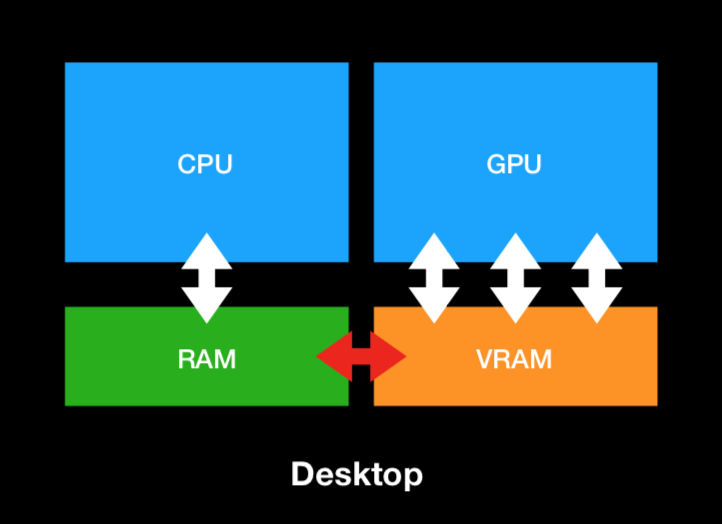
针对桌面PC来说:
- 并不在意功耗带来的影响,因为PC始终是连接电源,且有风扇时刻进行降温处理。
- 在架构上,也没有统一的一块内存共用于GPU和CPU。GPU和CPU各自有自己的一块内存,GPU有一块专用的显存叫做VRAM,访问起来非常快。
- PCIe总线用于连接CPU和GPU,所以导致PCIe总线总是会成为瓶颈。
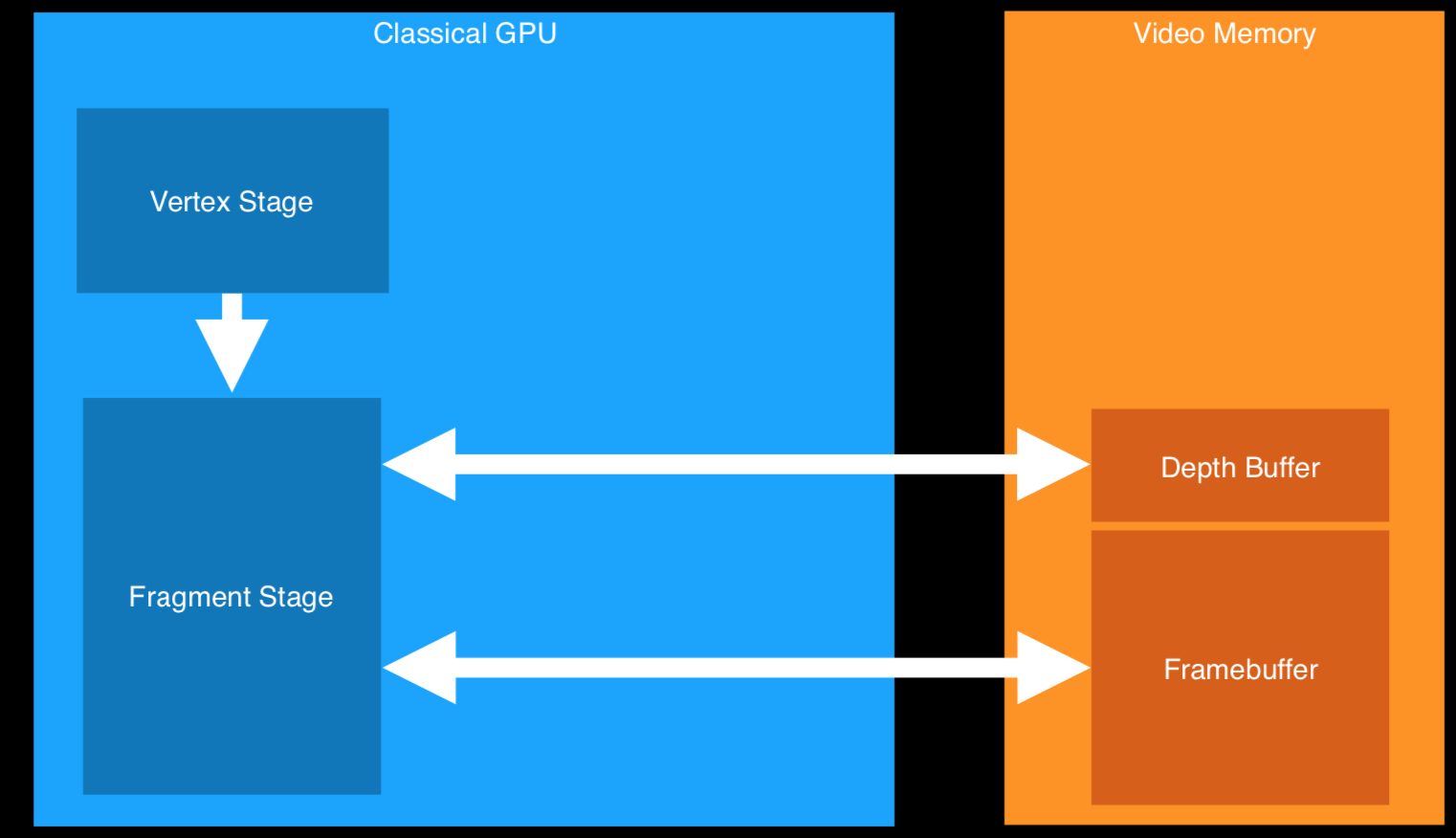
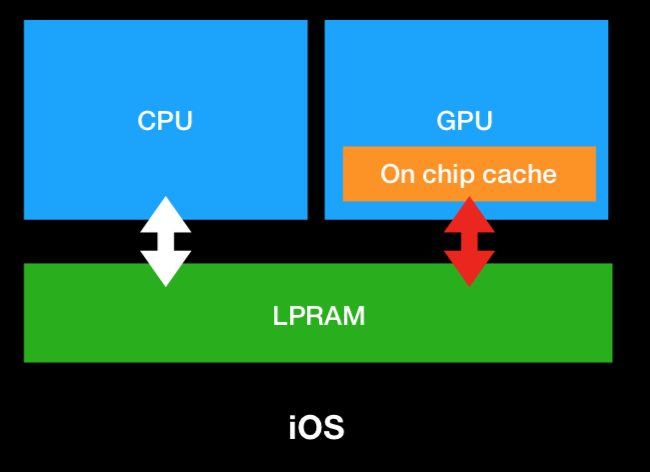
针对移动设备iOS来说:
- 非常在意功耗带来的影响。
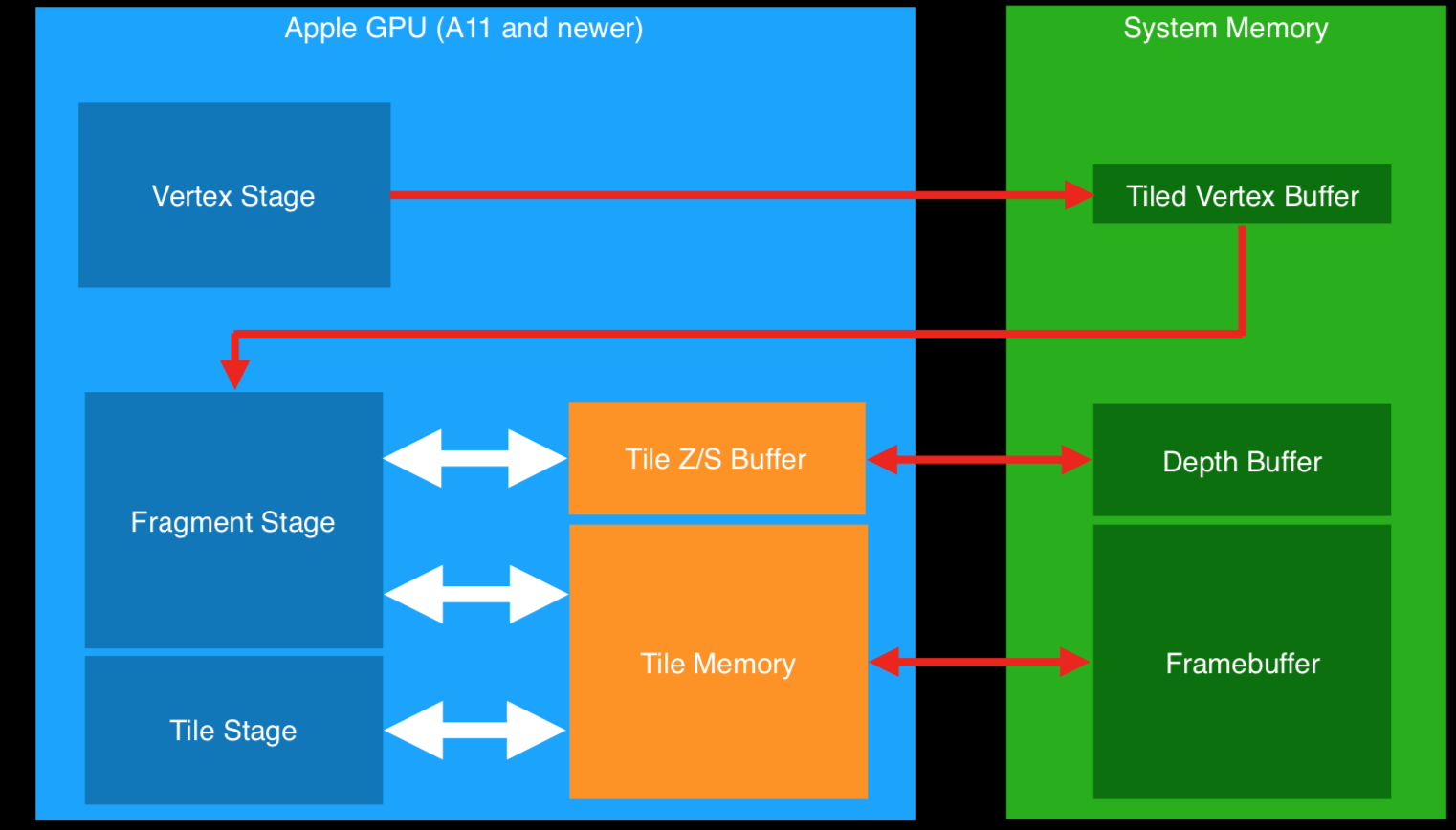
- 在架构上,有统一的一块内存共用于GPU和CPU。GPU和CPU会共享一块内存,另外,GPU还会有一块on-chip的缓存。
- RAM的带宽经常会成为瓶颈。
- iOS GPU的架构为Tile Based Deferred Renderers(TBDR)。
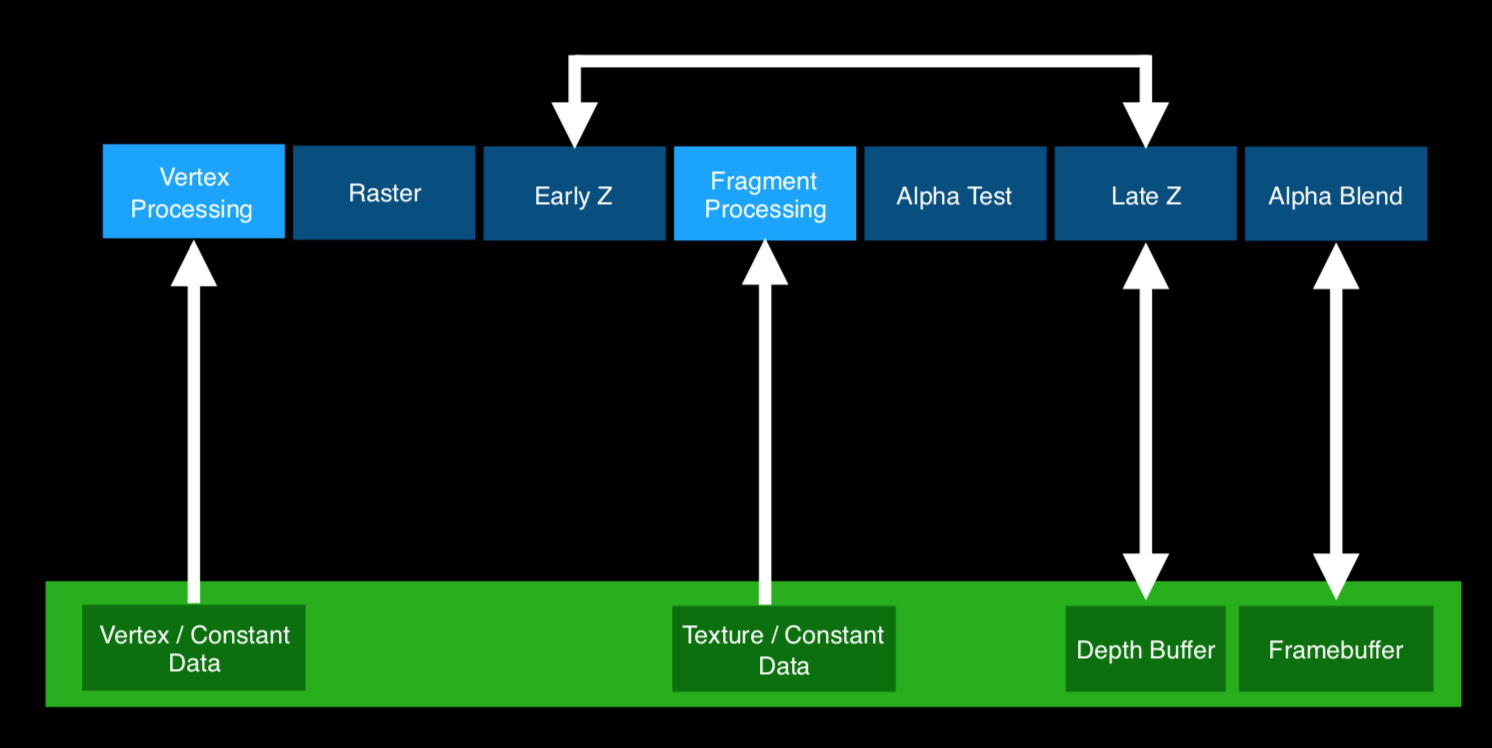
下面解释一下什么是Tiling
- 可以把Tiling看成将viewport分解成小的tiles。
- 将做完MVP矩阵变换之后的图元写入tiles,这一步被称为Tiling。
- 然后对每个tile进行处理:光珊化、着色、存入framebuffer中等操作。

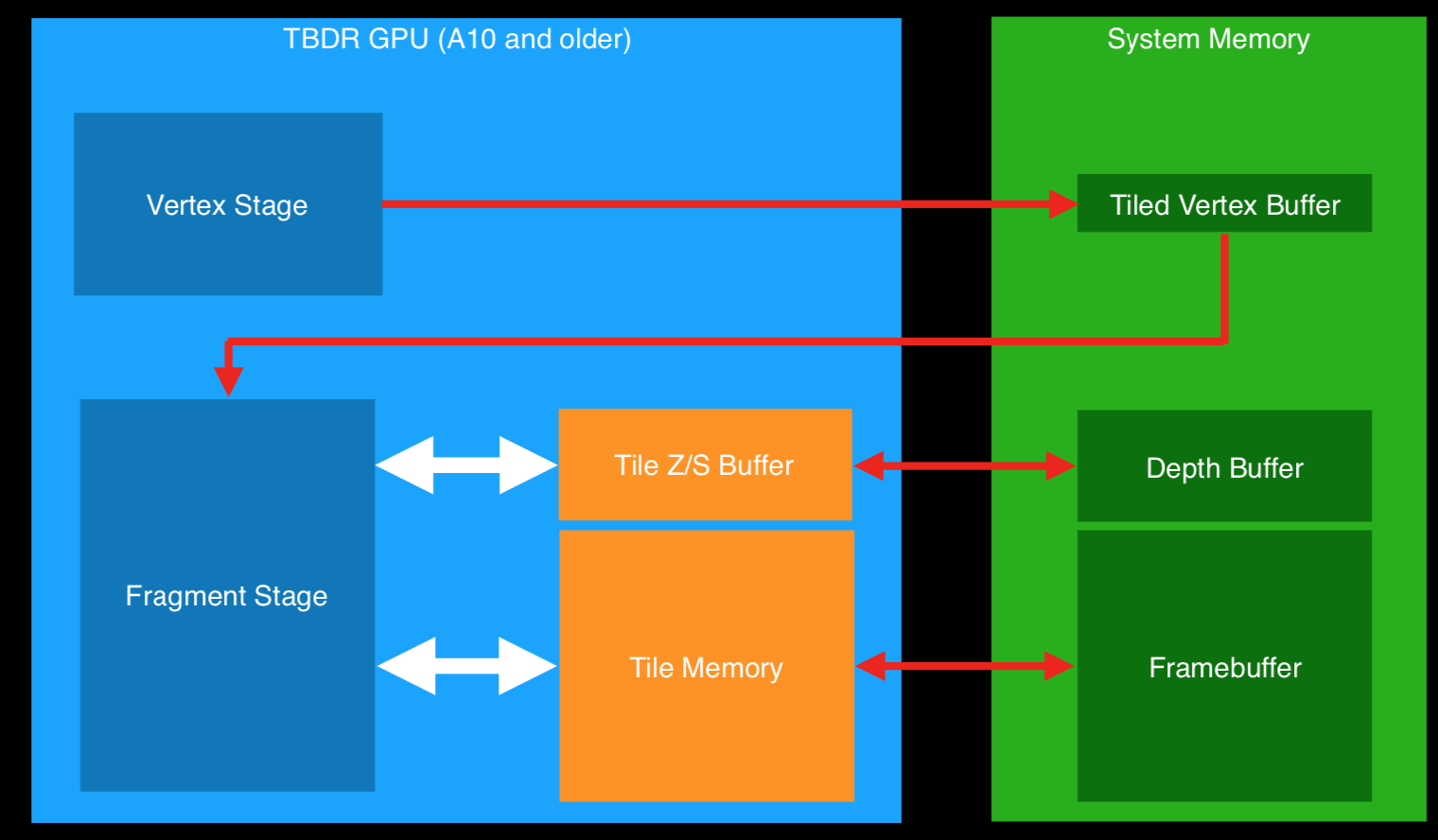
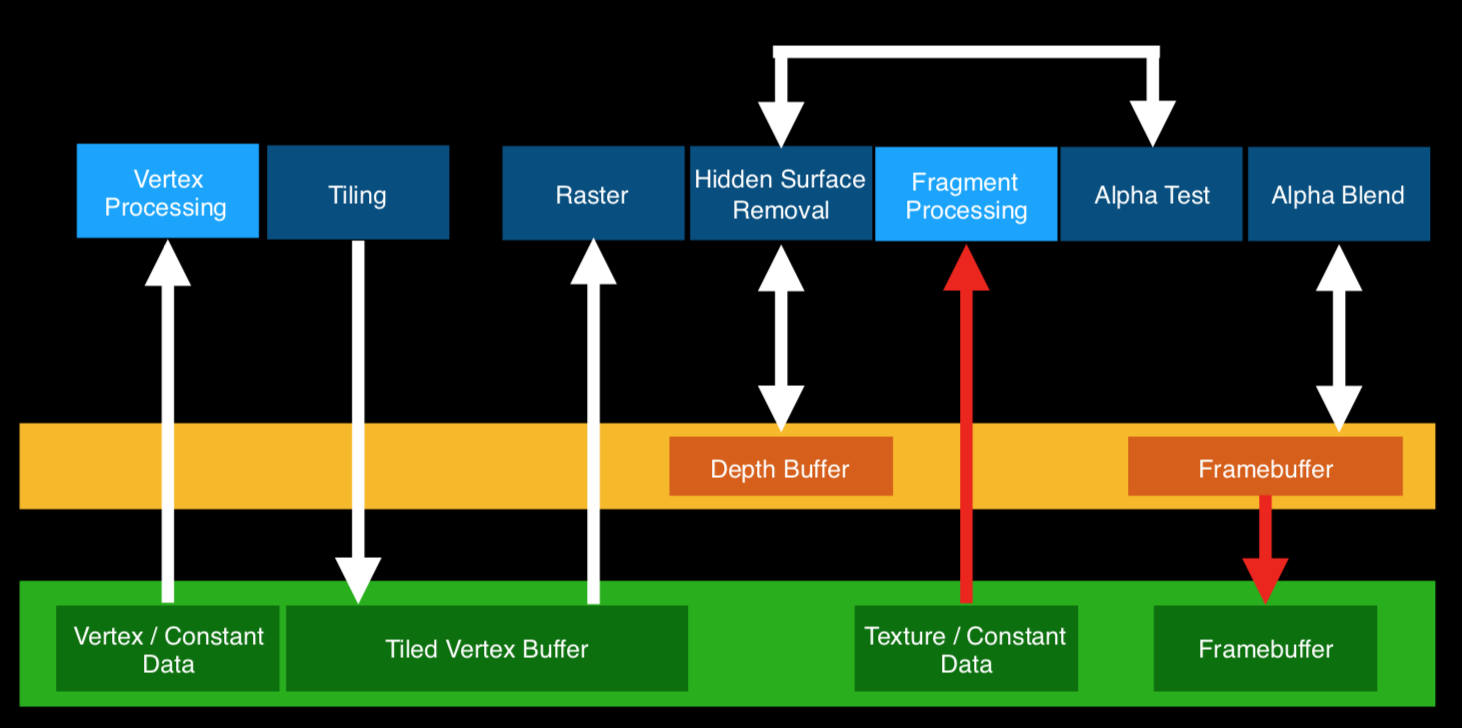
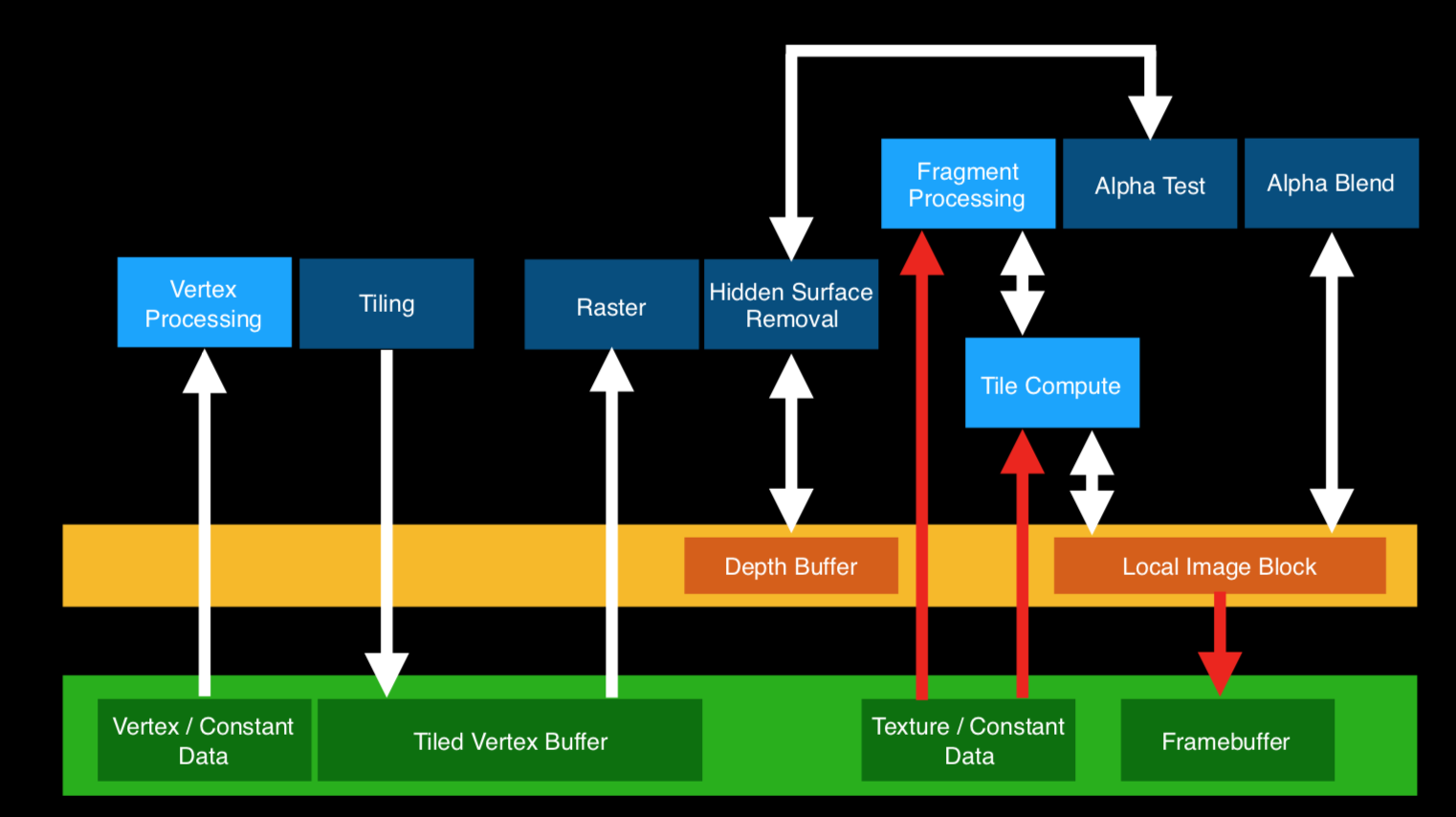
这里来详细介绍一下一个新的技术,Hidden Surface Removal隐藏面消除(HSR)。顾名思义,HSR就是不绘制被遮挡的面,尽可能的降低overdraw。
可以将对Tiles的处理分为两个阶段:首先是先进行HSR,消除被遮挡的面,然后进行PS处理。
使用HSR的好处在于:1.完美的PS处理,不会产生浪费,2.提交渲染的顺序无关紧要了,不需要再按照从前往后的顺序渲染不透明了,而是可以按照状态切换的方式渲染,这样可以大幅度降低DC。

那么随之而来的问题就是,alpha test和alpha blend如何处理?
关于alpha test的问题,通过下面的图可以更容易的说明
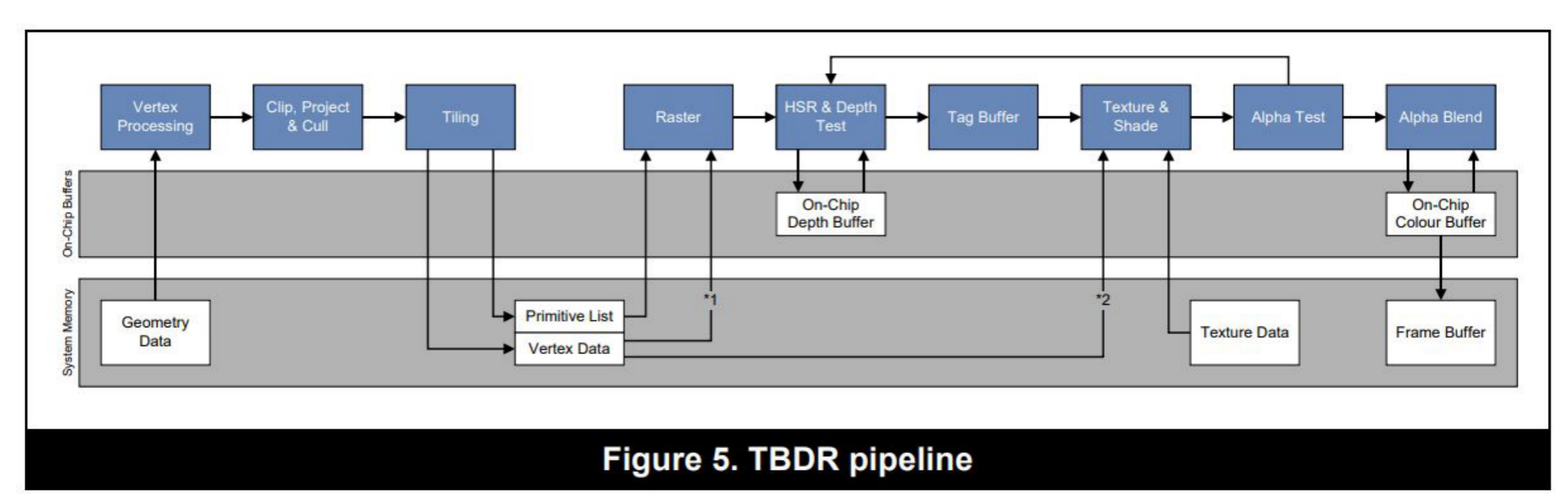
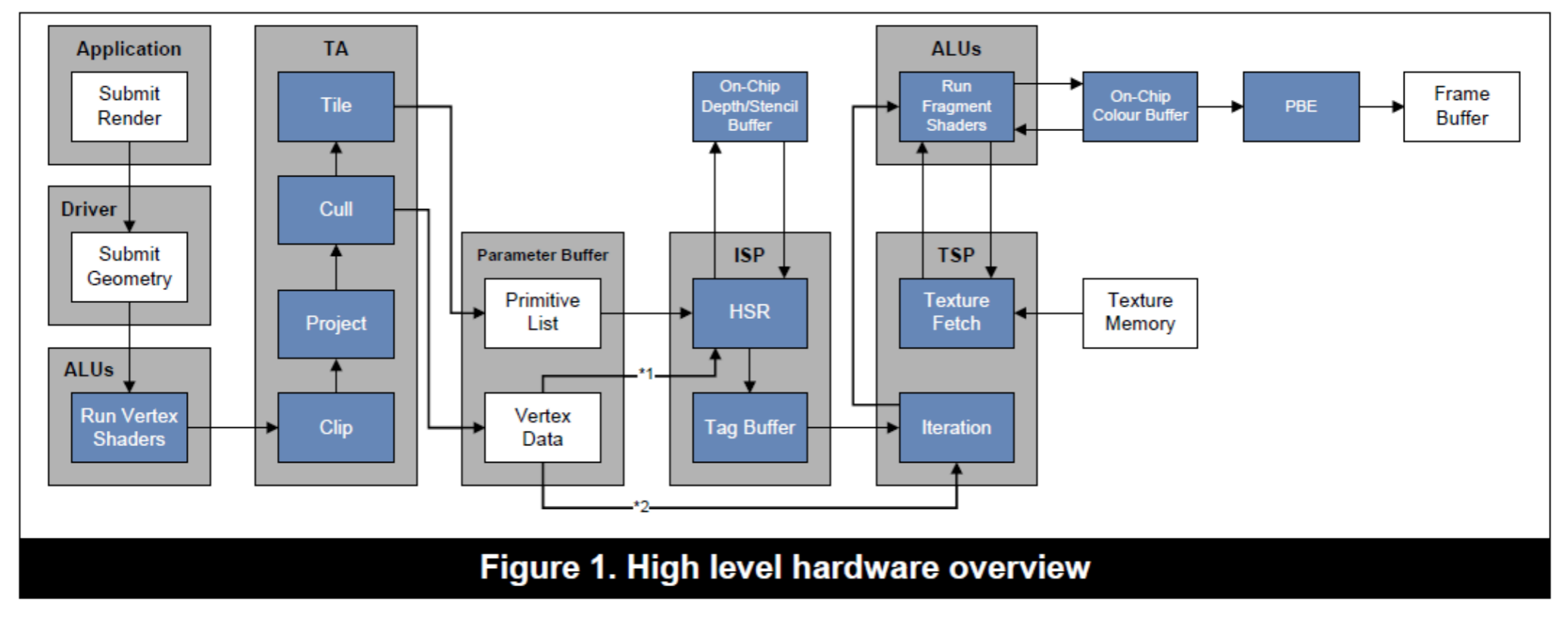
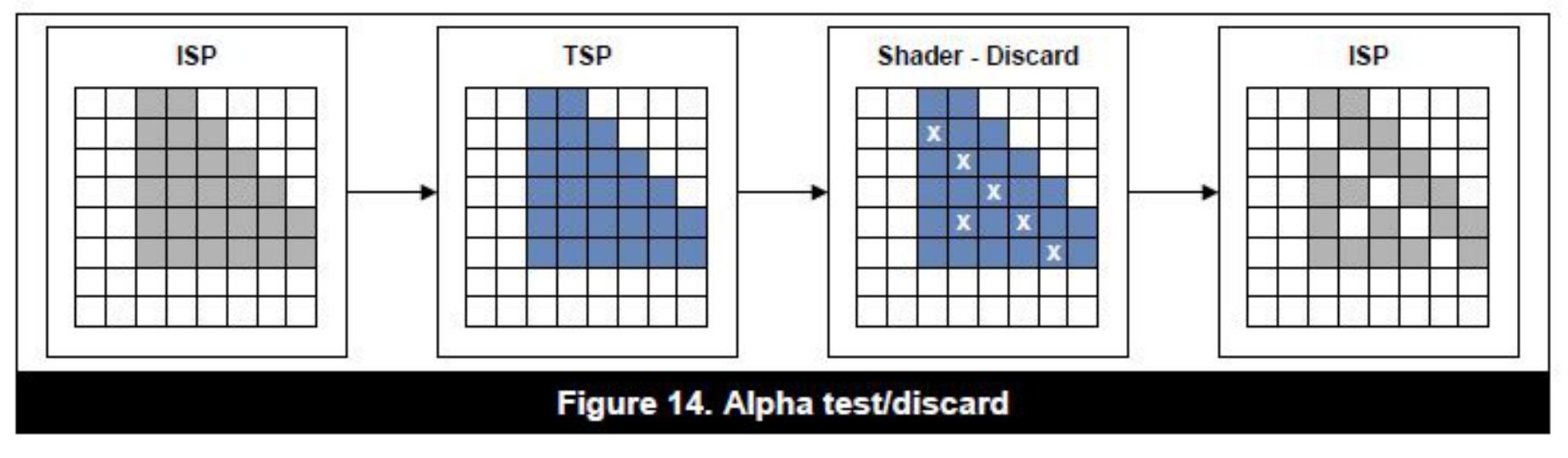
从上图可以看出来,针对alpha test,如果discard的话,会回到ISP阶段重新进行HSR。而Alpha blend则会直接进行一次flush操作。
所以,综上所述,只需要将Opaque、alpha test、alpha blend的顺序明确调整好,先opaque,后alpha test,最后alpha blend。也就是Unity中的2000,2450,3000。其它的,比如同样的opaque,顺序同样是2000,就没必要按照距离从前到后排序了。在SRP中代码如下:
before:var sortFlags = SortFlags.CommonOpaque; after(HSR):var sortFlags = SortFlags.RenderQueue | SortFlags.OptimizeStateChanges;
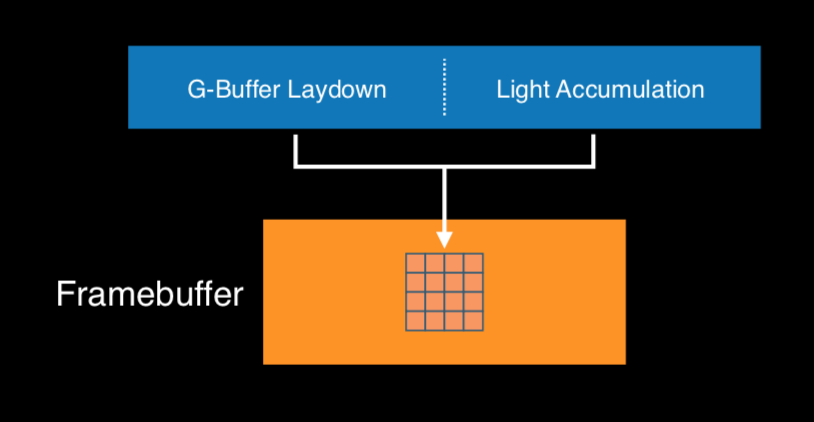
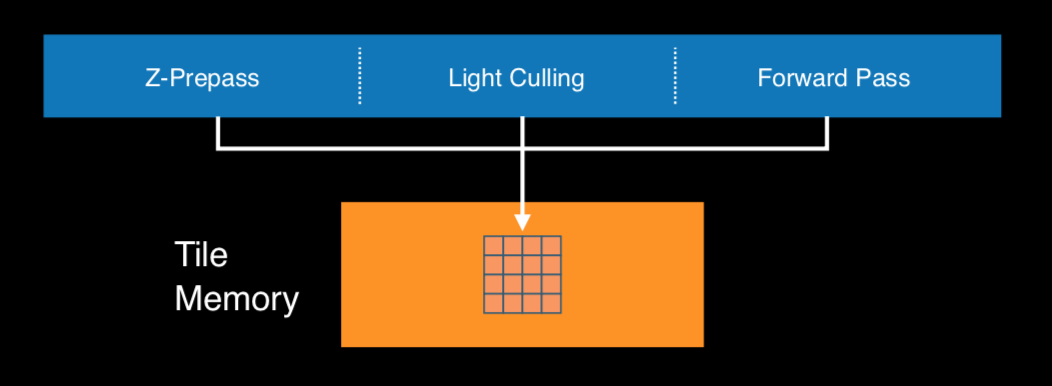
Single-Pass Deferred,这一点,主要参照我的一个同事的两篇文章【Metal引擎剖析(五):Forward+ with Tile Shading】和【Metal引擎剖析(二):传统延迟渲染和TBDR】。大致思路就是利用Memoryless的工作原理,使用tile local storage保存信息。比如forward+中,先进行depthonly pass,将深度信息保存在tile memory上,然后使用tile shader用其算出light index,保存在threadgroup memory上,然后再使用light index进行着色计算。
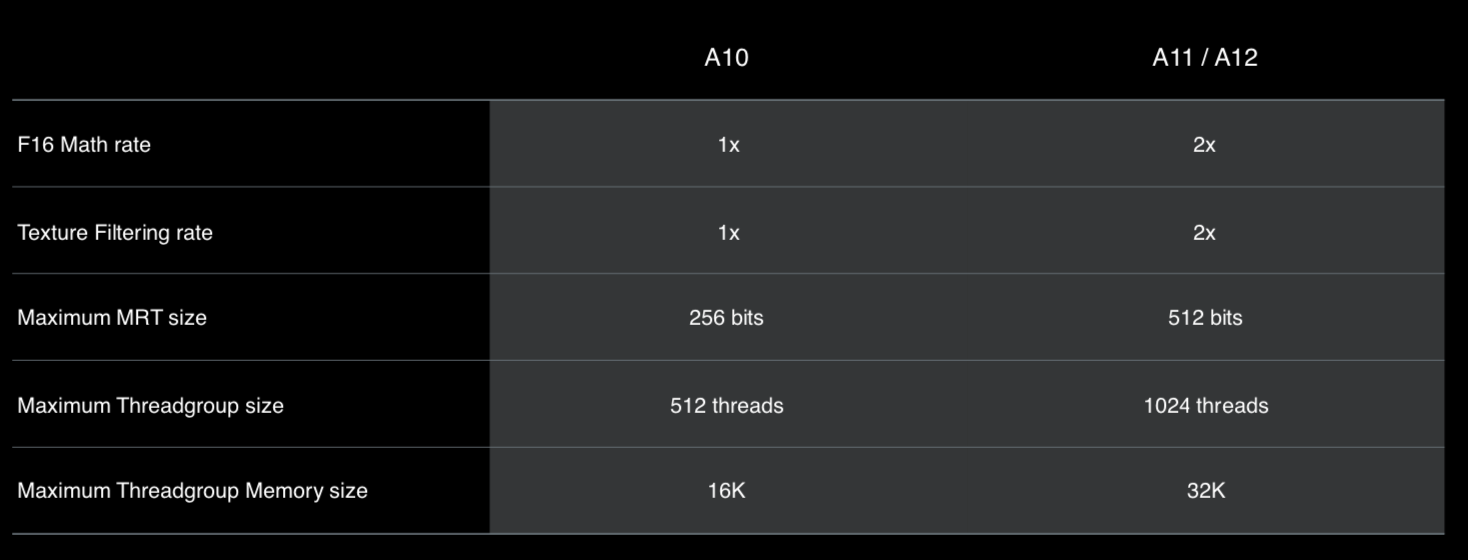
下图为A10和A11/A12的性能对比
虽然并非全部原创,但还是希望转载请注明出处:电子设备中的画家|王烁 于 2020 年 2 月 13 日发表,原文链接(http://geekfaner.com/unity/blog17_GPUofiOS.html)