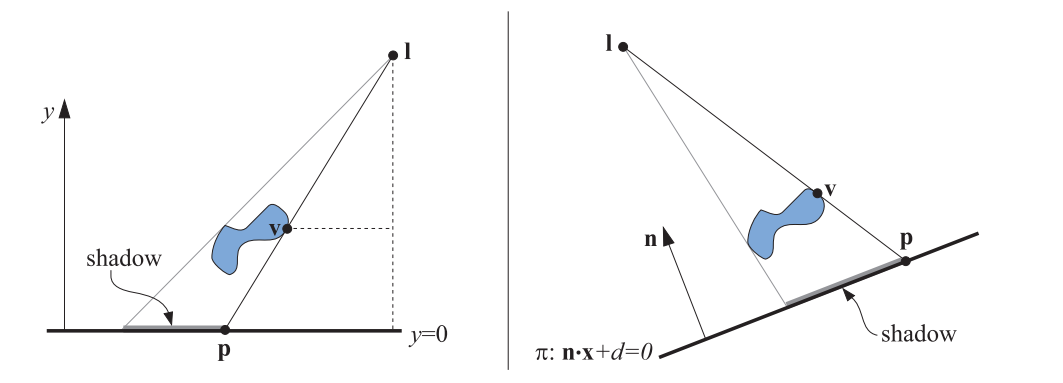
上图中的左侧,可以看到一个光源位于l点,将阴影投影到y=0平面上。点v被投影到平面上,被投影的点为点p。相似三角形是用于推导投影矩阵的。上图中的右侧,阴影被投射到一个平面上,Π:n*x+d=0。
我们先导出x坐标的投影,从图7.3左边的相似三角形中,我们得到

同样的,可以导出z坐标的投影:Pz = (lyVz - lzVy) / (ly - Vy)。而y坐标为0。这些方程可以转换成投影矩阵M
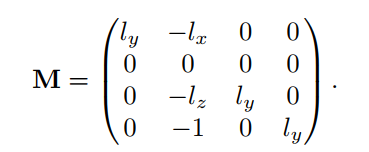
很容易可以验证MV=P,这意味着M确实是投影矩阵。
在一般情况下,阴影应该投射的平面并非平面y=0,而是Π:n*x+d=0。图7.3的右侧部分描述了这种情况。我们的目标是再次找到一个将v投影到p的矩阵,为此,在l处发出的射线穿过v,与平面Π相交。这就得到了投影点p:
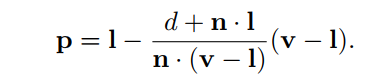
该方程也可转换成投影矩阵,如公式7.4所示,该矩阵也满足MV=P。
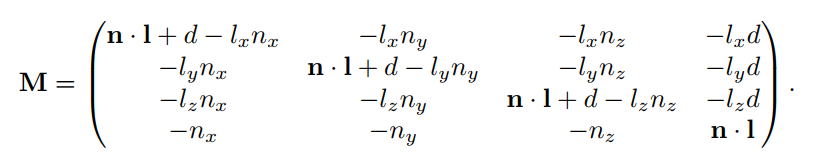
如预期那样,如果平面为y=0,即n=(0,1,0),d=0,该矩阵也可以转换为公式7.2中的矩阵。
当渲染阴影的时候,只需要将此矩阵应用到在平面Π投影的对象,并用深色和无照明渲染该投影对象即可。实际上,必须采取措施来避免在接受阴影的平面Π下面渲染阴影。一种方法是在计算矩阵的时候,给投影平面Π加一些偏移,以便阴影三角形始终在平面Π前面渲染。
还一个更安全的方法,是先绘制地面,然后关闭z-buffer绘制阴影,然后再正常渲染其他物件。由于在绘制阴影的时候没有深度比较,所以影子始终绘制在平面上。
如果地平面有边界,比如,它是一个矩形,那么阴影有可能会落在它的外面,这样就会影响视觉效果。为了解决这个问题,可以使用stencil-buffer。首先,将接收器渲染到屏幕和stencil-bffer中,然后将z-buffer关闭,仅在绘制接收器的地方绘制阴影,然后再正常渲染场景的其余部分。
另外一种阴影算法是将三角形渲染为纹理,然后将其应用在地平面上。该纹理是一种光照贴图(详见11.5.1节)。这种将阴影投影到纹理上的想法也支持半影和投影到曲面上。这种技术的一个缺点是纹理可以被放大,这样一个纹素就覆盖多个像素,会导致阴影在视觉上出错。
如果两帧之间阴影相关的因素没有发生变化,也就是灯光和投射阴影的物件是相对静止的,那么可以重用shadowmap。大多数阴影结束都可以由于重用阴影中间计算结果来获益。
所有产生阴影的物件应该位于灯光和地平面接收器之间。如果光源低于对象的最顶端,则会出现antishadow(参考文献[162]),因为每个顶点都将通过光源点投影。正确的投影和antishadow反阴影如图7.4所示。如果投射阴影的物件在接收器下面也会出错,因为它不应该产生阴影。

左侧,为正确的阴影,右侧,由于光源位于对象最顶部顶点的下方,因此出现了antishadow
通过显式的cull和修建三角形可以避免这种情况。下面介绍一种更简单的方式,通过现有的GPU管线来执行带剪裁的投影。
7.1.2 软阴影
投影阴影也可以通过各种技术使其变软。在这里,我们描述了Heckbert和Herf(参考文献[697、722])提出的一种产生软阴影的算法。该算法是生成一个纹理以显示软阴影。后面,我们还会描述一些精度低一些,但是速度更快的方法。
当使用area light的时候,就会出现软阴影。一种近似的方法,是使用几个精准光源,对于其中的每一个,在buffer中渲染一张阴影,然后将这些阴影取平均,就会得到一张具有软阴影的图像了。理论上,任何产生硬阴影的算法都可以使用此累计技术生成半影。但实际上,这样做因为消耗太大,所以不太可取。
Heckbert和Herf使用基于frustum的方法来产生阴影。思想是将光视为观察者,地平面为frustum的远裁剪面。frustum足够大,可以包下遮挡物。
通过生成一系列地平面纹理,形成一个软阴影纹理。area light通过自身的若干点将遮挡物投影到图像上。然后将这些图像求平均来生成地平面阴影纹理,参见图7.5的左侧。
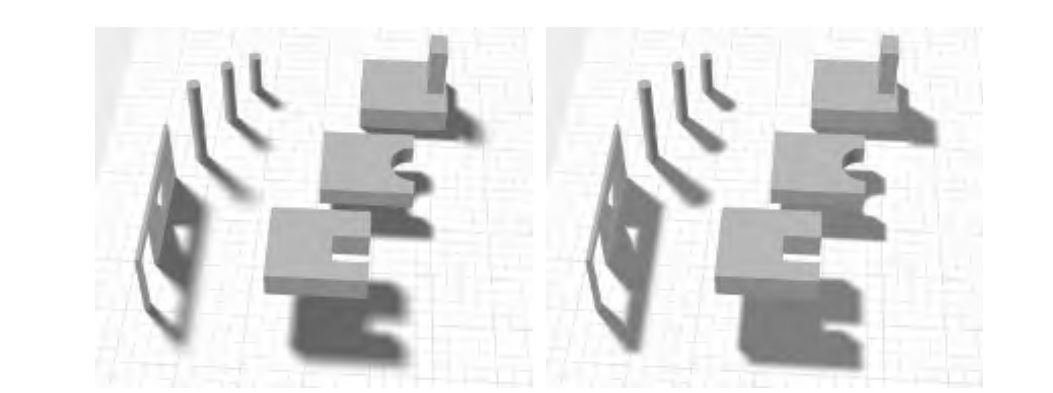
上图中的左侧,使用Heckbert和Herf的方法进行渲染,共使用了256个pass。右侧为Haines的方法,只用了一个pass。然而用Haines的方法,本影太大了,特别是在门口和窗户周围。
上述办法的一个缺点是,它看起来像是若干精准光源的阴影重叠。对于n个pass,只会生成n+1个不同的阴影。大量的pass可以得到精确的结果,但是代价太大了。这种方法可以用于获得“基本真实”的阴影图像,以测试其他更快算法的质量。
一种更有效的办法是使用卷积,比如滤波。在大部分情况下,将单点生成的硬阴影进行模糊即可,这样还可以生成半透明纹理,与场景进行融合。见图7.6。但是,在物件接近地面的位置附近,均匀模糊可能就无法令人信服。

Drop shadow。上图从上方将阴影投射下来,然后将阴影模糊并渲染在地平面上。(图像由Autodesk的A360 viewer中生成,模型来自Autodesk的Inventor示例)
还有其他方法以更高的成本提供更好的近似。比如,Haines(参考文献[644])先投射硬阴影,然后对轮廓边缘使用渐变的方法,渐变从中心的黑色到边缘的白色,以创建合理的半影。参见图7.5的右侧。但是,这些半影在物理上不正确,因为它们也应该延伸到轮廓边缘内的区域。Lwanicki(参考文献[356、806])借鉴了球谐的思想,使用ellipsoids来近似遮挡物,来产生软阴影。所有这些方法都有各种各样的近似度和缺点,但肯定都比对一组阴影取平均性能好。
7.2 Shadows on Curved Surfaces
将平面阴影的概念扩展到曲面的一个简单方法是使用生成的阴影图像作为投影纹理(参考文献[1192、1254、1272、1597])。从灯光的视角来计算阴影。从灯光位置触发,能看见的地方在亮处,看不见的都在暗处。绘制阴影纹理的时候,将由遮挡器的地方绘制成黑色,其它地方为白色。然后将该纹理投影到要接收阴影的曲面上。然后,接收器上的每个顶点都有一个对应的(u、v)纹理坐标,用于接收阴影纹理。这些纹理坐标可以通过应用程序显式计算。与上一节中“地面阴影”纹理稍有不同,上一节中纹理将对象投影到特定的物理平面上。而在这里,纹理是从光出发的视图。
渲染时,将阴影纹理作用在接收器曲面上。还可以与其它阴影方法相结合,有时主要用于帮助感知对象的位置。例如,在一些游戏中,即使角色完全处于阴影中,也可能会在其正下方给气添加阴影(参考文献[1343])。更精细的算法可以给出更好的结果。例如,Eisemann和Decoret(参考文献[1343])假设了一个矩形顶灯,并创建了一个阴影图像堆栈,然后将其转换为mipmap或者类似的图像。通过使用mipmap,每层堆栈的对应区域与它与接收器的距离成比例的访问,这意味着接收器越远,显示的阴影越柔和。
(Patrick:这个厉害了,通过这种多层mipmap的加权和做法,可以实现半影,且接收器和遮挡器的距离越远,半影越大。)纹理投影的方法存在一些严重的缺陷。首先,应用程序必须明确的知道哪些对象是遮挡器,哪些是接收器。应用程序必须确保接收器比遮挡器离光更远,否则阴影将出现“反向投射”。此外,遮挡对象不能遮挡自身,也就是不支持自阴影。接下来的两部分将介绍无需上述这些限制的更正确的阴影算法。
可以通过预先构建的图案来产生各种照明图案。聚光灯只是一个正方形的投影纹理,其内部有一个圆来定义灯光。百叶窗等可以通过水平线组成的投影纹理创建。这种类型的纹理被称为light attenuation mask光衰减遮罩、cookie纹理、gobo map。通过简单的将两个纹理相乘,则可以将预先构建的图案与动态创建的投影纹理相结合。第6.9节中也讨论了这些灯。
7.3 Shadow Volumes
Heidmann(参考文献[701])在1991年提出了一种基于crow的shadow volume(参考文献[311]),可以巧妙的利用stencil buffer将阴影投射到任意对象上。该方案可以在任意GPU上使用,唯一的要求就是有stencil-buffer。它不是基于图像的(不像下面描述到的shadow map算法那样),因此避免了采样纹理,所以,可以在任何地方都产生正确的sharp阴影。当然这恶可能也是一个缺点。比如,角色的衣服可能会有褶皱,这些褶皱就会产生很薄但是很硬的阴影,这些阴影可能会有严重的锯齿。由于其成本不可预测,所以今天这个技术已经很少使用了(参考文献[1599])。我们在这里会对这个算法进行简单的描述,因为它其中涉及到很多重要的原理,基于这些原理的研究至今依然在继续。
首先,想象一个点和三角形。将点和三角形的三个顶点连接起来,再延伸到无穷远,形成一个无限大的三边金字塔。在三角形下面的部分,是一个截锥,三角形上面,还是一个三边金字塔。如图7.7所示。现在,假设这个点实际上是一个点光源。那么位于截锥体内部的对象,就可以被认为是在阴影里面了。这个截锥体被称为shadow volume。

上图中的左侧:从点光源发射射线,通过三角形的顶点进行延伸,形成一个无限大的金字塔。右侧可以看到,上面是一个金字塔,下面是一个截锥,也称为shadow volume。shadow volume内的所有几何体都处于阴影之中。
当我们看场景中某个物件的时候,假设从眼睛发射一条射线,射向要显示到屏幕上的对象。当光线在到达该对象之前,每次穿过shadow volume的正面(面向观察者的一面)时,我们把引用计数加一,当光线离开shadow volume(也就是传过截锥的背面)的时候,将引用计数减一。直到射线击中对象。此时,如果计数器大于0,则该像素位于阴影中,否则,不在阴影总。当有多个三角形投射阴影的时候,这个原则也使用。见图7.8。

上图展示了使用两种不同计数方法计算shadow volume的二维侧视图。在z-pass计数中,当射线通过shadow volume的正面时候,计数加一,当射线离开的时候,计数减一。因此,在点A,射线进入了两次shadow volume,+2,然后离开了两次shadow volume,-2,所以得到计数为0,因此该点在光线中。在z-fail的算法中,从物体表面发射线(图中计数以斜体显示)。在点B,以Z-pass的方法通过两个正面shadow volume,计数+2。z-fail通过两个背面三角形,得到相同的计数。在点C,以Z-fail的方式计数,从点c触发,首先击中shadow volume的正面,得到-1,然后退出两个shadow volume(从shadow volume的底部退出,这是z-fail所特有的),最终计数+1。计数不为0,所以点在阴影中。两种方法始终对物体上的点,给出相同的计数结果。
使用射线做这个事情会很耗。有一个更简单的方案(参考文献[701]):使用stencil buffer来计数。第一步,清空stencil buffer。第二步,将整个场景绘制到framebuffer上,将unlit的信息绘制到color buffer上(Patrick:此时可也可以进行间接光的绘制),深度绘制到z-buffer上。第三步,将z写入和color写入都关闭(z-test打开),绘制shadow volume的正面,在此过程中,stencil 操作被设置为,当渲染像素通过ztest的时候,增加stencil值。第四步,和第三步类似,绘制shadow volume的背面,在此过程中,stencil 操作被设置为,当渲染像素通过ztest的时候,减小stencil值。注意,这里的渲染都要确保ztest通过,也就是shadow volume没被真实几何体挡住时,才进行递增和递减。此时,stencil buffer中保存了屏幕空间每个像素的阴影状态。最后,再次渲染整个场景,此次将stencil 为0的像素绘制出来。值为0,表示射线进出shadow volume的次数相同,也就是该位置由灯光照亮。
这种计算方法是shadow volume背后的基本思想。图7.9为使用shadow volume算法生成的阴影。有很多方法可以在一个pass中实现该算法(参考文献[1514])。然而,假如相机位于shadow volume中的话,计数就会出问题。相应的z-fail算法就被提出来,使用物件后面的射线,而非物件前面的射线进行计数(参考文献[450、775])。图7.8也对该方案进行了展示。

上图显示了shadow volume。左侧的角色投射阴影。右侧,显示了模型的三角形被拉伸。(图片来自Microsoft SDK的sample “shadow volume”[1208])
为每个三角形创建对应的shadow volume会产生大量的overdraw。也就是说,每个三角形都将创建三个必须渲染的四边形。一个由一千个三角形组成的物件会产生三千个四边形,而这些四边形中的每一个都可能占满全屏。一种解决方案是只沿着物体的轮廓边缘绘制四边形,比如,我们的物件可能只有50个轮廓边缘,因此只需要50个四边形。geometry shader可被用于自动生成此类轮廓边(参考文献[1702])。cull和clamp技术也可用于降低消耗(参考文献[1061])。
然而,shadow volume依然有一个可怕的缺点:性能特别不可控。想象一下,如果相机和灯光位置相同,则shadow volume的消耗最小。因为shadow volume形成的四边形不会覆盖任何像素,因为它们都与视线平行。而当相机远离光源的时候,shadow volume的四边形变得可见,并覆盖更多的屏幕,从而产生更多的计算。如果观察者进入shadow volume中,shadow volume将覆盖整个屏幕,就需要大量的时间来渲染。这种性能的不可控性使得shadow volume在交互应用程序中不可用,因为在交互应用程序中,稳定的帧率非常重要。由于上述情况,可能会导致算法成本不可预测的跳跃。
由于这些原因,应用程序在很大程度上放弃了shadow volume。然而考虑到访问GPU数据的方法不断发展,以及研究人员对这些功能的巧妙重新利用,shadow volume可能有一天会重新得到普遍使用。例如,Sintorn et al.(参考文献[1648])针对shadow volume提出了分层加速结构以提高效率。
下面要介绍的这个算法,shadow map,成本更可控,而且非常适合GPU,因此在很多应用中被用于阴影的生成。
(Patrick:关于shadow volume的具体实现,可以参照这篇文章阴影锥(shadow volume)原理与展望---真实的游戏效果的实现)7.4 Shadow Maps
1978年,Williams(参考文献[1888])提出了一种基于z-buffer的渲染方案,可以用于对任意对象快速生成阴影。其思想是在投射阴影的光源位置渲染场景,记录下Z值。光能看到的地方被照亮,其余部分都在阴影中。这里值需要记录z-buffer即可。此时可以关闭color-buffer的写入。
z-buffer中的每个像素包含了物件和光源的距离。我们将z-buffer称为shadow map,也可以被称为shadow depth map或者shadow buffer。然后,场景会被再渲染一次,这次使用观察者的视角。渲染时的每一个图元,会将其通过转化,得到其在光源空间的坐标,以及距离光源的距离,与shadow map中的对应点进行比较。如果当前渲染点的距离更远,说明该点位于阴影中,否则反之。该技术通过纹理映射实现。如图7.10。shadow map是一种流行的算法,因为它相对可预测。构建shadow map的成本与渲染的物件数量线性相关,而采样shadow map的时间是恒定的。如果灯光和对象不移动,则shadow map可以只生成一次,之后则可以一直使用该图片。(Patrick:做好阴影动静分离后,静态部分可以这么搞)
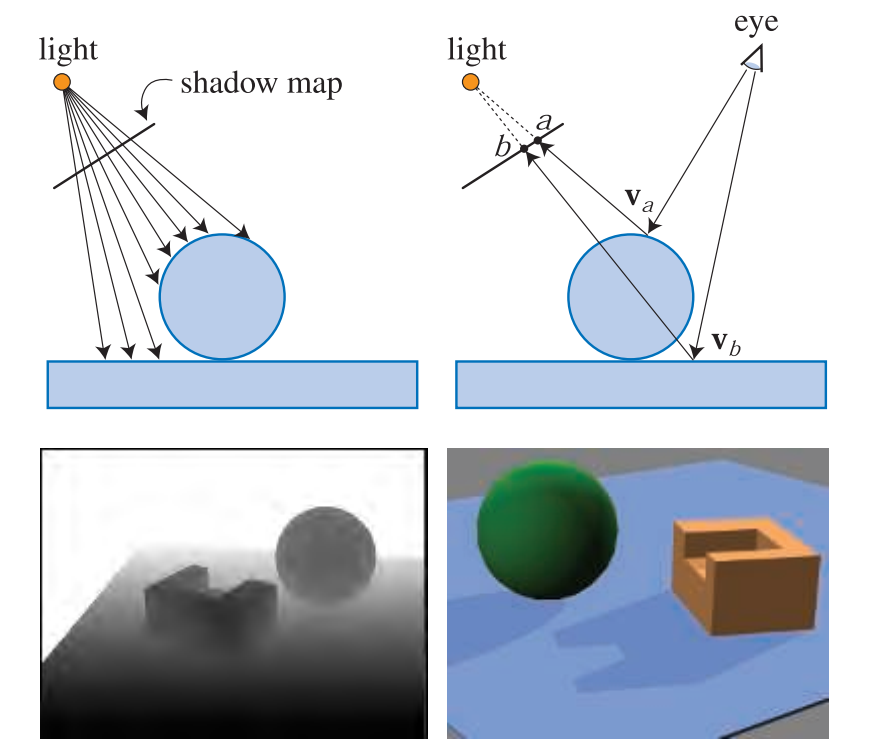
上图展示了shadow map。在左上角,将光线空间视图中的对象深度保存下来作为shadow map。在右上角,通过眼睛观察两个位置。可见点Va,并将其映射到shadow map的a处。存储在a处的深度不小于Va和灯光之间的距离,因此该点被照亮。可见点Vb,对应shadow map中的b点,而存储在b处的深度小于Vb和灯光之间的距离,所以Vb在阴影中。左下图,展示了灯光视图看到的场景深度,白色代表着距离更远。右下图是使用shadow map渲染的场景。
当绘制shadow map的z-buffer的时候,光线只能沿着一个特定的方向,就好像摄像机一样。对于遥远的平行光(比如太阳),灯光的视图要设置为包含所有能将阴影投射到眼睛观察物件上的对象。灯光使用正交投影,其视图需要在x和y方向上足够宽和高,才能完整的看到这组对象。如果局部光照距离遮挡物足够远,则视椎体内可能足以包含所有这些遮挡物。或者,如果局部光照是聚光灯,则有一个与其关联的圆锥体,其圆锥外面的东西都被视为未被照亮。
如果局部光源位于场景内部,并被遮挡物包围,典型的解决方案是使用6-view cube 六视图立方体,类似于cubic environment mapping立方体环境贴图(参考文献[865])。这些被称为omnidirectional shadow map全向阴影贴图。全向阴影贴图的主要问题是避免在两个独立场景接缝处出现伪影。King和Newhall(参考文献[895])深入分析了问题并提出了解决方案。Gerasimov(参考文献[525])提供了一些实现细节。Forsyth(参考文献[484、486])提出了一种multi-frustum多截锥分区方案,用于全向光,并在需要的地方提供了更多shadow map分辨率的选择。Crytek(参考文献[1590、1678、1679])根据每个视图投影截锥体所覆盖屏幕空间的大小,设置点光源六个视图中每个视图的分辨率,并将所有纹理保存在texture atlas中。
并非场景中所有对象都需要渲染到shadow map中。首先,只需要渲染可以投射阴影的对象即可。例如,如果已知地面只能接收阴影而不能投射阴影,则不必将其渲染到阴影贴图中。
在灯光视椎内的被定义为阴影投射器。视椎体可以通过几种方式来放大或缩小,这样就可以忽略一些阴影投射器(参考文献[896、1812])。想一想眼睛可以看到的阴影接收器,这组对象定义了灯光视图方向的最大距离。任何超过这个距离的物体都不可能在可见接收器上投射阴影。类似的,可见接收器的集合可能小于光源view bound的x和y。如图7.11。还有一个例子,如果光源在眼睛的视椎内,光源视椎体外的任何对象都不能在接收器上投射阴影。仅渲染相关对象不进可以节省渲染时间,还可以减小光源视椎体的大小,从而提高阴影贴图的有效分辨率,从而提高阴影质量。或者,如果将视椎体的near plane尽可能远离光源,或者将far plane尽可能拉近,都可以提高z-buffer的有效精度(参考文献[1792])(详见4.7.2),从而提升阴影质量(Patrick:这个厉害了,另外关于Z-buffer的精度,经典的reserved-z也可以解决,原理可以参考反向Z(Reversed-Z)的深度缓冲原理。结论就是,如果没有reserved-z,整形的z分布比浮点型的z分布稍微好一点,而用了reserved-z后,整形的没区别,浮点型的z分布大幅度均匀了,因为浮点型0.0附近的精度高,1.0附近的精度低,关于这个论点,可以参考另外一篇文章浮点数的范围和精度问题(从原理到结论))
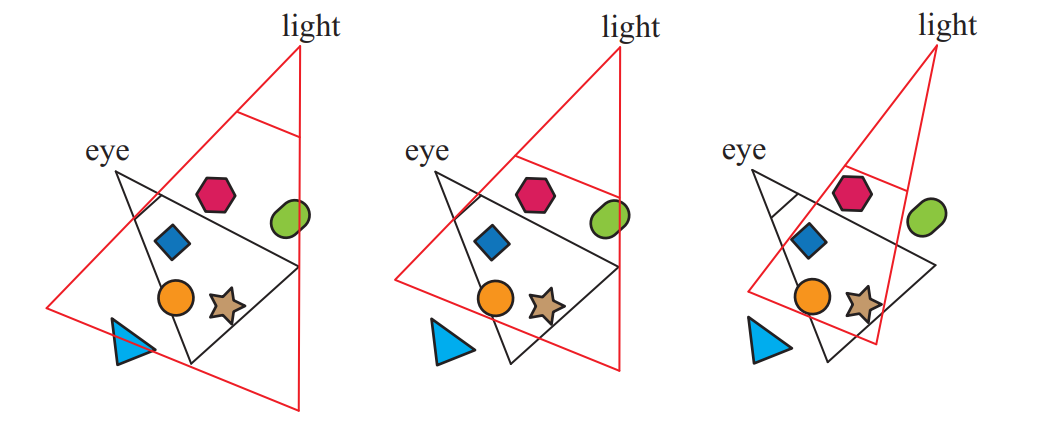
上图中的左侧,灯光的视椎体包含了眼睛的视椎体。中间,光源的far plane被拉近,只包含可见的接收器,三角形不再被当做阴影投射器,near plane也被调整了。右侧,光源的视椎体侧面被调整后紧贴可见的阴影接收器,将绿色的胶囊剔除了出去。
shadow map的一个缺点是阴影的质量依赖于shadow map的分辨率和z-buffer的数值精度。由于shadow map是通过depth对比获取到的,所以该算法容易受到锯齿的影响,特别是靠近对象之间的接触点。一个常见的问题是自阴影锯齿,通常被称为surface acne或者shadow acne,其中三角形被错误的认为是阴影本身。这个问题有两个源头。一个是处理器精度的数值限制,另外一个是来自于geometric,因为一个点样本的值被用来表示一个区域的深度。也就是说,生成shadow map时所使用的样本几乎从不与屏幕样本位于同一位置。将灯光存储的深度值与物体的深度进行比较的时候,shadow map的值可能略低于物体,从而导致自阴影。这些误差的影响如图7.12所示。

上图展示了shadow map bias技术。左侧,bias太小,产生了自阴影。右侧,bias太大,导致鞋子和阴影不接触了。shadow map的分辨率也太低,以至于出现块状。(图片来自Christoph Peters的shadow demo)
避免(而非消除)shadow map伪影的一个常见方法就是引入bias factor。当根据接收器位置去采样shadow map的时候,将采样的值减去一个小的bias。如图7.13。这个bias可以是一个恒定值(参考文献[1022])。但当接收器基本不面向光的时候,这样做可能会失败。更有效的办法是根据接收器与光的角度为比例,使用一个非恒定bias。越是表面倾斜远离光,bias越大,就可以避免这个问题。这种类型的bias被称为坡度比bias。这两种bias,都可以通过命令(比如OpenGL的glPolygonOffset),将每个多边形移离灯光。需要注意,如果表面直接面向灯光,则它根本不会因坡度比例偏移而向后偏移。由于这个原因,一个恒定的bias与坡度比例bias一起使用,以避免可能的精度误差。坡度比bias通常也被限制在某个最大值处,否则当坡度倾斜度与光线方向达到一定程度的时候(比如坡度倾斜度与光线方向接近平行的时候),这个坡度比可能会非常大。

上图展示了shadow bias。物体表面将针对一个顶灯渲染出一张shadow map,垂直线表示shadow map的像素中心。遮挡器的深度被记录在了x位置。我们想知道三个采样点是否被照亮。这三个点对应shadow map中最接近的点,被显示为相同颜色的x。在左侧,如果未添加任何bias,则蓝色和橙色采样会被错误的认为是在阴影总,因为它们与灯光的距离比相应shadow map中的距离更远。在中间,将每个采样点减去一个恒定的bias,使得采样点更靠近灯光。但是蓝色点依然被认为是在阴影中,因为它与灯光的距离比shadow map更远。在右侧,shadow map是通过将每个多边形根据坡度光线比移动。所有的采样点深度现在都比shadow map中更近了,也就是所有采样点都被照亮了。
(Patrick:所以坡度比bias需要NDoL算bias吧?恒定bias就是depth bias。)Holbert(参考文献[759、760])引入了normal bias,将接收器的世界空间位置沿法线移动了一点,与光的方向和几何法线之间的角度的正弦值成正比(Patrick:坡度比bias与光线有关系,normal bias与光线就没关系了吧。)如图7.24。这不仅改变了深度,还改变了shadow map上测试样本的x和y坐标。随着光线与表面的夹角越小,这种bias还会增加,已达到样本偏移的足够远,来达到避免自阴影的目的。这个方法可视为将样本移动到接收器上方形成虚拟表面。这个bias是世界空间距离,因此Pettineo(参考文献[1403])建议按shadow map的深度范围来缩放它。Pesce(参考文献[1391])提出了沿相机视图方向偏移的想法,这也可以通过调整shadow map坐标来实现。第7.5节还讨论了其他bias的方法,因为该节中计算阴影的方法还需要采样几个相邻的样本。
如果bias过大,则会出现一个被称为light leaks光泄漏或者peter panning的问题,在这问题中,对象看起来漂浮在地面之上。这种伪影的产生是因为物体接触点下面的区域,比如一只脚下面的地面,被向前偏移的太多,所以没有阴影。
避免自阴影问题的另一种方法是仅将backfaces渲染到shadow map中。这种方案被称为second-depth shadow map(参考文献[1845]),该方案在许多情况下都能很好的工作,特别是无法进行手工调整bias的渲染系统中。当对象是双面的、薄的或者彼此接触时,就容易出现自阴影。比如树叶或者一张纸这种双面渲染的物件,因为背面和正面位置相同,就容易出现自阴影。类似的,轮廓边缘或薄的对象,如果不做bias,也很容易出现自阴影,因为背面和正面很近。增加bias有助于避免surface acne,但是该方案容易漏光,因为接收器和遮挡器的背面在接触点之间的地方是没有分离的。如图7.14。选择哪种方案需要取决于具体情况。例如,Sousa等人(参考文献[1679])法线,针对太阳阴影,使用frontface,对内部灯光使用backface,这样最适合它们的项目。
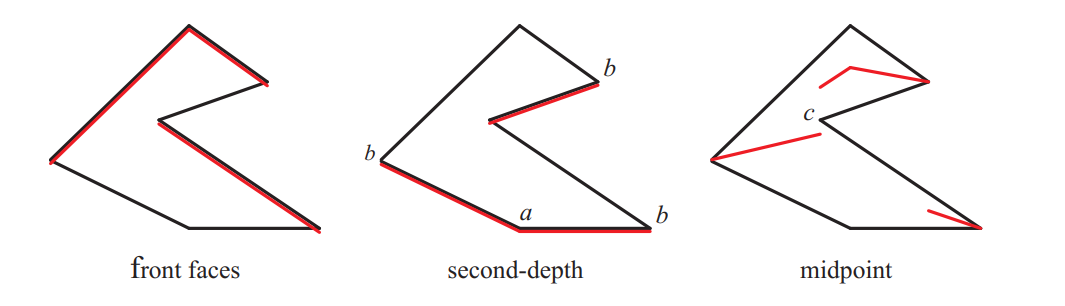
上图展示了头顶光源的shadow map。左侧,使用面向灯光的表面(用红色标记)绘制shadow map,这样表面可能会出现自阴影(acne),所以需要相对灯光做bias。中间,使用backface渲染shadow map。如果向下偏移这些遮挡器,可能会使得光线泄漏到位置A附近的地平面上,而向上偏移,可能会使得B附近的轮廓边界被认为是在阴影中(实际是在光照中)。在右侧,根据光照空间,距离灯光最近的一条边和第二近的一条边,取中间位置生成一条辅助线,通过这条辅助线来生成shadow map。但是看C点,可能C点在shadow map中的对应点在左侧的辅助线上,那么C可能也会出现漏光现象。(该情况在中间方案中也会出现)
对于shadow map,渲染的对象必须是watertight“不透水的”(manifold流行闭合的,比如solid实体,详见16.3.3),否则必须将正反面都渲染到shadow map上,否则对象可能不会完全投射阴影。Woo(参考文献[1900])提出了一个通用方法,在正面和背面中取一条线用于投射阴影。大致思想是根据距离灯光最近的两个曲面计算出一个辅助线用于投射阴影。(Patrick:也就是上图中的右侧。)词构成可以通过depth peeling或者其他半透明相关的技术。将两个面之间形成一个中间层,其深度用作shadow map,有时也被称为dual shadow map(参考文献[1865])。如果对象足够厚,则会最小化自阴影和漏光的问题。Bavoil等人(参考文献[116])讨论了address potential artifact的方法,以及其实现细节。主要缺点是渲染了两次shadow map。Myers(参考文献[1253])讨论了在遮挡器和接收器之间艺术家控制一个深度层。
当观察者移动的时候,光源的视椎体通常会根据遮挡器的变化而变化。这样会导致shadow map在一帧到另一帧之间稍微移动。对于平行光,解决方案是强制生成的shadowmap中,每个纹素对应固定的世界空间中的位置(参考文献[927、1227、1792、1810])。也就是说,可以想象一下,将shadow map映射到整个世界的二维网格,每个网格对应shadow map上的一个像素。移动的时候,将这些相应网格的不同集合合成shadow map。换句话说,固定光的视图投影,以保证帧与帧的连贯性。
(Patrick:说了一大串,真的没读明白。其实原理很简单,就好比阴影动静分离的做法,绘制静态物件的时候,可以不用每帧绘制,当相机移动N米之后,绘制一次,然后期间用同一个shadow map即可。为什么要移动N米再绘制呢,以为移动N米又多了一些遮挡物,如果没多遮挡物,移动再远都不用重新绘制shadow map)7.4.1 Resolution Enhancement
与使用纹理类似,理想情况下,我们希望shadow map中的一个纹素与屏幕上的一个像素一一对应。如果光源和眼睛位于同一位置,shadow map将于屏幕空间像素完美的一一映射(此时没有可见阴影,因为光线正好照亮了眼睛看到的东西)。一旦光的方向改变,这个比例就会改变,出现伪影。如图7.15所示。阴影是块状的并且也不准确,这是因为屏幕上前景部分的多个像素对应shadow map中的一个纹素。这种不匹配被称为perspective aliaing。如果曲面几乎与光线平行,且面向观察者,也会出现这种多个像素对应shadow map中一个纹素的情况,这种被称为projective aliasing(参考文献[1792])。如图7.16。通过提高shadow map的分辨率可以降低这种块状问题,但是需要额外的内存和计算。

上图中的左侧,使用标准shadow map,右侧使用的是LiSPSM创建。两个shadow map使用相同的分辨率,不同之处在于LiSPSM对灯光矩阵进行了改变,更接近观察者的地方提供了更高的采样率。(图片由Vienna理工大学,Naniel Scherzer提供。)
(Patrick:PSM居然效果那么好,要试下。PSM沿用Shadow Map的基本思想。为了解决Shadow Map精度问题,对Depth Pass的变换矩阵做做手脚。)
上图中的左侧,灯光几乎在头顶。shadow map的边缘部分的纹素,对应屏幕的像素,比起来shadow map的分辨率较低,所以在阴影边缘有点参差不齐。而在右边,光线接近地平线,因此shadow map的一个纹素对应多个屏幕中的像素,因此边缘锯齿更明显。(图片来自于Github上The Real MJP's shadow)
有另一种方法可以将灯光的sample pattern采样模式,更接近相机的pattern模式。这是通过改变场景向灯光投射的方式完成的。通常我们认为视图是对称的,视图向量在截锥的中心。其实,视图向量仅定义了一个视图平面,而非哪些像素会被采样。截锥体其实可以在这个平面上移动、skewed倾斜或者旋转,创建一个具备不同世界到视图影射的quadrilateral四边形。该四边形仍然按照固定间隔采样,因为这是线性变化矩阵的特质并被GPU使用。采样率可以通过改变灯光的视图方向和视图窗口的边界来改变。如图7.17。

对于顶灯,上图中的左侧中,地板的采样率与眼睛的采样率不匹配。通过上图中右侧改变灯光的观察方向以及投影窗口,采样率在眼睛附近具有更多shadow map纹素。
将灯光的视图映射到眼睛的视图有22个自由度(参考文献[1792])。对于这方面的研究引发了几种不同的算法,使得光线视图的采样率可以与眼睛视图的采样率更好的匹配。这些方法包括perspective shadow map(PSM)(参考文献[1691])、trapdezoidal shadow map(TSM)(参考文献[1132]),以及light space perspective shadow map(LiSPSM)(参考文献[1893、1895])。如图7.15和7.26所示,这些技术被称为perspective warping方案。
这些matrix-warping算法的一个优点是,除了修改光的矩阵之外,不需要做额外的工作。上述的每种算法都有优缺点,在适合某些光照和场景采样率的同时,针对其他的情况可能会有恶化。Lloyd等人(参考文献[1062、1063])对PSM、TSM、LiSPSM进行分析,对这些方法的采样率和锯齿问题进行了概括。当光照垂直于观察者视角的时候(例如顶光),这些方案最有效,因为perspective transform会在观察者的近处使用更多采样点。
当光线在摄像机前并照向摄像机的时候,使用上述matrix-warping方案就不适合了。这种情况被称为dueling frusta或者更通俗的称为"deer in the headlights"。靠近眼睛的地方需要更多的shadow map纹素,但是linear warping只会使得情况更糟(参考文献[1555])。除此之外,还有阴影质量突然变化(参考文献[430]),以及随着相机运动,产生阴影质量不稳定(参考文献[484、1227])等问题,使得上述这些方法不太受欢迎。
然而,在观察者附近添加更多的采样点,这个思路是好的,所以引入了给视图生成多张shadow map的算法。Carmace在Quakecon 2004中第一次提出了这个观点。Blow独立实现了这样的一个系统(参考文献[174])。这个思路很简单:针对场景的不同区域,生成一组shadow map(可能分辨率不同)。在Blow的方案中,观察者附近一共使用了4个shadow map。这样就可以针对附近的物件使用高分辨率shadow map,远处的物件使用低分辨率。Forsyth(参考文献[483、486])提出了一个相关的想法,为不同的可见对象集生成不同的shadow map。他的方案,避免了跨越两个shadow map对象的边界过度处理问题,因为每个对象都有且只有一个shadow map与其关联。Flagship studios开发了一个系统,融合了这两个想法。一个shadow map用于近处的动态对象,一个用于近处的静态对象,还一个用于整个场景中的静态对象。第一个shadow map每帧都会生成,剩下的两个,只会在当光线和物体发生变化的时候,重新生成一次。上述的这些系统,现在看起来都已经很古老了,为不同的对象和情况绘制不同的shadow map,部分是预计算的,部分是动态的,是现在算法的一个主要方向。
2006年,Engel(参考文献[430]),Lloyd等人(参考文献[1062、1063])以及zhang等人(参考文献[1962、1963])独立研究了类似的方案(Tadamura等人(参考文献[1735])在七年前也提出了这个想法,但直到其他研究人员发现它的有用性,它才产生了影响)。将视椎体平行于视图方向分成几块。如图7.18。随着深度加深,每个volume的深度范围大概是前一个volume的2-3倍(参考文献[430、1962])。针对每个volume,光源可以制作一个frustum并生成shadow map。通过使用texture atlas或者texture array,可以将不同的shadow map视为一个texture,从而最小化cache访问的延迟。图7.19可以看到由此带来的质量改进。Engel对该方法命名为cascaded shadow map(CSM),Zhang将其命名为parallel-split shadow map,两者都在文献中出现过,其实是相同的(参考文献[1964])
如上图中的左侧,观察者的视椎体被分为4个volume。右侧,为每个volume创建bounding box,该bounding box是用于确定针对方向光绘制shadow map的时候,具体绘制哪些物件。
(Patrick:CSM会带来大量DC,原因就是上述的bounding box)
上图中的左侧,场景使用了2048的shadow map,出现了perspective aliasing。右侧,沿着视图轴使用了4个1024的shadow map,明显提升了阴影质量(参考文献[1963])。在红色框中可以看到围栏前角的缩放图。(图片来自于中国香港大学Zhang Fan)。
该算法实现起来很简单,能用于大场景,且效果还可以。dueling frusta问题也可以通过在眼睛周围使用更高采样率这种方式来解决,也不会产生特别坏的效果。因为上述优点,CSM被用在很多应用中。
虽然可以使用perspective warping将更多采样样本打包到单个shadow map的细分区域(参考文献[1783]),但通常还是为每一层使用单独的shadow map。如图7.18所示,图7.20是从观察者角度显示,每个shadow map覆盖的区域都不同。近处的shadow map使用小的视椎体,以提供更多的采样样本。关于将场景中的Z-depth如何划分,这个工作被称为z-partitioning,可能很简单也可能复杂(参考文献[412、991、1791])。一种方法是logarithmic partitioning对数分割(参考文献[1062]),每一层cascade,远平面距离与近平面距离的比例相同:
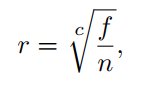
其中,n和f代表着整个场景的近平面和远平面,c是cascade数量,r是生成的比例。比如,如果场景最近的对象距离1米,最大距离为1000米,我们有三级cascade,则r = 10。最近一级cascade的近平面和远平面距离为1和10,下一级是10到100,比例保持不变,最后一级为100到1000米。针对这种划分方式,近平面的距离非常重要,假如近平面的距离为0.1米,则r = 21.54米,比刚才的比例要高。每层的近远平面也就是0.1、2.154、46.42、1000。这意味着第二三级的shadow map覆盖了更大的区域,从而降低了精度。这样的分区为接近近平面的区域提供了相当大的分辨率,如果该区域没有对象,则会浪费这些分辨率。避免这种不匹配的一种方法是将分层距离设置为对数分布和等距分布的加权混合(参考文献[1962、1963])。但如果我们能确定场景的tight view bounds严密视图边界,效果会更好。

可视化的shadow cascade。紫色、绿色、黄色、红色代表从近到远的cascade(图片由Unity提供)
难点在于设置近平面。如果设置的距离眼睛太远,近处的物体可能会被这个平面clip,这样会比较难看。针对cut scene,艺术家可以提前准确设置该值(参考文献[1590]),但是对于交互式场景,这个问题就比较麻烦了。Lauritzen等人(参考文献[991、1403])提出了sample distribution shadow map(SDSM),使用前一帧的z-depth通过下面两种方法中的一种确定更好的分区。
第一种方法是查看z-depth的最小值和最大值,并使用这些值设置近平面和远平面。这是在GPU使用所谓的reduce操作,在该操作中,通过computer shader或者其他shader,使用一系列逐渐变小的buffer进行处理,前一个pass的输出作为后一个pass的输入,直到最终留下1*1的buffer为止。通常,会将这些值向外推一点,以根据场景中对象的移动速度进行调整。如果不采取纠正措施,从屏幕边缘进入的物件会导致当前帧出现效果问题,但是在下一帧中会很快被纠正。
第二种方法也是分析z-depth的值,生成一个直方图,记录z-depth的分布。除了找到近平面和远平面之外,直方图上可能还会有一些缺口,代表这些区域根本没有对象。这样,就可以用cascade只包含存在对象的区域,从而提高每层cascade的z-depth精度
在应用的时候,第一种方法更通用、快速(通常每帧只需要1ms),结果也很好,因此它已经被几个应用所采用(参考文献[1405、1811])。如图7.21。

上图展示了depth bound的效果。上图左侧,对近平面和远平面不进行特殊处理。上图右侧,使用SDSM找到更合适的边界。注意看左边缘附近的窗框、二楼花箱下方的区域以及一楼的窗口,左侧的图片由于没有通过depth bound调整远近平面,导致伪影。可以通过Exponential shadow map来渲染这些特定的图像,但是提升depth精度,对所有shadow map技术都有效(图片来自Ready at Dawn黎明工作室,版权归Sony公司)
与单个shadow map一样,由于灯光采样逐帧移动而产生的闪烁是一个问题,并且当对象在cascade之间移动时,可能更糟糕。使用各种方法来保持世界空间中的稳定采样点,有很多方法,且各有各的优势(参考文献[41、865、1381、1403、1678、1679、1810])。当一个对象跨越两个shadow map的边界时,阴影质量可能会突然发生变化。一个解决方案是使相邻volume略微重叠。在这些重叠区域中采集的样本根据两个相邻shadow map的结果进行混合(参考文献[1791])。或者,可以通过使用抖动(参考文献[1381])在该区域中采集单个样本。
由于其普及型,人们花费了大量的努力来提升其效率和质量(参考文献[1791、1964])。如果shadow map frustum中没有发生任何变化,则不需要重新计算shadow map。对于每个灯光,可以通过查看哪些对象对灯光可见,以及哪些对象投射阴影,来预先计算阴影投射器列表(参考文献[1405])。由于很难感知阴影是否正确,因此还可以采用一些适用于cascade和其他算法的方式。一种技术是使用低lod的来生成阴影(参考文献[652、1812])。另一个是过滤掉一些小的遮挡物(参考文献[1381、1811])。根据阴影不太重要的理论,远处的shadow map更新频率可以低于一帧一次。这个方式可能会导致大型移动物件出现伪影,所以需要小心使用(参考文献[865、1389、1391、1678、1679])。Day(参考文献[329])提出了“scrolling”逐帧滚动 shadow map的方法,因为静态shadow map的大部分都是可以逐帧重用的,只有边缘可能会改变,因此只需要渲染边缘部分即可。像Doom(2016)维护了一个大的shadow atlas,只会更新有物件移动的地方(参考文献[294])。远处的cascade其实可以完全忽略动态物件,因为这些阴影其实对整个画面影响很小。对于一些情况,可以使用一个高分辨率静态shadow map来代替远处的cascade,这可以显著减少工作量(参考文献[415、1590])。A sparse纹理系统(第19.10.1节)针对整个世界生成一个大的静态shadow map(参考文献[241、625、1253]).CSM也可以和baked-light map或者其他更适合特定情况的阴影技术结合起来(参考文献[652])。可以关注Valient的演讲(参考文献[1811]),描述了各种游戏的不同shadow系统和技术。第11.5.1节详细讨论了预计算的光影算法。
创建多个shadow map也就意味着每个shadow map都要绘制一些几何体。相应的,有很多提升效率的方法是用于在一个pass中,将遮挡器渲染到一组shadow map中。geometry shader可用于复制对象数据并将其发送到多个视图(参考文献[41])。Instanced geometry shader可以将一个物件渲染到最多32个depth texture上(参考文献[1456])。使用multiple-viewport扩展可以将一个物件渲染到特定的texture array slice上(参考文献[41、154、530])。第21.3.1节根据它们在VR上的应用,更详细的讨论了这些问题。viewport-sharing的一个缺点是,必须直接操作出现在多个shadow map的遮挡器,而非每个shadow map对应的集合。(参考文献[1791、1810])
你本人目前正处于全世界数十亿光源的阴影中。光线从其中的几个出发到达你。在实时渲染中,如果所有的灯光始终处于活动状态,那么具有多个灯光的大型场景的运算量会超大。如果一个volume在视椎体内,但是眼睛并看不到,和这个volume相关的遮挡物,如果没有将阴影投射到其他物件上,这些遮挡物则无需渲染阴影(参考文献[625、1137])。Bittner等人(参考文献[152])通过视角方向的oc(详见19.7)查看所有可见的阴影接收器,并从灯光角度将阴影接收器渲染到stencil-buffer上。这个mask展示了从灯光视角可以看到哪些阴影接收器。生成shadow map的时候,根据这个mask来提出掉哪些没有阴影接收器的地方。针对灯光也有各种cull策略,比如,由于irradiance辐射度与距离的平方成正比,所以通常的技术是在一定阈值距离后剔除光源。例如,第19.4节中的portal culling可以找到哪些灯光影响哪些cell单元格。这是一个活跃的研究领域,因为对性能的提升是很可观的(参考文献[1330、1604])(Patrick:比如tile/Cluster based lighting)
7.5 Percentage-Closer Filtering
shadow map的一个简易扩展是可以提供pseudo-soft伪软阴影。这种方法有助于改善当单个光采样单元覆盖多个屏幕像素时,导致阴影块状。该解决方案类似于纹理放大(第6.2.1节)。这个方案需要从shadow map采样四个最近的样本,而非一个。取回来后并非将这四个样本进行插值,而是将它们与接收器深度一一做对比。也就是,将接收器的深度与shadow map的四个纹素分辨比较,然后来确定该点是否位于阴影内。得到的结果,0代表在阴影内,1代表在光照下,然后进行双线性插值,以计算灯光对物体位置的实际影响。这种过滤会产生认为的柔和阴影。根据阴影贴图的分辨率、相机位置和其他因素,这些半影会发生变化。比如,分辨率越高,边缘软化程度越窄。尽管如此,一点的半影和平滑还是比没有好。
这种从shadow map中检索多个样本并混合结果的想法被称为percentage-closer filtering百分比接近滤波(PCF)(参考文献[1475])。area light能产生soft shadow。物件表面某个位置的光亮是从该位置可见光面积比例的函数。PCF试图通过重现这个过程来为punctual光(或者方向光)生成软阴影。它不是从物件的位置出发查看灯光的可见区域,而是从物件位置附近的一组曲面位置出发查看punctual light的可见性。如图7.22。PCF的名称就是该算法的最终目标,即找到样本中,可以看到光源的部分所占的比例。这个百分比代表着有多少光照亮表面。
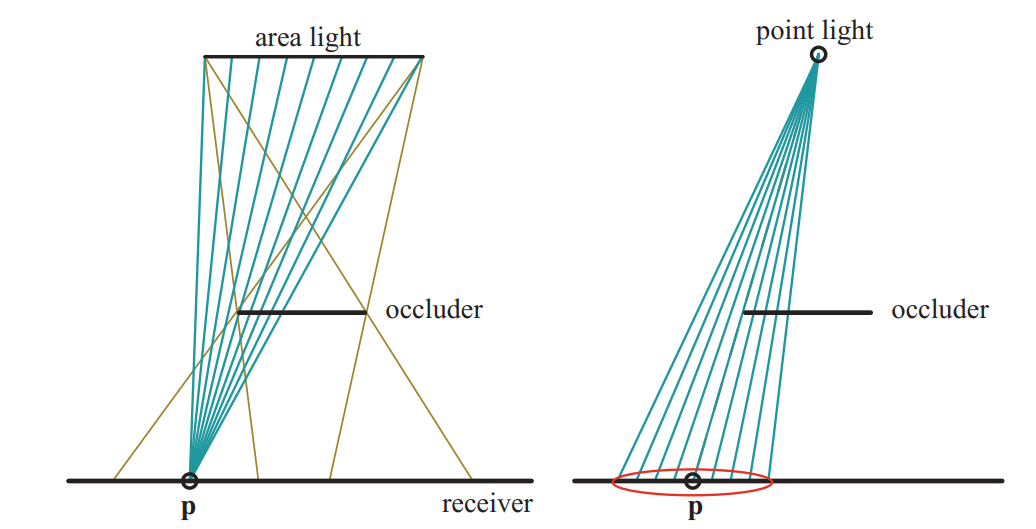
上图中的左侧,来自area light的棕色线显示了半影的形成位置。对于接收器上的单个点p,可以在area light上找到一组点,并找出未被任何遮挡器遮挡的点来计算接收的照明亮。上图右侧,点光源不投射半影。PCF使用反转过程来近似area light的效果:在给定位置,将其和shadow map上的附近若干采样点进行比较,得到百分比。红色椭圆显示shadow map上的采样区域。理想情况下,这个圆盘的宽度最好是与接收器和遮挡器之间的距离成正比。(Patrick:这样,接触点没有软阴影,遮挡器和接收器距离远的软阴影区域比较大)
在PCF中,位置是在曲面位置附近生成的,深度大致相同,但在shadow map上对应不同纹素。检查每个位置的可见性,然后混合这些生成的布尔值(亮或者不亮)以获得软阴影。注意,这个过程是非物理的,因为这个过程并非直接对光源进行采样,而是依赖于表面本身进行采样。由于物件对遮挡器的距离不会影响结果,因此所有的阴影都具有相似大小的半影。尽管如此,该方法在很多情况下提供了合理的近似值。
一旦确定了要采样的区域的宽度,就必须以避免锯齿的方式来采样。在shadow map附近采样和过滤的方法有很多种。针对采样区域的宽度、采样数、采样模式以及如何对结果进行加权,组合成不同的方案。对于性能比较差的API,可以通过类似双线性插值(访问四个相邻位置)的特殊纹理采样模式来加速采样过程。并非混合采样结果,而是将四个样本中的每个值与给定值进行比较,并返回通过测试的比例(参考文献[175])。(Patrick:通过Bilinear Filter让阴影更平滑,跟PCF差不多,比较相邻的4个点,然后根据Texel的Offset做插值。)然而,在规则的采样模式执行临近采样会产生明显的伪影。使用模糊结果但考虑对象边缘的joint bilateral关节双边过滤器可以提高质量,同时避免阴影泄漏到其他曲面上(参考文献[1343])。有关此过滤技术的更多信息,请参见第12.1.1节。

DX10中引入了一个单指令,可以实现PCF所需要的双线性滤波,给出一个更平滑的结果(参考文献[53、412、1709、1790])。(Patrick:现在的GPU都支持Hardware Shadow Map,可以直接通过tex2Dproj( u, v, z, p )这条指令实现2x2PCF+BF。)与最近邻采样相比,这提供了相当大的视觉改进,但来自常规采样的伪影依然是个问题。解决最小化网格pattern的一个方案是使用一个预计算的Poisson distribution pattern来采样一个区域,正如图7.23所示。这种分布将样本分散开来,使它们既不接近也不规则。众所周知,针对每个像素使用相同的采样位置,而不考虑其分布如何,都会产生pattern(参考文献[288])。这样的伪影可以通过随机旋转其中心周围的样本分布来避免,从而将锯齿变成噪声。Castano(参考文献[235])发现,Poisson抽样产生的噪声特别明显,因为它们的内容平滑、程式化。因此提出了一种基于双线性采样的高斯加权采样方案。

上图中的最左侧显示的是4*4 grid pattern下的PCF采样,使用最近邻采样。最右侧为12-tap Poisson采样模式。使用这种采样模式对shadow map采样会生成左侧第二张图这样改进后的结果,尽管瑕疵依然可见。在左侧第三张图中,采样模式围绕其中心,逐像素的随机旋转。结构化的阴影伪影会办成(不那么令人讨厌的)噪声。(图片由ATI Research,Inc的John Isidoro提供)
当使用PCF的时候,自阴影和漏光的问题,比如acne和peter panning会变的更糟。假设shadow map上的采样距离不超过一个纹素,slop scale bias坡度比例偏移仅基于曲面和灯光的角度将曲面推离灯光。由于PCF是在对象表面对应的shadow map附近进行采样,可能导致一些采样点被对象本身所遮挡。
据此,已经发明了一些不同的bias因子,并在一些地方成功的降低了自阴影的冯翔。Burley(参考文献[212])描述了bias cone,将每个采样点按照与原始采样点的距离成比例的向光移动。Burley建议斜率为2,同时有一个小的恒定偏差。如图7.24。
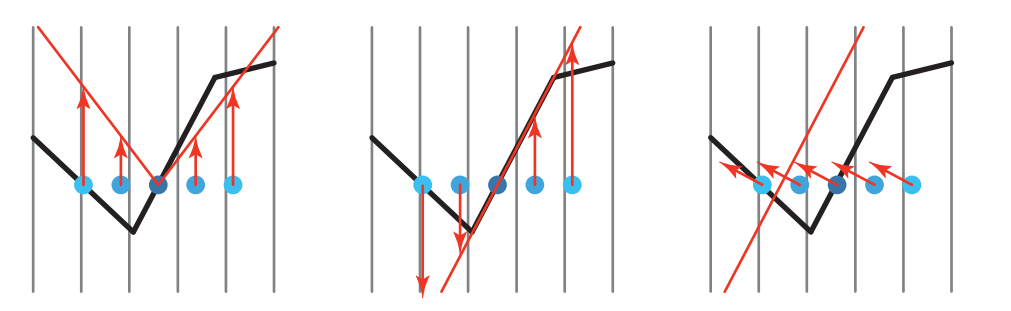
上图为Additional shadow bias方法。对于PCF,围绕原本样本位置(5个点的中心)采样多个样本。所有的这些样本理论上都应该被光照亮。在上图中的左侧,形成一个bias cone,将样本向上移动。可以将cone的角度提高,使得右侧的样本被照亮,但这样的话可能会导致真正被遮挡的样本出现漏光现象(本图中没有这种情况)。在中间,所有样本都被调整到接收器的平面上。这对凸面效果很好,但在凹面会适得其反,图中的左侧就被错误的认为是在阴影中了。在上图中的右侧,将采样点按照法线进行偏移。对于中心样本,可以认为是移动到原始曲面上方的虚拟曲面。这种bias不仅影响深度,还会更改用于测试shadow map的纹理坐标。
Schuler(参考文献[1585])、Isidoro(参考文献[804])和Tuft(参考文献[1790])都提出了基于接收器本身的斜率调整其余样本深度的bias技术。其中,Tuft的公式(参考文献[1790])最容易被应用在CSM中。Dou等人(参考文献[373])进一步完善和扩展了这一概念,解释Z深度如何以非线性方式变化。这些方法假设附近样本位置在三角形形成的同一平面上。这种技术被称为receiver plane depth bias或者其他术语,在很多情况是相当精确的,因为这个假想平面上的位置确实是在表面上,如果模型是凸的,则在其前面。如图7.24,如果是凹面,附近的样本则可能被隐藏起来。将常数、slope scale斜率比例、receiver plane接受平面、view bias视图bias、法线offset组合在一起来解决自阴影问题,尽管如此,有时仍需要对每个环境进行手工调整(参考文献[235、1391、1403])。
PCF还一个问题,由于擦痒区域的宽度保持不变,阴影将以相同的半影宽度均匀的显示软阴影。这在某些情况下是可以接收的,但在接收器和遮挡器的接触点处,似乎不正确。如图7.25。

上图展示了Percentage-closer filtering 和 percentage-closer soft shadows。上图中的左侧,为使用了一些PCF的硬阴影。中间为等宽的软阴影。右侧,在对象与地面接触时,具有适当硬度的可变宽度软阴影。(图片由NV提供)
7.6 Percentage-Closer Soft Shadows
2005年,Fernando(参考文献[212、467、1252])提出了一个有影响力的方案,叫做percentage closer soft shadow(PCSS)。将屏幕上的点与其对应shadow map附近的纹素做对比(Patrick:这一点和PCF一样)。用遮挡器与接收器之间的距离来确定采样区域的宽度:

其中,dr是接收器和光的距离,do是平均遮挡器和光的距离。也就是说,遮挡器与接收器越远,遮挡器与光越近,采样区域越大。可以根据图7.22来思考这个原理。图7.2、7.25、7.26都是例子。
如果没有遮挡物,当前位置完全处于光照之下,则无需进一步处理。类似的,如果位置完全被遮挡,也没必要执行该操作。反之,对该区域进行处理,计算光照的贡献度。为了节省成本,可以使用采样区域的宽度来改变采样的数量。也可以使用一些其它技术,比如,对不太重要的远距离软阴影使用较低的采样。
这种方法的一个缺点是需要对shadow map的一个区域进行采样,以找到遮挡物。使用旋转的Poisson disk pattern可以帮助隐藏采样不足导致的伪影(参考文献[865、1590])。Jimenez(参考文献[832])指出Poisson抽样在运动状态下可能不太稳定,并且发现在抖动和随机之间使用函数形成的spiral pattern可以提供更好的逐帧结果。
Sikachev等人(参考文献[1641])详细讨论了一种使用SM5.0中的功能快速实现PCSS的方法,该方法由AMD提出,通常被称为contact hardening shadows(CHS)。这个新版本还解决了PCSS的另外一个问题:shadow map的分辨率会影响半影的大小。如图7.25。先生成shadow map的mipmap,然后选择选择最接近用户定义的世界空间内核大小的mip级别。对8*8区域进行采样来计算平均遮挡器深度,这个过程只需要16次GatherRed()调用。一旦半影区域被确定,高分辨率的mip层用于阴影的锐化区域,低分辨率的mip层用于软阴影的区域。
CHS已经被大量游戏使用(参考文献[1351、1590、1641、1648、1679]),关于它的研究还在继续。比如,Buades等人(参考文献[206])提出separable soft shadow mapping(SSSM),将PCSS过程进行分割,实现像素与像素之间尽可能的重用。
有一个可以加速算法的概念是hierarchical min/max shadow map分层最小/最大 shadow map。由于shadow map的depth很难被平均,所以在mipmap中保存最小/最大值可能有用。也就是说,形成两个mipmap,一个保存每个区域的最大Z值(优势也被称为HiZ),另外一个保存最小Z值。针对一个位置、深度和采样面积,mipmaps可以被用来快速确定是完全照明还是完全在阴影中。比如一个位置的z-depth大于mipmap对应区域存储的最大z-depth,则该位置一定在阴影中,无需进一步采样。这样的shadow map使得确认光的可见性更加高效(参考文献[357、415、610、680、1064、1811])。
PCF是对接收点附近进行采样,PCSS是计算附近遮挡器的平均深度。这些算法都不直接考虑光源的面积,且会受到shadow map的影响。PCSS背后的一个假设是用遮挡物的平均值来模拟半影的大小。当有两个遮挡器,比如一个路灯和一座远处的山,在一个像素上部分遮挡了同一个表面时,这个假设就被打破了,并可能导致伪影。理想情况下,我们希望确定从单个接收器位置可以看到多少area light。一些研究人员已经利用GPU探索backprojection反向投影。其思想是将每个接收器的位置视为视点,将area light视为视图平面的一部分,并将遮挡器投影到该平面上。Schwarz和Stamminger(参考文献[1593])以及Guennebaud等人(参考文献[617])总结以前的工作,并提出了自己的改进意见。Bavoil等人(参考文献[116])采用不同的方法,使用depth peeling深度剥离来创建多层shadow map。Backprojection可以得到很好的结果,但是每个像素的高成本(到目前为止),意味着它们还没有再交互式应用中被采用。
(Patrick:PCSS其实就是PCF的升级版,可以参照这篇文章PCSS 简介)7.7 Filtered Shadow Maps
Donnelly和Lauritzen提出的variance shadow map方差阴影图(VSM)可以被filter。该算法将深度存储在一张图上,将深度的平方存储在另一张图上。在生成该图的时候可以使用MSAA或者其他抗锯齿算法。这些图可以blur、mipmap、或者放入summed area table(参考文献[988])等。这些图可被filter是一个巨大的优势,因为当从这些图检索数据的时候,可以使用所有的采样和过滤方案。
我们将在这里对VSM进行深入的描述,以了解这个过程是如何工作的。这类算法中的所有方法都可以使用相同类型的测试。有兴趣进一步了解这一领域的读者可以查阅相关参考资料,我们推荐Eisemann等人(参考文献[412])的书,给了这个话题更大的空间。
首先,VSM在接收器的位置上,采样一次depth map,以获得最近的光遮挡器的平均深度。当这个平均深度M1(被称为the first moment),大于阴影接收器t的深度时,接收器被认为完全处于光线中。当平均深度小于接收器深度时,使用下面公式:

其中,Pmax是样本在光照下的最大百分比,σ2是variance方差,t是接收器深度,M1是shadow map中的平均预期深度。方差是根据深度平方shadow map中的采样M2(被称为the second moment)计算出来的:
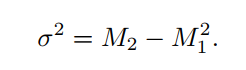
Pmax是接收器可见性百分比的上限。实际照明百分比p不能大于此值。这个上限来自Chebyshev's inequality切比雪夫不等式的one-side variant单侧变量。这个方程试图用概率论来估计在物体表面位置,有多少遮挡物在光源和物体表面之间。Donnelly和Lauritzen表明,针对固定深度的平面遮挡器和平面接收器,p=pmax,因此方程7.7可被用于许多真实阴影的良好近似。
Myers(参考文献[1251])对上述公式进行了说明。在阴影的边缘处,方差变大。深度的差异越大,方差越大。(t - M1)2是能见度百分比的重要决定因素。如果该值略大于0,则意味着遮挡器的平均深度与接收器相比,只是距离光源略微近一点,Pmax也就接近1(完全照亮)。这种情况经常发生在半影的完全照亮的边缘。深入半影区域后,遮挡器的平均深度也就越靠近光源,这一项也就慢慢半大,Pmax也就慢慢下降。同时,在半影区域,方差本身也在发生变化,从沿边缘的几乎为0变为最大方差,其中遮挡器深度不同,面积相同。这些项的平衡给半影一个线性变化的阴影。与其他算法的比较如图7.26。

上图中的左侧,为标准shadow map。上图中的右侧,perspective shadow map(PSM),增加观察者附近shadow map纹理密度。左下角,percentage-closer soft shadow,随着遮挡器与接收器之间的距离增加,阴影变的柔和。右下角,具有恒定软阴影宽度的variance shadow map,每个像素使用单个方差图样本。(图片由Nico Hempe,Yvonne Jung和Johannes Behr提供)
VSM的一个显著特征是它能以优雅的方式处理几何体引起的表面bias问题。Lauritzen(参考文献[988])提出了如何根据表面的斜坡来改变the second mement。数值的一些其他问题可能是方差映射的问题。比如,方程7.8,将两个相似的大数值相减。这种类型的计算往往会放大底层数值表示的准确性不足。不过,可以使用浮点纹理来避免此问题。
总的来说,VSM在有限的时间内提高了质量,因为利用了GPU来处理纹理。而PCF需要多次采样,并且需要更多的时间来避免生成软阴影时候的噪声,而VSM可以只使用一个高质量的样本来生成整个区域的效果,并生成平滑的半影。这种能力意味着在有限的算法中,可以使得阴影可以任意变软,而不需要额外的成本。
与PCF一样,filter kernel的宽度决定了半影的宽度。通过找到接收器和最近遮挡物之间的距离,可以改变filter kernel的宽度,从而给出令人信服的软阴影。Mipmap不适合宽度缓慢增加的半影,因为会产生方形的伪影。Lauritzen(参考文献[988])详细介绍了如何使用summed-area table来提供更好的阴影。图7.27是一个示例。

上图展示了VSM,从左到右,距离光源越来越远。(图片来自NV SDK 10(参考文献[1300]),由NV提供)
当存在两个或者多个遮挡物覆盖一个接收器,且一个遮挡物靠近接收器的时候,VSM沿着半影区域会出现错误。概率论中的Chebyshev inequality切比雪夫不等式将产生一个与正确光照百分比无关的最大光照值。最近的遮挡物只部分的隐藏了光线,从而忽略了方程的近似值。这会导致漏光现象,使得完全闭塞的区域仍然能接收到光线。如图7.28。可以通过在更小的区域采集更多的样本来解决这个问题,将VSM转成PCF的一种形式。这样就与PCF一样,性能就有所降低。对于shadow map复杂度较低的场景,VSM的效果很好。Lauritzen(参考文献[988])提出由艺术家控制的方法来改善这个问题。即将地百分比视为完全阴影,并将百分比范围内的其余部分重新映射到0%-100%。这种方法以缩小半影为代价,将漏光变暗。虽然漏光是一个非常严重的问题,但是VSM依然适用于从地形产生阴影,因为这样的阴影很少涉及到多个遮挡器(参考文献[1227])。

上图的左侧,是将VSM应用到茶壶上。上图的右侧,将一个三角形(未显示)在茶壶上投下阴影,在地面上的阴影中可以看到漏光。(图片由Marco Salvi提供)
(Patrick:VSM的想法很棒,可以说Soft Shadow是从VSM开始才往利用硬件Filter的方向发展。首先,也是Light View的Depth Pass,但是这次写入2个值,一个通道写入Depth,另一个通道写入Depth2。接着对出来的这张 [Depth, Depth2] 的Texture做Blur。直观上来讲,做Blur的结果就是取周围一定范围内的点的平均值(期望值),也就是Blur完之后得到一张 [E(Depth), E(Depth2)] 的Texture。有了这张Texture,后面便可以根据方差公式 V(Depth)=E(Depth2)-E(Depth)2 计算得到方差。 最后,根据Chebychev’s inequality(切比雪夫不等式) P(x≥t) ≤ σ2/(σ2+(t-μ)2) 式中σ2为方差V(Depth),μ为期望E(Depth) 将Pixel坐标变换到Light Space之后的Depth代入t,即得到某个点周围一定范围内大于深度t的点的比率(注意切比雪夫不等式得到的只是一个范围≤,而这里近似的取不等式右侧的结果Pmax)。其实就是一个微分级别的PCF值,于是可以非常高效地得到平滑阴影。 很可惜的是,在Depth变化较大的区域(方差较大),VSM会有缺陷(Light bleeding)。因为根据切比雪夫不等式,在方差较大的情况下,(t-μ)必须足够大,才能让不等式右边趋于0。于是又有了LVSM来解决这个问题。 Layered Variance Shadow Maps 为了解决VSM的Light bleeding,对VSM的Shadow Map进行分层,将每一层次里面的Depth区间控制在一定范围内,也就是降低可能出现的方差值。)能够通过filter快速生成平滑阴影,引起了很多人的兴趣,最主要的挑战是解决各种漏光问题。Annen等人(参考文献[55])提出了convolution shadow map卷积shadow map。扩展了Soler和Sillion的planar receivers平面接收器算法(参考文献[1673])的思想,其思想是将shadow depth编码成傅里叶展开式。与VSM类似,这些图也可以被filter。该方法用于生成正确解,减少漏光问题。
(Patrick:Convolution Shadow Maps CSM提出了一种非常好的图形学算法思路。其推导过程比较华丽,用到了几个数学上的概念:卷积,傅里叶级数。(注意还有另外一种CSM – Cascaded Shadow Maps,两者作用是不一样的) 首先,假设x⊆R3为某一点的世界坐标,d(x)为该点到Light Source的距离(也就是Light Space的Depth)。p⊆R2为该点对应到Shadow Map上的坐标,z(p)为该点对应的Shadow Map上的Depth。于是可以定义一个Shadow Test函数: s(x) = f(d(x), z(p)) 当d>z时,s为0,反之为1 为了得到软阴影,我们希望能对s进行卷积,即希望得到: sf(x) = ∑w(q)f(d(x),z(p-q)) = [w*f(d(x), z)](p)(亮点1) 如果能对上式运用卷积定理,得到如下式的结果,则表明可以通过对z(p)做卷积而得到软阴影。(即可以利用Blur、硬件Bilinear Filter和Mipmap来达到软阴影) [w*f(d(x), z)](p) = f(d(x), [w*z](p)) 可惜的是,f(d(x), z(p))并不是线性函数(而是阶跃函数),无法对其运用卷积定理。为此,CSM转而采用数值分析方法,用傅立叶级数来逼近函数f。(亮点2) 虽然CSM的推导过程相当华丽,但是本身缺点太多(比如:内存开销较大,Shadow Map Pass需要输出的数据量太大,带宽内存都吃得太紧),导致其实用价值很低。)Convolution shadow map的一个缺点是需要计算和访问很多东西,导致计算和存储成本都大大增加(参考文献[56、117])。Salvi(参考文献[1529、1530])和Annen等人(参考文献[56])提出使用一个基于指数函数的项。被称为exponential shadow map(ESM)或者exponential variance shadow map(EVSM),它将深度的exponential指数及其second moment二阶矩保存到两个缓冲区中。指数函数更接近shadow map执行的step函数(在灯光或不在灯光下),因此,这可以显著的减少漏光伪影。它避免了convolution 卷积shadow map的另一个问题,被称为ringing,即在超过原始遮挡器深度的特定深度处可能发生轻微的光泄漏。
存储exponential指数值的一个限制是second moment二阶矩值可能会变的非常大,因此使用浮点数会超过范围。为了提高精度,并允许指数函数更陡的下降,可以使用z-depth,使其为线性(参考文献[117、258])
由于ESM的质量比VSM好,比convolution shadow map需要更少的内存和计算,所以ESM称为三种滤波中最受关注的方法。Pettineo(参考文献[1405])指出了其他一些改进,例如使用MSAA改进结果和处理半透明的能力,以及利用compute shader来提高filter的性能。
最近,Peters和Klein提出了moment矩shadow map(参考文献[1398])。它提供了更好的质量,代价是使用了四个或者更多的moments,增加了存储成本。通过使用16位整数来存储这些moment,以降低内存的开销。Pettineo(参考文献[1404])实现了这种新方法,并将其与ESM进行比较,提供了一个包含很多变体的代码库。
可以将cascaded shadow map用于filter map来提升精度(参考文献[989])。与标准cascade shadow map相比,cascade ESM的优点是可以为所有cascade设置单一的bias(参考文献[1405])。chen和Tatarchuk(参考文献[258])详细的介绍了cascade ESM遇到的各种漏光和其他伪影,并提出了一些解决方案。
filter map可以被认为是廉价的PCF,它只需要很少的样本。像PCF一样,这些阴影具有恒定的宽度。这些filter方案都可以与PCSS结合使用,以提供可变宽度的半影(参考文献[57、1620、1943])。moment shadow map的扩展还提供了光散射和半透明的能力(参考文献[1399])。
(Patrick:知乎上也有个不错的帖子介绍各种shadow map实时渲染中的软阴影技术。还有Klayge对SSM、VSM、ESM的对比介绍切换到esm)7.8 Volumetric Shadow Techniques
半透明物件会减弱并改变光的颜色。对于某些半透明对象,可以使用类似5.5节中讨论的技术来模拟这个效果。比如,在某些情况下,可以生成第二种类型的shadow map。将半透明对象渲染到里面,存储最近的深度和颜色以及alpha coverage覆盖率。如果接收器未被不透明shadow map遮挡,则测试半透明shadow map,如果被遮挡,则根据需要使用颜色和alpha coverage(参考文献[471、1678、1679])。这个想法让人想到了第7.2节中的shadow和光的投影,使用存储的深度来避免将shadow投影到半透明和光源之间的接收器上。这个技术不能用于半透明物件本身。
自阴影对于真实渲染对象(比如头发和云彩)非常重要,而这些对象要么很小,要么是半透明的。single-depth shadow map不适合这些情况。Lokovic和Veach(参考文献[1066])首先提出了deep shadow map,其中每个shadow map存储了光线如何随深度衰减的函数。此函数通常由不同深度的一些列采样近似得到,每个采样都有一个不透明度值。根据图中指定位置深度的两个采样计算出shadow的效果。GPU面临的挑战是如何高效的生成和计算这些函数。这些算法使用类似的方法,遇到了与一些OIT算法类似的挑战,比如,精确表示函数所需的紧凑存储的数据。
(Patrick:关于deep shadow map,我的老同事写过一篇相关的文章屏幕空间深度阴影贴图(Screen Space Deep Shadow Maps))Kim和Neumann(参考文献[894])是第一个提出一种基于GPU的方法,被他们称为opacity shadow map。图中存储了一组固定深度对应的不透明度。Nguyen和Donnelly(参考文献[1274])对这个方法进行了升级,生成了图17.2中的图像。然而,由于深度切片都是平均且均匀的,因此由于线性插值的原因,需要使用大量的切片来避免切片之间不正确的不透明度。Yuksel和Keyser(参考文献[1953])通过创建更接近模型形状的不透明度图来提高质量和效率。这样做可以减少所需层的数量,每一层的评估都对最终图像更重要。

为了避免依赖固定切片,人们提出了一些更具适应性的技术。Salvi等人(参考文献[1531])提出了adaptive volumetric shadow map,每个shadow map纹素都存储了不透明度和layer depth。使用PS对不透明度数据进行有损压缩。这避免了需要无限量的内存来收集所有样本,并处理它们。改技术类似deep shadow map(参考文献[1066]),但压缩步骤在像素着色器中实时完成。将函数限制成一个小的、存储固定数量不透明度/深度对,可以使得GPU上的压缩和检索更高效(参考文献[1531])。这个成本比简单的混合高,因为曲线需要被读取、更新和写回,而且取决于生成曲线的点数。在这种情况下,该技术还需要支持UAV和ROV的硬件(见第3.8节)。示例见图7.29。

上图为使用adaptive volumetric shadow map绘制的头发和烟雾(见第3.8节)。(图片经Marco Salvi和Intel许可转载,版权归Intel所有,2010。)
(Patrick:关于adaptive volumetric shadow map,可以参考Intel官网Adaptive Volumetric Shadow Maps)adaptive volumetric shadow map被游戏GRID2使用进行真实感烟雾渲染,平均成本低于2ms/frame(参考文献[1531])。Furst等人(参考文献[509])描述并提供了它们针对一个游戏实现的deep shadow map。它们使用链接列表来存储深度和alpha,并使用ESM来实现光照和阴影之间的软阴影过度。
关于阴影算法的研究还在继续,各种算法和技术的结合也越来越普遍。比如,Selgrad等人(参考文献[1603])研究使用链表存储多个透明样本,并使用带有分散写入的compute shader来构建这个图。他们的工作使用deep shadow map的概念,以及filter map和其他元素,未提供高质量的软阴影提供一个更通用的解决方案。
7.9 Irregular Z-Buffer Shadows
由于很多原因,现在各种shadow map的方法都很流行。它们的成本是可预测的,而且可以很好的适应场景大小的增加,最坏的情况就是与物件的数量成线性关系。它们可以很好的使用GPU,因为它们依赖光珊化来采样光源空间的世界。然而,由于这种离线采样,问题也就出现了,因为眼睛看到的世界与光源空间的世界没有一一对应。当光源空间中曲面的采样频率低于眼睛的时候,就会出现各种锯齿问题。即使采样率一样,也存在bias的问题,因为光源的采样位置与眼睛看到的位置略有不同。
Shadow volume是一个精准的解决方案,使用灯光和物体表面的交互生成一组三角形,用来定义指定位置是被照亮还是处于阴影之中。该算法的一个严重缺点是在GPU实现时成本不可预测(Patrick:生成的三角形多就成本高,反之就少,不过用于人物自阴影挺好的,问题就是要能拿到人物skin后的顶点位置用于生成三角形)近年来Shadow volume的一些改进(参考文献[1648])非常诱人,但是还没有证据证明可以被用于商业应用。(Patrick:等解决了游戏引擎上面那个问题后,可以看看这个改进)
从长远来看,还有一个非常有潜力的shadow的方案:光线追踪。在第11.2.2节中详细描述,其基本思想非常简单,尤其是对于阴影。光线从接收器位置向光源发出射线。如果发现任何阻拦光线的物件,接收器则处于阴影之中。快速光线追踪器的大部分代码都致力于生成和使用分层数据结构,以尽量减少每个光线所需的测试对象数量。为动态场景构建和更新这些结构是一个历史几十年的老课题,同时也是一个持续不断的研究领域。
还一个方法是通过GPU的光珊化硬件来查看场景,除了Z深度之外,还在光源空间中的每个grid cell中存储了关于遮挡物边缘的额外信息(参考文献[1003、1607])。比如,在每个shadow map纹素中存储了覆盖该grid cell的三角形列表。这样的列表可以通过conservative rasterization生成,其中如果三角形的任何部分与一个像素重叠,不仅仅是像素中心,都将生成一个fragment(详见第23.1.2节)。这种方案的一个问题是,需要限制每个纹素的数据量,而这样反而会导致在确定每个接收器状态时结果不准确。考虑到现代GPU的链表原理(参考文献[1943]),每个像素肯定能存储更多的数据。然而,除了物理内存的限制之外,在每个纹素存储可变数量的数据的另外一个问题是,可能会使得GPU计算变得低效,因为一个warp中可能只有几个thread需要检索和处理许多项,而其它线程则空闲,没有工作要做。在shader中一定要避免使用动态if语句和循环,而导致的线程分歧,这个对性能至关重要。
在shadowmap中存储三角形或者其它数据,并根据接收点位置来进行测试,的另外一种方法是,flip翻转问题,存储接收点的位置,然后根据每个接收点对三角形进行测试。这种保存接收器位置的概念,由Johnson等人(参考文献[839])和Aila和Laine(参考文献[14])首次提出,被称为irregular z-buffer(IZB)。这个名称有点误导性,因为buffer本身作为shadow map有一个正常、规则的形状。而buffer中的内容是不规则的,因为有的纹素中有一个或者多个接收器位置,有的可能根本没有。如图7.30。

上图为Irregular z-buffer。在左上角,根据眼睛的视角在每个像素中心生成一组点。图中显示了形成立方体面的两个三角形。在右上角,这些点被显示在灯光的视图中。在左下角,生成了一张shadow map grid。对于每个纹素,将生成grid cell内所有点的列表。在右下角,通过对红色三角形进行conservatively rasterizing,对其执行阴影测试。将每个接触的纹素,以浅红色显示,列表中所有点都将对照三角形进行光照可见性测试。(underlying raster图像是由Timo Aila和Samuli Laine(参考文献[14])提供)
使用Sintorn等人(参考文献[1645])和Wyman等人(参考文献[1930、1932])提出的方法,使用multi-pass的算法来创建IZB,并测试其内容在灯光下的可见性。首先,从眼睛视角渲染场景,以找到从眼睛可以看到的物体表面的z深度。这些点将被转换到灯光视图中,并根据该几何生成一个具有更严格边界的灯光视锥体。然后,将这些点放置在灯光的IZB中,每个点都将被放入对应的纹素列表中。需要注意的是,有些列表可能是空的,即某些区域灯光可以看到,而肉眼看不到。遮挡器也通过conservatively rasterized进入灯光的IZB中,来判断那些点是被隐藏在阴影中。Conservative rasterization可以确保,即使一个三角形没有覆盖灯光纹理的中心点,依然可以针对它可能覆盖的点来进行测试。
可见性测试是在PS中进行的。测试本身可以可视化为光线追踪的一种形式。从图像中的一个点出发到灯光形成一条光线。如果三角形内部的一个点到灯光的距离,比三角形平面距离灯光的距离要远,那么说明该点处于阴影总。将所有的遮挡器光栅化后,使用可见性测试的结果对曲面进行着色。这个测试也被称为frustum tracing,因为可以认为三角形定义了一个视图视椎体,它被用于检测包含在其中的所有点。
为了使得该方法能很好的在GPU上进行工作,在编码的时候需要特别谨慎。Wyman等人(参考文献[1930、1932])注意到,他们最终的版本,比最初的原版快了两个数量级。这种性能提升的原因,一部分是由于算法的改进,比如剔除法线远离灯光的曲面上的点(因为始终没有照明),并且避免那些对应空纹素的像素点。其他性能提升来自于改进GPU的数据结构,以及对每个纹素使用短的、长度类似的点列表来最小化线程分歧。图7.30展示了一个低分辨率的shadow map,以及用于光照的长列表。理想情况下是每个列表一个图像点。分辨率越高,列表越短,然而同时也增加了用于评估的遮挡物生成的像素数量。
如图7.30的左下角图像所示。由于透视效应,地平面上可见点的密度在左侧比右侧高出许多。使用cascade shadow map有助于降低这些区域的列表大小,方法是将shadow map分辨率聚焦在眼睛附近。
这种方法避免了其他方法的采样和bias问题,并提供了非常清晰的shadow。出于审美和感性的原因,通常需要柔和的阴影,但可能会对附近的遮挡物产生bias问题,比如peter panning。Store和Wyman(参考文献[1711、1712])探索了hybird shadow技术。核心思想是使用遮挡器距离来混合IZB和PCSS shadow,当遮挡器较近的时候使用硬阴影,较远的时候使用软阴影。如图7.31。通常,近处对象的阴影质量更重要,所以可以只对部分物件使用这个技术来降低IZB的消耗。该方案已经成功的应用在电子游戏中。本章7.2的图像就是使用这样的技术。

上图中的左侧,PCF为所有对象提供了柔和的阴影。在中间,PCSS根据距离遮挡物的距离来软化阴影,但是箱子左角与树枝重叠的影子就会出现瑕疵。在右侧,使用IZB的瑞丽阴影与PCSS的柔和阴影相结合,得到一个改进的结果(参考文献[1711])。(图片来自Tom Clancy的《The Division》,由育碧公司提供)
7.10 其它应用
将shadow map视为将光与暗分开的空间,从这个方向出发,也有助于确定哪部分物件在阴影中。(Patrick:拍照的时候也有这个讲究,一个照片,亮部和暗部对比)Gollent(参考文献[555])描述了CD Projeckt的地形阴影系统如何为每个区域计算一个被遮挡的最大高度,然后该高度不仅可以用于地形,还可以用于场景中树木等其他元素的阴影。为了找到这个高度,需要针对太阳渲染可见区域的shadow map。然后检查每个地形高度场位置的太阳可见度。如果在阴影中,则通过将世界高度增加一个固定步长的方式,直到太阳进入视野,然后再进行一次binary search,以此来估计高度多少的时候太阳可见。换言之,我们沿着一条垂直线进行迭代,以缩小它与shadow map表面相交点的距离,该曲面将明暗分开。相邻高度将插值以得到任意位置的遮挡高度。图7.32显示了一个使用地形高度场实现软阴影的技术示例。在第14章中,我们将看到光影领域中光线追踪思想的更多使用方式。
(Patrick:如果用terrain系统的话,这个也挺不错的)
上图展示了,terrain lit根据每个高度场位置计算看到太阳所需要的高度。需要注意沿着阴影边缘的树木是如何被适当的遮挡的(参考文献[555])。(CD PROJEKT和The Witcher是CD PROJEKT Capital Group的注册商标。The Witcher CD PROJEKT SA是由SD PROJEKT SA开发,并拥有所有版权。The Witcher 基于Andrzej Sapkowski的散文改变。其他所有版权和商标均为各自所有者的财产。)
最后一个值得一提的方法是screen space shadow。shadow map因为分辨率的原因,在一些小物件上通常很难做到精确遮挡。在渲染人脸的时候,这一点尤其可能出现问题,因为我们很容易注意到人脸上的任何视觉伪影。比如,渲染一个发光的鼻孔会很奇怪(如果不是故意的话)。虽然使用高分辨率的shadow map或者仅对感兴趣区域单独绘制shadow map可以有所帮助,还有一种方案是使用已存在的数据。在大多数现代渲染引擎中,通过zprepass生成相机透视空间的depth buffer可以被拿来使用。存在其中的数据可以被视为一个高度场。通过这个depth buffer,可以实现一个光线追踪的过程(详见6.8.1节),来检查朝向灯光的方向是否有遮挡物。由于重复采样depth buffer,所以消耗很高,但是可以给cutscene等特写镜头提供高质量的结果,而在这种情况下花费额外的成本通常是合理的。该方法由Sousa等人(参考文献[1678])提出,并在很多游戏引擎中被使用(参考文献[384、1802])。
总而言之,shadow map是迄今为止用于投射到任意曲面形状上阴影的最常用算法。当阴影投射到较大区域(比如室外)时,cascade shadow map可以提高部分区域的质量。如果能通过SDSM得到一个很好的近平面最大距离,则可以进一步提高精度。percentage-closer filtering PCF为阴影提供了一些柔和度,percentage-closer soft shadow PCSS及其变体可以使得接触点的阴影硬化,而irregular z-buffer可以提供精确的硬阴影。filtered shadow map提供了快速的软阴影计算,尤其当遮挡器远离接收器的时候,比如地形。最后,screen-space shadow可以提升精度,尽管成本很高。
在本章中,我们重点介绍了当前应用程序中使用的关键该男和技术。每种类型都有自己的优势,选择哪个,取决于世界大小、组成(静态与动态物件)、材质类型(不透明、半透明、头发或者烟雾)以及灯光的数量和类型(静态或动态,局部或全局、点、聚光灯、area light),以及基础纹理所能隐藏瑕疵的程度等因素。GPU的功能不断发展和改进,因此我们期望在未来几年里继续看到能更好的使用硬件的新算法出现。比如,19.10.1节中,描述的sparse-texture技术已应用于shadow map的存储,以提高分辨率(参考文献[241、625、1253])。Sintorn、Kampe等人(参考文献[850、1647])提出了一种创造性的方法,将2D的shadow map转换成3D的voxel体素集(small boxes,详见13.10)。使用voxel的优势是它可以被分为光照和阴影两种,因此可以节省存储空间。一个高度压缩的sparse voxel octree可以用于表示大量灯和静态遮挡器的阴影。Scandolo等人(参考文献[1546])将他们的压缩技术和基于区间的双shadow map相结合,从而提供更高的压缩率。Kasyan(参考文献[865])使用voxel cone tracing(详见13.10节)从area light生成软阴影。如图7.33。更多cone-traced shadow可见图13.33。

上面一幅图未使用了基本软阴影近似生成方案。下面一幅图,在一个体素化场景中,通过cone tracing生成基于体素的area light shadow。注意,汽车的阴影相当弥散,光照也会因为时间变化而不同。(图片由CryTek提供(参考文献[865]))
更多资源
我们在本章中的重点是介绍基本原理,以及什么质量的shadow才能用于交互式渲染(平衡质量和性能)。我们规避了对这一领域的研究进行详细分类,因为有两本书详细介绍这个领域。Eisemann等人(参考文献[412])的real time shadow专注于可交互式渲染技术,讨论了各种算法的优点和成本。SIGGRAPH 2012的课程中有该书的节选以及对最新工作的一些引用(参考文献[413])。SIGGRAPH 2013的课程演讲稿可以在其网站www.realtimeshadows.com获取到。Woo和Poulin的书 Shadow Algorithms Data Miner(参考文献[1902])提供了用于交互式和批处理渲染的各种阴影算法的概述。这两本书参考了该领域数百篇研究文章。
Tuft的两篇文章(参考文献[1791、1792])对常用的shadow map技术和涉及到的问题都进行了很好的概述。Bjorge(参考文献[154])提出了一系列适用于移动设备的阴影算法,以及比较各种算法的图像。Lilley的报告(参考文献[1046])对实际的阴影算法做了概述,重点放在GIS系统的地形渲染上。Pettineo(参考文献[1403、1404])和Castano(参考文献[235])的博客文章中通过demo代码的形式,展示了他们的使用绩效和解决方案。Scherzer等人(参考文献[1558])针对硬阴影的工作进行了简短的总结。Hasenfratz等人(参考文献[675])对软阴影的综述,虽然年代久远,但在一定程度上涵盖了大量早期的工作。
虽然并非全部原创,但还是希望转载请注明出处:电子设备中的画家|王烁 于 2020 年 6 月 8 日发表,原文链接(http://geekfaner.com/shineengine/Translation7_RealTime_Rendering_4th_Edition1.html)