本系列为Epic官方视频[learn]实时渲染深入探究_Sjoerd De Jong笔记。
深入探索实时渲染
本课程会介绍实时渲染,以及实时渲染相关的性能、功能和工作流。
课程的目录其实就是UE4渲染的顺序,其中很多步骤都是并行发生的,比如3、4、5、6中的Geometry Rendering、Rasterizing and GBuffer、Textures、Pixel Shaders and Materials。
实时渲染的本质,就是用尽量少和可控的性能换取精美的画面。可以参考下面这个图片:
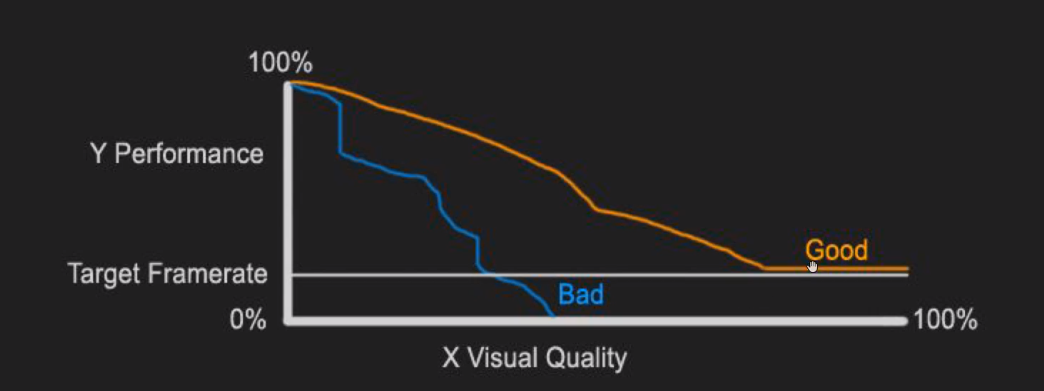 (Patrick:这个图蛮有意思的,做渲染的目标就是走Good路线,比如使用Cluster base lighting的好处,就是普通方案中灯光数量和性能成反比,而Cluster base lighting灯光数量对性能的影响不大,延迟渲染的质量更稳定和可预测)
(Patrick:这个图蛮有意思的,做渲染的目标就是走Good路线,比如使用Cluster base lighting的好处,就是普通方案中灯光数量和性能成反比,而Cluster base lighting灯光数量对性能的影响不大,延迟渲染的质量更稳定和可预测)
在评估性能的时候,需要知道具体哪里会出现性能问题。比如,在硬件中,可能你的操作过于依赖处理器,而内存还有空余,那么就要调整策略,用空间换取时间,这样把消耗平摊到所有硬件。比如,如果发现CPU比GPU的负荷大,那么就可以考虑将部分工作从CPU转到GPU。一般情况下CPU和GPU负责处理渲染的不同部分,多数时候是同步的。
在评估画面的时候,我们必须非常清楚,实时渲染很难重现现实世界。那么,就会加一些限制条件,比如预先约定纹理的尺寸,这样可以从软件架构和硬件上提升处理能力和速度。还可以增加一些预处理环节,与实时渲染相结合。还会将很多技术方案进行混合。
UE4提供如下方案(包括且不限于Direct Shadow(CSM, Dynamic shadowmap, Distance Field shadow, Inset shadow内阴影, Per object shadow(和内阴影类似), Contact shadow) ,Indirect Shadow(Distance Field AO, SSAO, Capsule shadow)):

延迟渲染和前向渲染。UE4默认延迟渲染:擅长渲染动态光照,提供稳定可预测的高质量效果,开关功能更方便。但是针对表面属性就不那么灵活了(毕竟在着色光照的时候,不再拥有渲染几何体时所拥有的所有信息,可供渲染光照的信息变少了)。不能用MSAA(Patrick:只是因为内存和带宽问题的话,可以通过memoryless和load/store action解决,但是针对着色产生的锯齿,就没办法了),而是使用TAA(Patrick:有些游戏使用2xSMAA)
前向渲染:擅长半透明渲染,在应用比较简单的时候,性能也不错。
渲染之前和遮挡
在下图中可以看到一共三个线程,CPU(main thread)、Draw(在CPU上执行的render thread)和GPU。CPU和GPU同步运行,但并不是在同一时间点处理同一帧的内容。CPU和GPU同速前进。首先,CPU(main thread)处理渲染之前的事情,然后Draw(在CPU上执行的render thread)进一步计算更多数据,此时CPU(main thread)开始处理下一帧的数据。当Draw(在CPU上执行的render thread)完成时,GPU开始渲染。如果帧率为30fps,则意味着实际渲染是从66ms开始,也就是中间存在66ms的延迟。
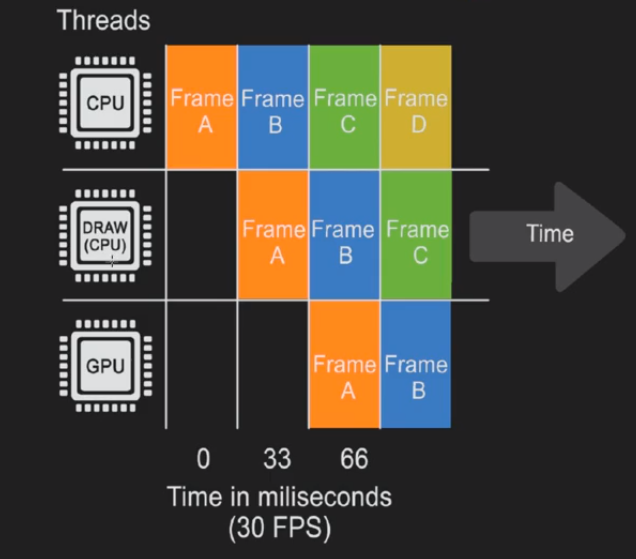
在渲染之前(Frame0 - Time0 - CPU),我们需要知道所有对象的位置。所以我们需要计算所有的逻辑和变换(Animation、Positions of models and objects、Physics、AI、Spawn and destroy, Hide and Unhide),这些是CPU在一开始就必须处理的内容。
(Frame1 - Time33 - Draw Thread(mostly CPU))。知道了所有物件的位置后,下一步需要知道我们究竟能看到什么。这个步骤主要由CPU处理,但GPU也可以(Patrick:GPU Driven pipeline)。也就是Occlusion process遮挡:逐对象,而非逐多边形的,为所有可见对象建立一张列表。
1.Distance Culling(距离剔除,可以逐物件的设置Desired Max Draw Distance,也可以通过Cull Distance Volume统一设置不同size物件的Cull Distance-Current Max Distance,UE4默认关闭,建议将其开启)、2.Frustum Culling(视锥体剔除,逐物件,默认开启)、3.Precomputed Visibility(预计算可见性,默认关闭,通过setting->world setting->precomputed visibility打开,然后增加一个precomputed visibility volume,并将其中分成格子(格子的大小可以在world property中设置,格子高度可以在lightmass的ini配置文件中设置),通过lightmass building,计算出每个格子能看到哪些对象)、4.Occlusion Culling(遮挡剔除,精准检测每个对象的可见性,但会消耗很多性能-可以用Freezerendering做测试,将遮挡冻结)。可以用stat initviews可以看到遮挡计算的耗时和多少个物件被遮挡。当对象超过10000个,就会开始影响性能。当对象数量在30000-60000之间,单单计算遮挡关系,就会产生比较大的性能消耗。
大型开放世界,遮挡可能没太大作用,而计算遮挡的性能依然消耗了。
粒子也能被遮挡,通过boundingbox,可以尽量使得bounding box更新频率降低,来进行优化。
将若干物件合并成大物件,会降低计算遮挡的CPU消耗,但是由于大型物件基本不会被遮挡,所以会增加渲染的GPU消耗。这里需要找到平衡点。
几何结构渲染
UE4针对PC平台,默认有ZPrepass(Patrick:在移动平台的TBDR架构下,ZPrepass可以根据实际情况使用不同方案)。因为PC平台没有HSR,所以必须靠ZPrepass来避免overdraw(渲染顺序也没法完美解决这个问题)。UE4的Zprepass是通过Setting->Project Setting->Rendering的Early Z-pass和Movables in early z-pass设置。
UE4会根据材质,将相同材质的放在一起绘制,避免硬件上昂贵的shader切换(Patrick:感觉这就是srpbatcher?)。
可以用stat RHI来检测渲染状态,可以看到三角形数量和DC数量。即使是空场景,UE4可能会偷偷的做一些事情。PC上DC尽量在2000-3000,mobile上尽量在几百DC。
DC数量比三角形面数更影响性能,因为它会走走停停:等待render thread的命令-渲染-等待-渲染。这个停顿就是影响性能的原因。举个例子:10w面,44000DC的FPS只有4。而8600w面,3300DC的FPS有33。(Patrick:但是针对移动设备TBDR架构中的IA/HSR设计,三角面数也是有上限的,比如ios就是大约400W面)
DC会有一个基础消耗,所以将低面数压缩到更低,可能并不会有什么区别。举2个例子,1.1000面-4000面(在base pass)可能消耗时间差不多(在其他pass,比如shadow之类的,可能还是有区别的(Patrick:why?)),2.2W面大概消耗28ms,30面大概消耗5ms,并非正比关系,因为有基础消耗。
UE4自带HiZ(hierarchical Z-based occlusion)和ComputeLightGrid。BasePass中分为三个步骤:两种static和一种Dynamic。
从这个角度来说,大量小物件不如少量大物件。但是大物件也有自己的缺点:1.不利于遮挡(大物件基本不会被遮挡),2.不利于lightmap(lightmap尺寸有上限,所以大物件的lightmap可能精度比较低),3.不利于碰撞检测(小物件可以用box、sphere等适合做物理检测的基本物件,但是大物件的物理模型一般比较复杂),4.不利于内存(大物件比较容易常驻内存,而且小物件可以复制多份而只占用一份内存)。所以,在这里又需要寻找平衡点。推荐的工作流是:先用模块化的小物件搭建,然后在项目的后期将满足条件的部分小物件合并成大物件(UE4内部提供这个功能,甚至可以导出FBX,不可逆):在同一个空间下,消耗很多DC,合并后面数依然很低,且使用相同材质球,碰撞也比较简单,最好只受到dynamic light影响,或者远处的物件。低端设备对DC敏感,可能需要较多的合并。
UE4默认没有使用instance draw(因为需要检测哪些物件可以使用instance,这个会消耗一定的时间)(Patrick:这。。。划重点。。GPU Driven提上日程)。可以将适合的物件使用instance static mesh组件,这样会告诉UE4一个简短列表(这样UE4依然会检测是否可以使用instance,但是只在列表之内做这个工作。植被是这样的。这样几乎不会有性能消耗。如果数量比较少,比如4个,那么意义不大。最好有几十个以上,才能产生效果(Patrick:mobile上理论上能省一点是一点吧)),按组渲染。
UE4支持LOD,但是确保LOD的差距大于50%,毕竟是用空间(额外内存)换取时间(消耗)。UE4还支持HLOD(hierarchical LOD),将若干物件合并成一个低面数模型,同时降低面数和DC。在window->hierarchical LOD中可以自动创建mesh。室外环境一定要用LOD,大型开放场景还需要用HLOD。
布料、水波浪、风吹草动都是由VS完成(比CPU skin更省性能)。可以尝试根据距离禁用VS动画(动画、特效、偏移)。
光栅化、遮蔽和G-Buffer
下面继续看光栅化过程和G-buffer。光栅化过程就是将3D数据转换成像素的过程,也就是将已知模型渲染成图像。G-buffer就是我们渲染出的不同图像,我们并不只是渲染出一张图像,其实我们是渲染出一组图像,并在之后进行使用。
为了渲染信息,我们会使用很多像素格,像素是方形的,这就意味着整张图像其实是一张大网格。
虽然并非全部原创,但还是希望转载请注明出处:电子设备中的画家|王烁 于 2020 年 11 月 11 日发表,原文链接(http://geekfaner.com/ue4/blog5_course2504896.html)