Data-Parallel Compute Processing: Compute Command Encoder
本章讨论如何创建和使用 MTLComputeCommandEncoder object 来 encode data-parallel compute processing state 以及 command 以及 submit them for execution on a device
下面是 perform data-parallel computation 的步骤
- 使用 MTLDevice 的方法创建一个 compute state(MTLComputePipelineState)包含一个 MTLFunction对应的编译好的代码。MTLFunction 对应一个metal shading language 编写的 compute function
- 将该 MTLComputePipelineState 用在 compute command encoder。
- 指定 resource 和 关联的object(MTLBuffer、MTLTexture、MTLSamplerState)用于或者returned by the compute state。设置它们的argument table indices,这样 Metal framework code 可以在sahder code中对应 resource。在任意时间,MTLComputeCommandEncoder 可以关联一些 resource object
- Dispatch compute function 指定次数。
Creating a Compute Pipeline State
MTLFunction 包含 data-parallel code ,可以executed by MTLComputePipelineState。 MTLComputeCommandEncoder encode command 去设置 argument 以及执行 compute function。由于创建compute pipeline state 需要昂贵的编译 metal shading language code,所以可以以block 的方式 或者异步的方式 schdule 这种工作来的到最好的性能
- 同步的创建 compute pipeline state object,可以调用 MTLDevice 的 newComputePipelineStateWithFunction:error: 或者 newComputePipelineStateWithFunction:options:reflection:error: 方法。这个方法会block当前 thread来进行metal 编译 shader code 去创建 pipeline state object
- 异步的创建 compute pipeline state object,可以调用 MTLDevice 的 newComputePipelineStateWithFunction:completionHandler: 或者 newComputePipelineStateWithFunction:options:completionHandler: 方法。这个方法会立即返回。metal 异步的编译 shader code去创建 pipeline state object,然后会调用 completion handler 去创建新的 MTLComputePipelineState object
在创建 MTLComputePipelineState object 的时候,也可以选择同时创建 reflection data 包含 compute function的detail以及argument。newComputePipelineStateWithFunction:options:reflection:error: 和 newComputePipelineStateWithFunction:options:completionHandler: 方法可以做到这一点。如果不需要,则避免创建 reflection data。
Specifying a Compute State and Resources for a Compute Command Encoder
MTLComputeCommandEncoder 的 setComputePipelineState 方法指定 state,包含一个编译好的 compute shader function 用于 data-parallel compute pass。在任意时间,compute command encoder 只能关联一个 compute function
MTLComputeCommandEncoder 方法定义了资源(buffer、texture、sampler state、threadgroup memory)作为argument用于MTLComputePIpelineState 的 compute function
- setBuffer:offset:atIndex:
- setBuffers:offsets:withRange:
- setTexture:atIndex:
- setTextures:withRange:
- setSamplerState:atIndex:
- setSamplerState:lodMinClamp:lodMaxClamp:atIndex:
- setSamplerStates:withRange:
- setSamplerStates:lodMinClamps:lodMaxClamps:withRange:
- setThreadgroupMemoryLength:atIndex:
上述每个方法都将一个或者多个resource 对应到argument,如下图所示
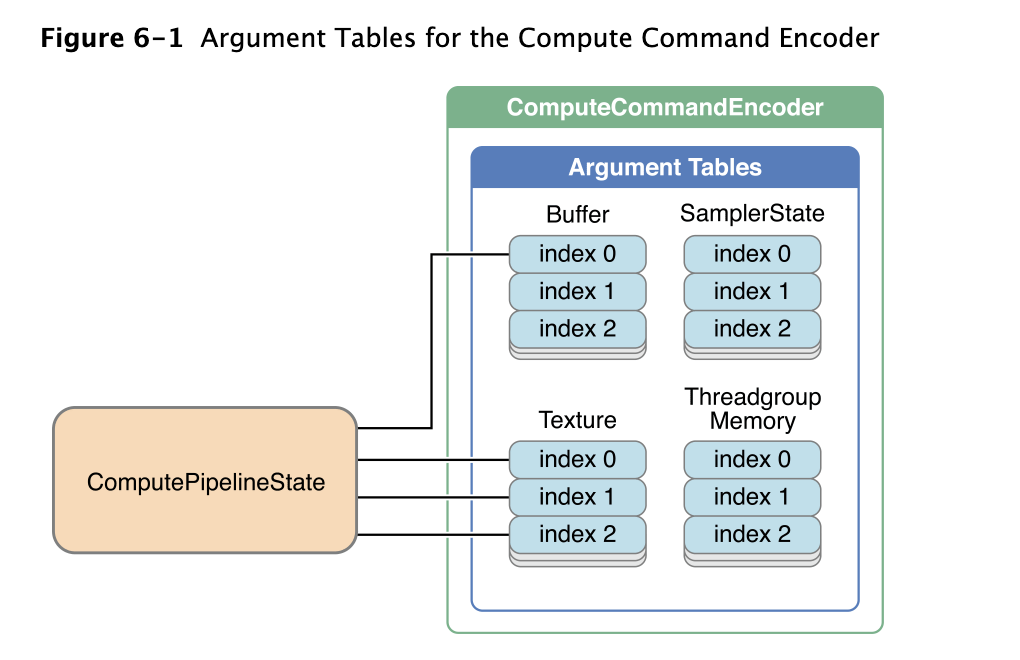
buffer、texture、sampler state argument table 的最大数量限制以及threadgroup memory 的最大限制,参考 Implementation Limits
Executing a Compute Command
调用 MTLComputeCommandEncoder 的 dispatchThreadgroups:threadsPerThreadgroup: 方法去执行 compute function,同时设置了threadgroup 的dimension和数量。可以查询 MTLComputePipelineState 的 threadExecutionWidth and maxTotalThreadsPerThreadgroup 属性去优化 compute function 在当前 device 上的执行
threadgroup中thread 的数量的计算方式是:threadsPerThreadgroup: threadsPerThreadgroup.width * threadsPerThreadgroup.height * threadsPerThreadgroup.depth。 maxTotalThreadsPerThreadgroup 属性指定当前 compute function 在当前设备上 一个 threadgroup 最多可以用的thread数量。
compute command 按照 它们 encoded into command buffer 的顺序执行。当所有thredgroup都完毕切所有结果都写入memory 的时候,该compute command 才算结束。由于这个顺序,一个compute command 的结果可以被用于该command buffer 中之后 encode 的command。
当结束 encoding command 到 compute command encoder 的时候,调用 MTLComputeCommandEncoder 的endEncoding 方法。结束了前一个 command encoder后,可以创建一个新的任意类型的command encoder encode 其它command到当前command buffer中
Code Example: Executing Data-Parallel Functions
下面例子,创建和使用 MTLComputeCommandEncoder 执行针对一个 image transformation on specified data 的 parallel 计算(本例子不展示 device、library、command queue、resource 的创建和初始化)。这个例子创建了一个 command buffer然后使用它创建 MTLComputeCommandEncoder。然后创建一个 MTLFunction,并对应从 MTLLibrary 加载的 filter_main。然后这个function被用于创建 MTLComputePipelineState object 叫做 filterState
该compute function 针对 image inputImage 执行 image transformation 和 filter 操作,并将结束返回到 outputImage。首先调用 setTexture:atIndex: and setBuffer:offset:atIndex: 方法来将texture 和buffer 指定到 argument table。parasBuffer 指定 image transformation 中用到的数据,inputTableData 指定 filter weights。compute function 按照 2D threadgroup 执行,size 16*16 in each dimension。dispatchThreadgroups:threadsPerThreadgroup: 方法用于 dispatch thread 执行 compute function,然后调用 MTLComputeCommandEncoder 的 endEncoding 方法。最终调用 MTLCommandBuffer 的 commit 方法使得command 尽快被执行
id <.MTLDevice> device;
id <.MTLLibrary> library;
id <.MTLCommandQueue> commandQueue;
id <.MTLTexture> inputImage;
id <.MTLTexture> outputImage;
id <.MTLTexture> inputTableData;
id <.MTLBuffer> paramsBuffer;
// ... Create and initialize device, library, queue, resources
// Obtain a new command buffer
id <.MTLCommandBuffer> commandBuffer = [commandQueue commandBuffer];
// Create a compute command encoder
id <.MTLComputeCommandEncoder> computeCE = [commandBuffer computeCommandEncoder];
NSError *errors;
id <.MTLFunction> func = [library newFunctionWithName:@"filter_main"];
id <.MTLComputePipelineState> filterState
= [device newComputePipelineStateWithFunction:func error:&errors];
[computeCE setComputePipelineState:filterState];
[computeCE setTexture:inputImage atIndex:0];
[computeCE setTexture:outputImage atIndex:1];
[computeCE setTexture:inputTableData atIndex:2];
[computeCE setBuffer:paramsBuffer offset:0 atIndex:0];
MTLSize threadsPerGroup = {16, 16, 1};
MTLSize numThreadgroups = {inputImage.width/threadsPerGroup.width,
inputImage.height/threadsPerGroup.height, 1};
[computeCE dispatchThreadgroups:numThreadgroups
threadsPerThreadgroup:threadsPerGroup];
[computeCE endEncoding];
// Commit the command buffer
[commandBuffer commit];
下面代码为上述例子的 shader code ( read_and_transform and filter_table function 为 placeholders)
kernel void filter_main(
texture2d<.float,access::read> inputImage [[ texture(0) ]],
texture2d<.float,access::write> outputImage [[ texture(1) ]],
uint2 gid [[ thread_position_in_grid ]],
texture2d<.float,access::sample> table [[ texture(2) ]],
constant Parameters* params [[ buffer(0) ]]
)
{
float2 p0 = static_cast<.float2>(gid);
float3x3 transform = params->transform;
float4 dims = params->dims;
float4 v0 = read_and_transform(inputImage, p0, transform);
float4 v1 = filter_table(v0,table, dims);
outputImage.write(v1,gid);
}
本节教程就到此结束,希望大家继续阅读我之后的教程。
谢谢大家,再见!
原创技术文章,撰写不易,转载请注明出处:电子设备中的画家|王烁 于 2022 年 5 月 26 日发表,原文链接(http://geekfaner.com/shineengine/blog51_MetalProgrammingGuide_6.html)