用一篇文章说完优化
优化很复杂,有专门的公司做优化。UWA(这不是广告,因为没给我广告费~但是这是我师兄的公司,一个我很佩服的人,国内手游优化行业的泰山北斗)。
那么我又说要一篇文章说完优化,胡说的么,哈哈,其实我只是准备写一篇很长的文章,这篇文章甚至不会完结,所以如果有兴趣转载,请注明出处:电子设备中的画家|王烁 于 2017 年 10 月 19 日发表,原文链接(http://geekfaner.com/unity/blog6_Optimization.html)。不然转载了一篇没结束的文章,总是不太好的,同样情况适用于我网站中的任何一篇文章。
优化的重要性
2012年手游开始爆发后,是个游戏都能赚钱,还能赚不少钱,经过几年的混战,手游的成功率越来越低,慢慢的手游越来越精品化。2016年广电总局给手游加了限制,有了版号的概念,又拖垮了一批小型公司和独立开发者,其实这是好事,手游市场越来越规范。
精品的手游意味着更绚的画质、更丰富的内容,也就是对手机的CPU、GPU内存、内存更大的挑战,如何使用有限的手机资源,展现出来更好的游戏,优化必不可少。
手游优化需要各方面的素质,对手机底层(OS、driver及以下)的理解,对图形学(OpenGL ES API及上层算法)的熟练,对游戏架构的把握和对游戏引擎的掌控。所以看上去很简单的工作,其实并不简单。
目前手游客户端开发大体分为三个方向:架构(对游戏各个模块都很熟悉),渲染(对图形学算法很熟悉,和ta类似,但是也有区别),优化(对底层架构和渲染图形学原理都很熟悉)。很多公司针对这三个方向都有技术专家岗的位置。而其中最容易招到的就是架构,因为主程就是架构,其次是渲染,实在没有ta也可以兼着,优化的要求,比较高。
因为运气原因,我硕士研究方向是嵌入式,研究底层,毕业后做了将近3年的手机GPU驱动和1年的linux GPU驱动,之后进入游戏公司。所以算是从底层到上层做了一遍。目前在完美世界引擎组,主要负责轮回决的优化。轮回决现在已经内测,这篇文章也就记录我完整的跟完这个项目,并对该项目进行优化的全过程和总结。
优化的目标
首先,优化需要制定一套目标,也就是最起码优化后项目最起码会达到什么程度。
- FPS:30。电影一般为24帧,帧率越高,感觉越好,手游为了防止发热和用电过快,基本都会限帧到30FPS(比如王者荣耀),所以这里我们优化的目标也就是30FPS。也就是CPU和GPU每帧耗时都要在33.33ms内。当然游戏中难免有个别帧耗时较多,但是为了防止让玩家玩起来有卡顿感,最差的情况不能低于20FPS。
- 内存。这里就把UWA测评的内存标准拿出来了。Reserved Total:150MB。其中:纹理资源:50 MB;网格资源:20 MB;动画片段:15 MB;音频片段:15 MB;Mono堆内存:40 MB;其他:10 MB。
- 场景加载速度:5s。
项目立项前的准备工作
优化不是在项目做完快上线的时候进行的,就好比给你一辆普桑,让你优化成保时捷,不是说不行,那样就要大改了,相当于重新做一遍。所以优化是从项目开始之前就要着手的。大概要考虑一下几点:
- 制定美术规格。比如场景的面数和纹理数量、人物角色的面数和骨骼数、动作文件的大小、特效的复杂度之类。
- Shader的管理
- 不允许美术使用内置的shader,把内置shader下载下来,然后把常用的shader整理后放到工程里(关于如何整理,参照文章SHADERVARIANTS),美术只能从这里选常用shader。如果发现想用的shader没有,要跟负责人提,由负责人来导入,这样方便控制和优化内置shader
- 不允许美术自己从外面找shader,美术想做一些新效果,需要和负责人提需求,新效果需要的shader也由负责人负责
- 统一项目中所有shader的lod管理,这样对于低配机,方便降lod保证性能
- 最好有个小工程,方便展示美术效果用,很多效果需要真机看,维护个小工程,方便打包,能提高工作效率。这个小工程要有UI,方便实时调一些参数,同时也要能快速地加入新效果演示。对于美术提的任何高端效果,我们要有回退方案(有low效果最好,最不济也得能关闭),简单说得有开关 。
- 最耗的Shader是后处理。针对后处理的要求有:a.能方便加入新后处理效果;b.能方便开关每个后处理效果;c.严格控制RenderTexure的使用,尽可能用最少的RT和最少的pass实现效果,有些后处理效果能合在一个pass里完成,那就合在一起
- 搭建工作流程,制作工具用于日常监控性能和美术资源规格等
人物模型多少面,贴图用多大的。这些都要在项目开始之前确定好,否则美术的实力绝对超过你的想象。
这个工作也比较简单,因为做出来的产品是有目标机型的,比如今年的产品最低支持到iphone5,那么明年的产品最低支持到iphone5s,针对最低目标机型CPU、GPU、内存的提升,提升对应的美术规格即可。
demo期间,美术会做几个场景,这个时候只要稍微注意一下即可,demo为了讨老板欢心,可以适当提高规格。但是新项目正式开始,肯定要考虑以后上线的情况,所以需要有一个规格方案提给美术,正式项目得按规格做。
Unity提供了built-in的shader,但是那些是提供给小团队,不懂shader的人用的。针对Shader管理需要注意如下几条:
整理一套流程和工具出来,算是项目组的积累,对之后项目都有利。
优化的原理
优化,其实就是找到瓶颈和耗时点,然后把耗时点消灭掉。
游戏运行和手机中的三大模块相关,CPU、带宽、GPU。
每一帧肯定有一个模块是瓶颈,但是是哪个模块呢?初步判断的办法就是查看游戏的FPS,计算出当前帧耗时的时间,然后通过工具查看CPU和GPU各耗时多久,就可以得知bound在CPU还是GPU了。
还有一个办法就是通过Unity Profiler查看CPU中是否有执行Gfx.WaitForPresent && Graphics.PresentAndSync函数,如果有,那么说明CPU在等GPU,那么瓶颈就在GPU或者带宽上了。
找到瓶颈,再通过工具,找到耗时点,消灭掉,这就是优化。
优化法则第一条:
如果不能定位,那么就没办法优化。
优化法则第二条:
木桶法则,当bound在CPU的时候,只影响GPU/带宽的特性就可以随意使用了。反之亦然。
优化是一个永无止境的工作,而任何工作都是要讲究性价比的。尤其是我们处于游戏这个快速迭代的行业,且项目需要尽快上线的时代。
优化法则第三条:
当FPS无法接受的时候,为了解决瓶颈的问题,即使画质和工时需要再大牺牲,也要去优化。当FPS可以接受的时候,画质、工时、优化效果这三者就要进行平衡了。
优化的工具
Unity Profiler
通过Unity Profiler可以看到Editor(非运行模式),Editor(Game运行模式)、真机(iOS、Android)的性能信息。
- CPU Usage
- GPU Usage
- Rendering
- Memory
- Audio
- Physics
- Network
可以看到CPU函数call trace,通过timeline查看CPU耗时状况,以及某个函数在timeline中的CPU耗时状况,然后可以轻松的找到CPU耗时峰值,查看哪些函数是CPU耗时大户。
目前移动端只支持NV的Tegra GPU的监测,所以很少使用。
通过Rendering可以清晰的看到Draw Call数量,Dynamic batch和static batch的优化率等信息。所以设置了Dynamic batch和static batch可以使用该工具确认一下优化是否生效。
在Game视图中有个status按钮,点击该按钮,也会显示当前帧的Draw Call、三角形数量、顶点数量等信息。
监测内存工具,分simple和detail两种。
Simple模式用处不大,最大的用处是用于查看内存使用是否超标,尽量控制在150MB以内。另外一个用处就是看下Unity、Mono、GfxDriver、FMOD分别用多少。消灭大户。
Detail模式不是实时观看,不过也足以,可以清晰的看到具体的资源,比如AB、texture、Font等各占多少内存。消灭大户。
Unity Frame Debugger
截取当前帧的Render Pass。
当使用了特殊pass的时候,可以用于确认渲染流程。
比如当前帧用了后处理,后处理中还使用到了depth、normal贴图,那么通过该工具会看到Camera会先绘制depth normal贴图。
这个工具只是用于简单的查看使用,真正优化性能的时候很少使用。
XCode GPU capture frame
Unity提供的工具用于查看CPU端耗时还比较方便,但是GPU和内存方面的功能就差强人意。所以在iOS端,我选择XCode提供的这个个工具。
GPU Capture frame用于截取当前帧的GPU call trace。其中XCode8以上版本可以截取metal API call trace,XCode7及以下版本可以截取OpenGL ES 2.0 call trace(需要再Unity打包的时候设置以OpenGL ES API优先)。
通过这个工具可以看到通过GPU做了哪些工作,以及耗费了多少时间。(可以看到某个特效耗费了多少时间,绘制天空盒耗费了多少时间等)。这个工具,帮助我在GPU bound的时候,找到了很多耗费大量时间的事件(比如粒子绘制等)
XCode Instruments
XCode提供了另外一个工具Instrument,可以用于检测iOS内存泄露,不过我检测的时候看到项目内存泄露问题不严重,所以重点就关注在用这个工具查看内存使用状况了。
通过XCode本身可以看到PSS,不过PSS只是个数字,没有任何优化提示,所以没有instrument看到的数据有用。
Instrument可以看到当前帧每个函数的内存消耗情况(但是看不到纹理等占用的内存),对游戏逻辑比较熟悉的同学,就可以根据这些信息,判断某些函数在当前帧是否应该使用那么多内存。
同时,还可以对比不同场景的数据,判断是否是存在应该释放的内存,没有释放的情况。
Mali develop tools
Android上的工具没有XCode那么好用,不同厂家的GPU就要使用不同厂家的GPU debug工具,我现在用的是Mali develop tools,通过这个工具可以获取当前帧的GPU trace,也就是OpenGL ES API,参数信息也可以截取下来,使用起来很方便,缺点是无法看到耗时情况。
不过可以看到shader的使用情况,因为GPU中基本上都是计算,所以通过shader中计算的顶点、像素数量,可以看到哪个shader计算的点数过多,找到耗时大户。
其他的还可以看到纹理(包括格式等)等信息。
优化的步骤
- 真机测试,看FPS。根据FPS计算出来每帧运行的时间。比如FPS 30,则说明该帧耗时33.33ms。
- 通过profiler查看CPU运行时间,如果CPU耗时低于33.33ms,说明是GPU bound,反之说明是CPU bound。
- 如果CPU bound,则需要通过profiler查看耗时大户。
- 如果是GPU bound,分为Android机和iOS机。iOS机器因为有XCode GPU capture frame的关系,轻松定位耗时大户。但是,如果问题只在Android机上出现,那么就尴尬了。猜不到原因的话就只能通过手机驱动厂商提供的工具了,比如Mali develop tools。毕竟GPU bound大部分都是因为计算量过大引起的,计算量也就是顶点数过多,shader过于复杂。
- 如果既不是CPU bound,也不是GPU bound,那就有意思了,我遇到过一次,bound在带宽上了。把纹理的mipmap打开后,FPS就有所下降了。
- 定位到耗时大户,就可以进行针对性的优化了。
针对各个模块进行优化
游戏可以分成很多模块,每个模块都有可能出问题,问题有可能出现在CPU上,也有可能出现在GPU上。通过上面优化的步骤,我们定位到哪个模块出问题了,然后就可以针对该模块进行优化。下面,大致的写一下我在项目优化中遇到过的问题。
- Particle system:时刻警惕半透明
- Postprocess:避免后处理
- Texture:使用适当尺寸的压缩纹理
- Material
- Mesh
- Draw Call:尽量合并DC
- Animation
- Occlusion Cull:合理使用OC
- Scene
- Shodow
现象:作为一个由特效堆成的游戏,粒子系统遇到过如下问题:一个特效叠了20多层粒子系统。特效叠了5层以上,且其中一层粒子生命周期很长,导致大量粒子只出生不消亡。一个特效粒子很大,虽然只有一个粒子系统,但是每个粒子都很大。
分析:粒子的使用,贯穿了CPU、带宽、GPU。CPU方面需要计算粒子状态(Particlesystem.update),需要判断合并Draw Call,需要对绘制进行准备工作。带宽方面需要将粒子使用的纹理,从CPU传入GPU。GPU方面由于粒子系统就是一堆半透明,半透明就代表着overdraw。想象一张画布,在上面绘制一遍和绘制两遍,消耗的时间肯定是会变多的,大量使用粒子,影响最大的还是GPU方面。原因就是粒子绘制,必定造成overdraw。Overdraw就是GPU bound的最不可饶恕的元凶。
解决方案:1.将所有的粒子系统单独设置一个layer,通过Camera.layerCullDistances针对该layer设置Cull Distance,也就是将距离比较远的粒子系统Cull掉,当玩家靠近的时候这些粒子才自动开启。2.通过合并atlas合并material的方式合并DC(Unity 5.3.5已经支持该功能,之前只有子发射器才能合并)。3.粒子lod:中低端手机只使用最基本的粒子,高端机开启全部粒子。判断手机级别的方式有很多,Unity提供了参数Tier1、Tier2、Tier3区分三种级别的手机,其中Tier3最高,Tier1最低。(比如ipad mini3为Tier2)。4.调整粒子发射器的属性(大小和生命周期):单个粒子的大小不宜太大,占据屏幕太大尺寸会导致overdraw的比例变大;不宜叠加太多层,效果也不明显,overdraw问题也比较严重;同屏粒子数量不宜太多,尽量消亡速度大于等于生成速度。5.5.粒子系统不能放在多个相机,否则会在第二个相机绘制的时候,出现主线程等待子线程的情况。
内存方面:虽然还没介绍优化内存的步骤,但是可以想象到,资源的大小直接影响到内存的使用。如果内存很大,特别是Profiler的detail memory中看到other.objects很大,建议将粒子替换成Mesh,一个Mesh的object为1kb,一个粒子的object为26.7kb。(这样做的缺点就是,particle system参数比较多,有利于美术调整,mesh就比较麻烦)
分析:后处理在不同GPU处理器中的具体实现不同,大概原理就是把绘制完毕的buffer拿出来处理一遍,然后再显示出来。总的来说是比较耗时的。
解决方案:1.做模糊等后处理的时候,中间buffer使用低分辨率RT。2.可以偶尔几帧使用后处理做一下效果,尽量不要一直使用后处理。3.只在高端机默认打开后处理,而且增加游戏选项,使得玩家可以自己选择是否打开后处理。
诡异事件:1.Camera的clear flags为depth only的时候一定避免同时挂载后处理(Unity的bug),否则FPS会暴降到10一下。
分析:纹理的使用既影响带宽,又影响内存。
解决方案:1.使用合理的格式图片:比如没有使用alpha通道的RGBA图片,格式改为RGB。2.关闭纹理的Read &Write功能,否则内存会增大一倍。3.使用压缩纹理:a.低端android手机(OpenGL ES2.0)使用etc1格式,由于etc1不支持alpha,那么将带alpha的纹理中的alpha通道,分离成一张新的贴图(缺点:增加一张贴图),将alpha信息转为RGB值的任一通道,保存上去。压缩比:假如有3张1024*1024的纹理,32bpp,原纹理的大小为4M*3=12M,压缩后变成4张ETC1的纹理(3张保存正常RGB值的纹理和1张保存3份alpha通道的纹理),4bpp,大小为0.5M*4=2M,压缩比:1/6。b.高端android手机(OpenGL ES3.0)使用etc2格式。RGB的纹理压缩后为4bpp,RGBA的纹理压缩后默认为8bpp,但是如果alpha通道只有1bit,也就是alpha的取值只有0或者1,那么强制压缩成RGB+1-bit alpha ETC2,也将为4bpp(UI贴图大部分都可以这样处理)。压缩比:1/8~1/4。c.iOS手机使用PVR格式,支持alpha通道,压缩后为4bpp,相同尺寸的RGBA纹理和RGB纹理,压缩后,大小相同,效果RGB贴图更好一些,因为损耗小一些。所以如果希望效果好一些,也可以参照ETC1的alpha通道分离做法。PVR贴图必须是正方形。压缩比:1/8。4.使用合适大小的纹理尺寸。假如1080*720的屏幕上要显示一个人物头像,头像占据屏幕的64分之一大小(宽高各占8分之一),那么人物头像的贴图只需要135*90大小,那么如果传入一张512*512的人物头像贴图,不仅占带宽,还降低采样效率。a.纹理尺寸必须是POT(power of two)。b.使用合适尺寸的贴图,只要能满足在最大分辨率的屏幕上,无需通过拉伸(比如在上述例子中,纹理135*90大小即可)即可。c.使用mipmap,可以有效降低渲染带宽的压力,但是这会给内存增加3分之一的负担。3D场景模型和角色建议开启Mipmap功能,UI纹理不要开启了Mipmap功能。当内存压力不大,而FPS尚未达到要求(bound在带宽上)的时候,可以通过打开texture mipmap,减小带宽压力。5.纹理rgb565+dither的效果不弱于rgba8888。6.使用ASTC(iOS需要A8+,iPad Mini3、iPad Air、iPhone5s不支持,iPad Mini4、iPad Air2、iPhone6支持;Android OpenGL ES3.2以上才能完美支持)
诡异事件:1.以目前的手机,4张1024的纹理比一张2048的纹理好。2.严格控制RGBA32纹理的使用,不仅增大内存,而且加载时间大幅度提高,在保证视觉效果的前提下,尽可能采用“够用就好”的原则,RGBA16的加载速度和etc、pvr的相近。在加载时间这个问题上,分辨率、mipmap也会导致加载时间不同,但是鉴于其内存大小不同,所以加载时间不同可以理解,并属于合理范围。
分析:Material由Shader和Texture组成。其中Shader决定了针对单个像素点的运算量。如果运算量比较大,那么GPU压力就会大。变种过多的话,会大幅度增加Shader资源加载解析时间。
解决方案:1.避免使用Fallback,减少Shader变种。2.更新ShaderVariantCollection,通过ShaderVariantCollection明确被需要的Shader变种,使得常用的Shader可以在切换场景的时候被解析,同时降低解析时间,以防这些Shader在第一次被使用的时候进行解析,造成卡顿。3.shader lod:类似于纹理mipmap,Unity提供了shader lod的机制,在写shader的时候可以设置该shader的lod值,然后通过全局变量Shader.globalMaximumLOD设置最大的LOD值。LOD超过该阈值的shader将不被加入计算。可以用于高低配手机中。4.避免alpha test:移动GPU中多数使用的是基于tile的结构,tile结构会在PS之前进行depth test,也就是传说中的Early Z,这样会大幅度避免overdraw的问题。然而如果使用alpha test,就会牵扯到对像素点进行discard,导致Early Z失效,Overdraw问题出现。当然有时候alpha test无法避免,比如绘制树叶等。a.如果树叶是固定视角观看,且将shader改成alpha blend可以接受,使用alpha blend。b.把叶子用模型抠出来。c.如果必须要alpha test,那么使用的texture越小越好,256为最佳尺寸。4.还有一些美术,用alpha test纯属是为了使用alpha抠图,那么直接使用带Z写入的alpha blend即可。5.使用materiapPropertyBlock,这样有如下好处:a、当多个物件使用相同材质球,只是属性不同的时候,依然可以合并DC(比如:unity地型引擎正是使用材质属性块来绘制树的,所有的树使用的是相同的材质,但是每棵树有不同的颜色,缩放和风因子);b、修改材质的话会生成instance,但是修改materialPropertyBlock就不会;c、修改materialPropertyBlock的耗时是直接修改material的1/4。
其他:1.避免使用shader_feature,因为在将Shader独立打AssetBundle包的时候,Shader变种会被抛弃。
分析:Mesh既影响带宽,又影响内存。Mesh资源的数据中经常会含有大量的Color数据、Normal数据和Tangent数据。其中,Color数据和Normal数据主要为3DMax、Maya等建模软件导出时设置所生成,而Tangent一般为导入引擎时生成。更为麻烦的是,如果项目对Mesh进行Draw Call Batching(static batch,Dynamic batch没问题)操作的话,比如,100个Mesh进行拼合,其中99个Mesh均没有Color、Tangent等属性,剩下一个则包含有Color、Normal和Tangent属性,那么Mesh拼合后,CombinedMesh中将为每个Mesh来添加上此三个顶点属性,进而造成很大的内存开销。由于只有在使用实时光照的时候需要法线,只有在使用normal map的时候需要法线和切线,那么当烘焙结束后,如果不需要的话,可以直接通过修改fbx的import setting,将mesh的法线和切线设置为none。这样可以节省内存。而当Mesh中顶点数量较多的时候还影响了GPU。
解决方案:1.mesh lod:类似于纹理mipmap,Unity提供了mesh lod的机制,针对一个模型做多个mesh,当近距离观察mesh和远距离观察mesh的时候,使用不同的mesh,但是会增加culling耗时。2.优化几何体:当mesh中一个点的某个属性存在有多个值的时候,比如某个点有两个UV值,或者两个法线信息,那么在GPU中就会认为这是两个点,计算量增加一倍。a.避免硬边。b.避免纹理衔接。
内存方面:1.关闭Mesh的Read &Write功能:否则内存会增大一倍,AB也有所增加。2.一般mesh信息包括position、color、uv、uv2、normal、tangent,所以删除任何一种信息,都可以节约大概1/6的内存。当mesh放在AB中的时候,删减任何一种信息,会大幅度减少AB大小。3.修改FBX中的mesh compression也可以减少mesh所占的内存大小,如果效果可以接受的话,high的压缩,内存可以减少1/3,但是亲测质量差距比较大,不太建议开启。4.通过inspector中的压缩来压缩,但是会有损耗,而且在运行时大小没变化,只是减小了包体大小,所以用的很少。
分析:DC合并的好处太多了,即使是现在metal和vulkan的时代,已经对DC不敏感了,但是切换渲染状态,做渲染之前的准备工作还是很耗时的。Unity提供三种合并方式,两种被动合并static batch和dynamic batch,和一种程序员主动合并StaticBatchingUtility。Dynamic batch是在运行时动态合并,最坏情况下,每帧都要执行一次合并mesh操作,耗费CPU时间,减少DC。Static batch是在运行之前先将mesh合并,只合并一次,但是会耗费内存,减少DC。StaticBatchingUtility和static batch合并类似,但是主要用于动态加载资源(动态加载超大地形)后,根据程序员的意愿合并,且合并后可以让物件进行整体移动(普通的静态批处理后的物件无法移动)。而且由于一个mesh顶点数量不能超过65535,所以static batch不太可控,而StaticBatchingUtility可以由开发者控制合并。需要注意的是,游戏性能并非Draw Call越小越好。这是因为,决定渲染模块性能的除了Draw Call之外,还有用于传输渲染数据的总线带宽。当我们使用Draw Call Batching将同种材质的网格模型拼合在一起时,可能会造成同一时间需要传输的数据(Texture、VB/IB等)大大增加,以至于造成带宽“堵塞”,在资源无法及时传输过去的情况下,GPU只能等待,从而反倒降低了游戏的运行帧率。Draw Call和总线带宽是天平的两端,需要做的是尽可能维持天平的平衡,任何一边过高或过低,对性能来说都是无益的。
解决方案:1.为了合并DC,可以将纹理合并。最好也尽可能合并mesh,若干小物件合成一个物件毫无疑问会减少DC。2.在内存压力不大的时候,尽可能将不移动的物件/组件,使用static batch。针对材质相同的物件/组件,会合并DC,针对材质不同的物件/组件,虽然不能合并DC,但是由于mesh已经合并在一起了,所以减少了传输VBO、IBO的过程,减少了DC之间的状态切换,所以也是很好的。3.无法使用static batch的时候,尽量使被Dynamic batch合并的单个mesh顶点属性总和不超过900个(比如mesh中包含顶点坐标和顶点颜色,那么顶点数量不能超过450个,如果又包含法线信息,那么数量不能超过300个)。保持被合并的mesh属性一致,如果有的mesh有顶点颜色,有的mesh没有顶点颜色,那么在合并的时候会统一补上顶点颜色。4.合并后使用的材质shader中无法再使用模型坐标,如果需要模型坐标,那么将其通过顶点颜色等方式传入。另外每个mesh需要的不同参数,也可以通过顶点颜色等方式传入。总之是为了能够共用材质,达到合并DC的目的。5.注意渲染顺序,不透明物件默认渲染顺序是从前到后,半透明物件默认渲染顺序从后到前,只有渲染顺序挨着的两个mesh,才能合并。可以通过自定义RenderQueue的方式强制合并,但这样又要注意绘制的前后顺序,造成多余的overdraw的话,反而得不偿失。6.如果材质shader中使用了很多pass,那么只有最基本的pass会合并,其余pass不会被合并,所以如果在被合并的mesh中使用另外的pass,需要三思。7.通过Culling Distance(Camera.layerCullDistances)去除一些场景中的小物件(花草)或者较为耗时的物件(粒子特效)等,方法就是把这些要剔除掉的物件放在特定layer,然后通过layerCullDistances设置该layer的消隐距离,比如camera的远裁剪面为100,而该layer的layerCullDistances为10,那么当该layer的物件距离超过10的时候,就会被cull掉。这样CPU、GPU、带宽都节省。8.GPU Instance:当多个使用相同mesh的小物件出现在场景,可以对其使用GPU instance,通过一个DrawCall绘制,节约GPU和内存。OpenGL ES3.0新特性,开启的话不影响OpenGL ES2.0正常效果。使用Gpu Instance一是可以省去实体对象本身的开销,二是能够起到减少Drawcall的作用,同时还能减少动态合批的cpu开销,静态合批的内存开销。针对很大概率不会被cull掉,且不需要进行特殊交互(比如物理碰撞等需要boundingbox)的物件,通过GPU Instance API DrawMeshInstanced,避开culling,会比直接勾选GPU instance节省2/3的时间开销。
其他:1.如果想修改共享材质,在代码中一定要使用Renderer.sharedMaterial,才能保证修改会应用到所有mesh上,而如果使用Renderer.material修改材质,Unity会创建该材质的复制品。2.AssetStore中有插件可以合并mesh、材质,甚至提供模型的简化:Mesh Baker,SimpleLOD。不过这两款插件笔者尚未测试过。
分析:动作类游戏中存在大量的动作资源,目前Unity中使用GPU skin还比较少,所以动作模块也是CPU的耗时大户。
解决方案:1.CullMode尽量设置为cullcompletely,这样会在不可见的时候完全禁用,也就是处于摄像机外的时候停止更新。Cullupdatetransform只是部分剔除。2.GPU Skin
内存方面:1.Animation为关键帧形式,所以可以通过减少关键帧,以及删除每个关键帧中不用的骨骼信息的方式,减少内存大小。
分析:OC是一个很好的特性,但是使用起来需要非常小心,因为它是用CPU换GPU的一个过程:通过在CPU计算哪些物件可见,哪些物件不可见,减少GPU的运算量。
解决方案:1.OC最适用于室内场景,不适合与室外开阔场景,因为没有什么东西被挡住了。2.OC使用必须bake,不然实时计算会很耗。3.必须非常好的区分设置遮挡物和被遮挡物,比如小件物体就不用被设置为遮挡物了,因为它什么都遮不住,还会增加运算。
场景切换最主要做的工作就是资源切换,卸载上一场景的资源,加载下一场景的资源以及做一些准备工作。
从内存峰值上考虑,应该先卸载,卸载干净再加载,这样的话就会导致一些资源刚卸载就重新加载,再牵扯上一些准备工作,就会导致场景切换时间变长。而反过来,先加载新的资源,再把不用的资源卸载掉,确实会避免资源出现这种刚卸载就加载的情况(因为两个场景共用的资源就不用卸载了),但这样就会导致内存峰值变高,所以究竟使用哪个方案,或者两个方案同时使用,还是需要根据实际情况判断。目前我们的项目除了一些资源是切场景不做任何处理(也就是gameobject执行了DontDestroyOnLoad函数),其他资源还是会先全部卸载,再重新加载。
低端手机关闭Shadow Map(因为会根据光源空间对全场景layer符合的物件再次计算culling,所以会使Culling耗时增加一倍)(Patrick:SRP貌似不会遇到这个问题?)
新项目优化日志
- fps
- DC
- RenderState
- Shader的ALU(能放在VS的工作尽量放在VS,特别是UV坐标,尽量进了PS后就不改UV了,因为根据TBDR架构,有可能会有纹理预取)
- Overdraw/fillrate
- bandwidth带宽(CPU->GPU传输,比如纹理上传,只上传一次就好;GPU显存->GPU芯片,比如shader中读取纹理,每帧都读取)
- OverShading(过找色/过渲染)
- 内存
CPU的耗时(关注DC、material的使用情况,尝试使用Texture2DArray)
SetPass:1.材质切换(避免出现Material Instance)。2.一般setpass会小于DC,但是如果一个非loop的粒子系统在stop后没有被disable,引擎还是会切换到该粒子系统的材质,然后因为该粒子系统里面是空的,则会跳过DC,结果就是setpass会大于DC(经常出现在:角色技能)。
Batch和DC是一样的,Batch不解释,DC对应底层glDrawElements这个API。但是在Unity的历史上5.0-5.3的版本出现过DC大于batch的情况。因为针对static batch,目前的做法是根据裁剪得到的indices,不停地改变和合并成一个巨大的IBO,然后一个DC绘制出来。但是在5.0-5.3版本中,没有去合并成一个IBO,而是分成很多小的IBO,然后多次DC绘制,因为不改变state的多次DC比不停的合并IBO要省。但是现在Unity又使用了DC=Batch的方案,原因不明。
使用MaterialPropertyBlock避免出现Material Instance
Texture2DArray,需要在runtime通过脚本生成,1.降低glBindTexture操作次数(三星S6 1次glBindTexture的耗时在0.01ms左右),适合场景中存在大量、多次采样的同种材质。2.针对相同mesh 通过GPU instance buffer实现不同贴图和参数,合并GPU instance的功能。3.针对不同mesh,则通过uv、color等属性记录index、color等信息,实现材质相同,然后针对UI这种顶点数小于300的物件,可以通过dynamic batch大规模降低draw call,而针对场景静态物件,也可以通过这种方式,大规模降低draw call
GPU的耗时(关注OverDraw、纹理mipmap,关注mesh的渲染密度和屏占比,关注shader的屏占比)
通过vendor提供的工具,获取shader的instruction(指令集)、cycles(GPU要转多少圈能算完。屏占比比较高的物件PS cycles建议小于10)。做了个实验:20%屏幕standard,GPU 23ms,60%屏幕,GPU 30ms,100%屏幕,GPU 50ms。


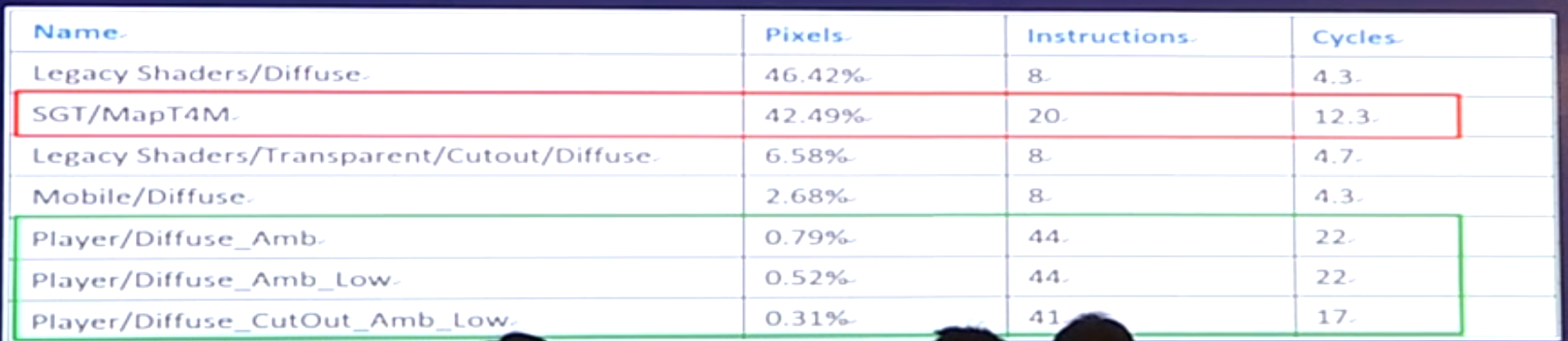

1.全屏UI关闭主相机。2.半屏UI可根据需求将场景渲染成背景RT。3.使用rect mask代替mask。4.empty click ui(使用mt4recast代替空纹理)。5.off screen particle(其实就是先绘制到一个小分辨率(比如1/4分辨率)的RT上,但是这样原本很多层的深度检测,现在只剩下了一层。好处就是overdraw变成了1/4 * overdraw + 1)。
Unity原生overdraw有些问题:因为用shader replacement做的,所以不透明的也会叠加。
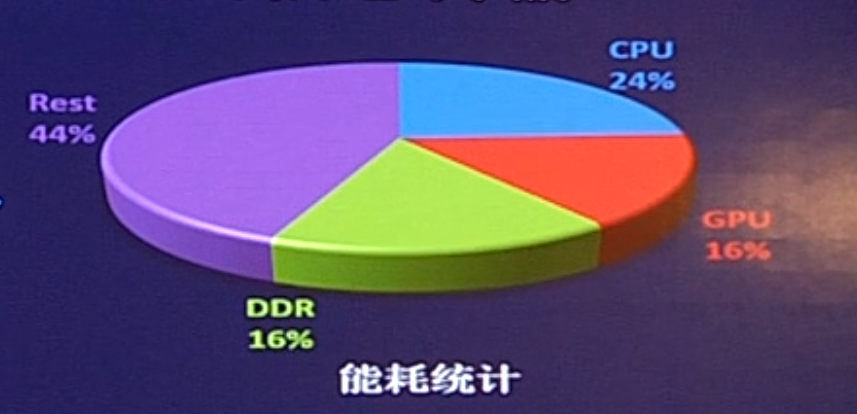
texture > framebuffer > mesh。而且带宽也很影响能耗,如下图所示,为一个游戏的能耗占比。rest > CPU > GPU = 带宽
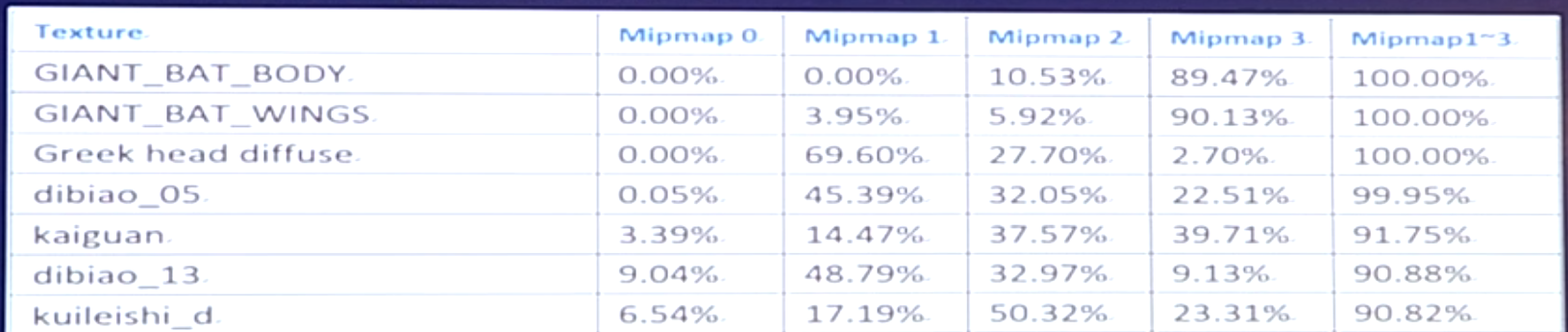
textue解决方案:1.开启mipmap(CPU -> GPU是所有层级全部传输,传过去后,texture被GPU缓存。然后GPU显存->GPU芯片,使用mipmap的话,会减少cache miss)。2.纹理压缩(善用dither)。3.使用合适尺寸的texture,如下图。
mesh解决方案:1.实时阴影:fast shadow receiver。2.减少dynamic batching,因为每帧都会生成vbo进行CPU->GPU的传输,所以尽量替换成static或者instance。3.skinned mesh,因为每帧都会根据动画进行CPU蒙皮(即使是idle),然后把蒙皮结果传输给GPU,所以尽量替换成GPU skin。3.粒子系统,每帧都要更新粒子的位置等信息,所以每帧都需要从CPU往GPU传输,尽量替换成GPU 粒子。4.tessellation,在GPU生成顶点,降低带宽压力。
由于GPU的渲染单元并非以像素为单位,而是以2*2或者4*4的方格渲染,那么在绘制小面积或者狭长三角形的时候就会出现overShading,比如下左图浪费了75%的GPU开销,右图浪费了67%的GPU开销

所以要将Mesh 减面/LOD,概念一:渲染密度(每1万像素的顶点数),建议渲染密度小于1000,否则就减面/LOD。概念二:渲染屏占比(某个物件在屏幕中的像素数),建议渲染屏占比小于1000的,就直接删掉吧。
最近为了包体大小原因,清空了Resources文件夹,同时为了热更新,启用了AB模式,但是使用AB模式后第一个遇到的问题就是内存爆掉了(iPhoneX,1.4G),原因如下:
1.dll 300M,因为没有开strip code,打开后会有报错,原因是有些类被优化掉了,fix后,dll 236M,依然很大,原因是新版本Unity即使空工程也有90M左右,不过就不深究了,毕竟UWA也说了,开发团队不用太担心该选项的数值,很多应用均在共用这些库,并且它对于真实项目的内存压力非常小,几乎没有影响,而且OS也不会因为该内存而杀掉游戏或应用。;
2.Shaderlab 300M,原因用了standard,同时,没有打开SVC,解决方案:将所有使用standard的材质球替换成自定义材质球,同时删除项目中所有的default-material和default-particle system material,其实这俩material没有用,只是我们项目默认关闭了fbx的import material,然而又没有给其指定一个新的material,导致使用了default-material。而默认创建的particle system会使用default-particle system这个材质球,所以我们工具组重写了editor,使得创建的新的particlesystem会使用我们自定义的一个material。另外SVC虽然关联了使用的shader,但是没有指定keyword,导致变体太多,所以手动指定keyword了
3.AnimationClip,148M。解决方案:1.Anim.Compression->Optimal,2.压缩AnimationClip文件float的精度(压缩浮点数精度,文件大小、AB大小、Editor下的内存大小都会变小,但是真机的内存大小不会有变化,因为每个浮点数固定占32bit,除非是刚好减少了几个曲线,但是在打开optimal的时候已经考虑过误差了,所以很难再减少几个曲线),3.去掉AnimationClip中的无效曲线:例如ScaleCurve(这个效果会比较明显,但是由于我们项目中部分animationclip用到了scaleCurve,虽然可以跳过这些有数值的scale曲线,但是依然会有问题,因为假如一个动作将scale设置为2,然后下一个而动作scale曲线被删掉了,则scale就会一直保持为2,而非还原为1了,即使我遍历所有的动作文件,记录下所有有scale信息的骨骼,但是万一又增加了新的动作,新的带有scale的骨骼,那么老的scale已经被我删掉了,还要将其还原,虽然只是还原一个全是1的曲线。最好的解决办法是修改unity源码,给scale一个默认值,或者就让美术在制作的时候针对有scale的骨骼命名规范上就加个scale,所以这个方案作为备选方案),4.使用humanoid替换generic(但是humanoid性能相对较差,所以也作为备选方案。Unity有两套动画系统,legacy和mecanim(generic、humanoid)。mecanim是新的动画系统,使用者更多,且易用性和性能更好。generic和humanoid相比,generic性能更好,因为humanoid会在animator.update中执行retarget和IK,但是humanoid占内存更少,因为它存储在muscle空间,所以曲线更少。),5.简化骨骼名字(这个操作起来略复杂,备选方案+1)
原创技术文章,撰写不易,转载请注明出处:电子设备中的画家|王烁 于 2017 年 10 月 19 日发表,原文链接(http://geekfaner.com/unity/blog6_Optimization.html)