本节内容,来自Discover compilation workflows in Metal
关联阅读:
- Dynamic libraries in render
- Function pointers in render
- Adding functions to archives
- private linked functions
- function sitching
- recap
Hello. My name is Rini Patel, and I'm from the GPU software engineering team. In this session, I'll be introducing the new shader compilation workflows in Metal. The Metal shading language is a C++-based language, and its compilation model closely resembles the CPU compilation model. As GPU workloads are increasing in complexity, Metal has similarly evolved to address the flexibility and performance needed to support the modern use cases. Some common challenges that you may have already faced while authoring your shaders can be sharing utility code across pipelines, modifying shader behavior at runtime without recompilation, or an ability to reuse compiled GPU binaries between application launches.

So, let's walk through a simple shader code and discuss the scenarios. Here, we have a simple fragment shader that returns the result of foo() or bar(), depending on the result of condition. Now, if those functions are called by multiple pipelines, we might want to compile them just once and link them to each pipeline instead.
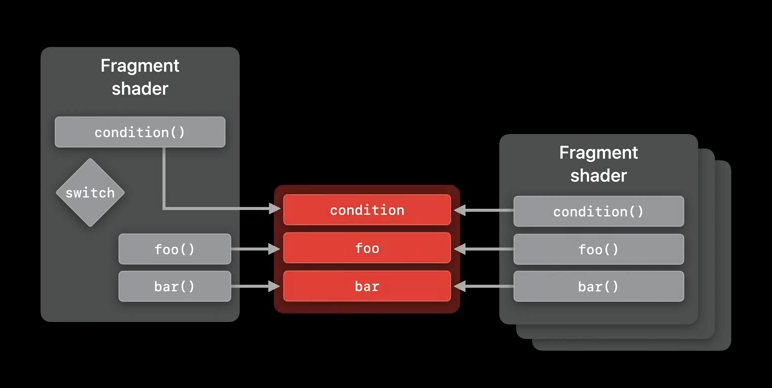
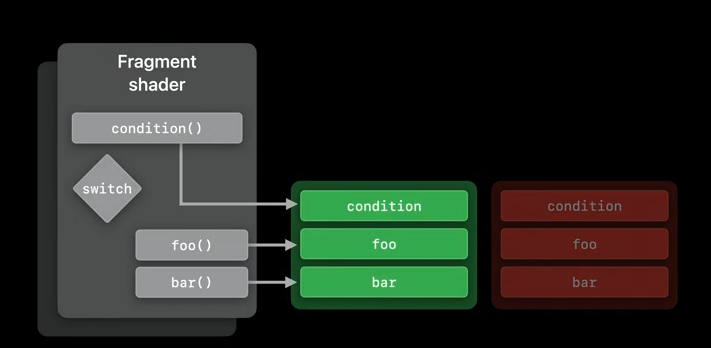
We might need to link a different implementation of these functions at the runtime, or we might need a fragment shader to be extensible in order to handle a new case statement for baz().
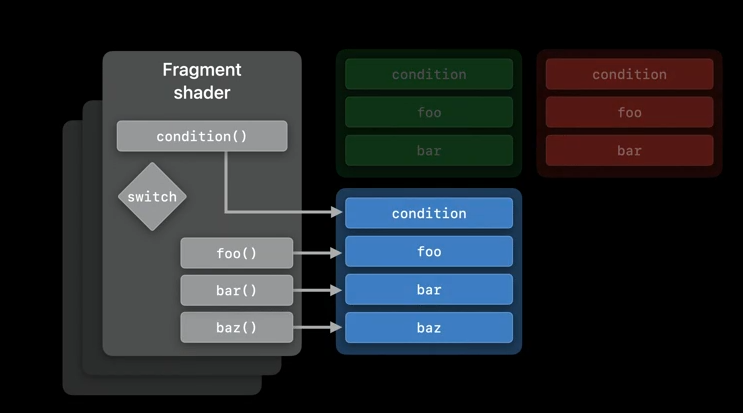
We may also want to be able to call a user-provided function bat() instead of baz() from our fragment function.
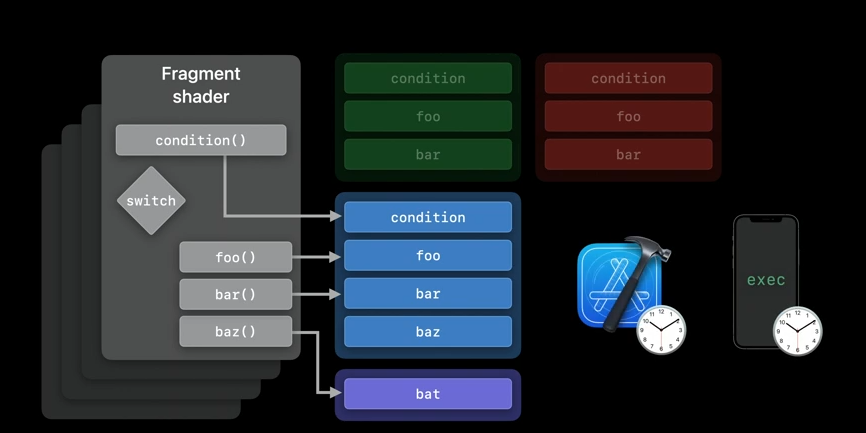
As you can see, there are many different requirements that a shader authoring pipeline may have, and Metal offers various APIs to support different implementations. Each approach will have a different trade-off between compilation time and shader performance. And today, I'd like to talk about the new compilation workflows that will help you find the perfect balance between performance and flexibility. We are going to start with the new support for dynamic libraries for render pipelines, as well as function pointers for render pipelines. We'll talk a bit about the additions to binaryArchive API. Then, we will see private linked functions. And finally, we'll introduce a brand-new feature for stitching visible functions in Metal.

Dynamic libraries in render
So, let's start with the dynamic library support in Metal. Dynamic libraries are a common tool in software engineering. They are shared object files that allow you to compartmentalize utility code into a stand-alone compilation unit. They help reduce the amount of compiled shader code and reuse it between multiple pipelines. Additionally, they allow you to dynamically link, load, and share the GPU binary code.

Last year, we introduced dynamic languages for compute pipelines, and to get more of an introduction to dynamic libraries in Metal, I encourage you to check out our previous year's presentation, "Build GPU Binaries with Metal." This year, we are bringing dynamic libraries to render and tile pipelines. With this added support, you can now share utility libraries across all your compute and render workloads.
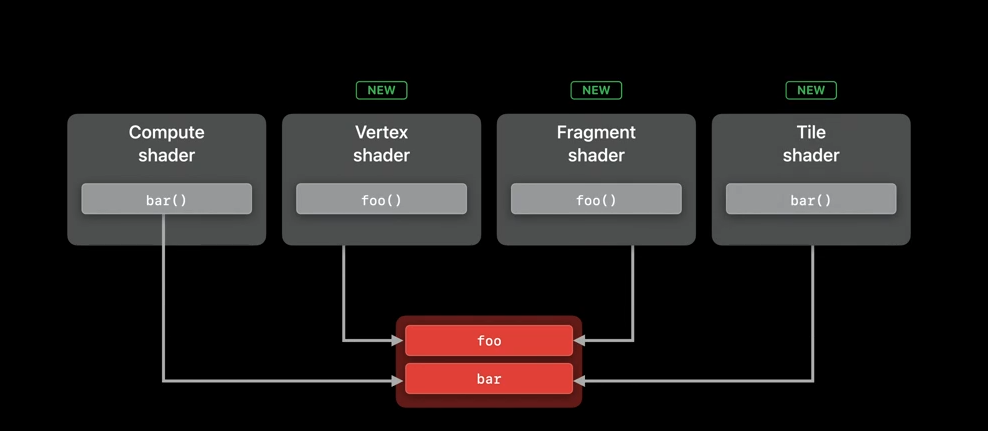
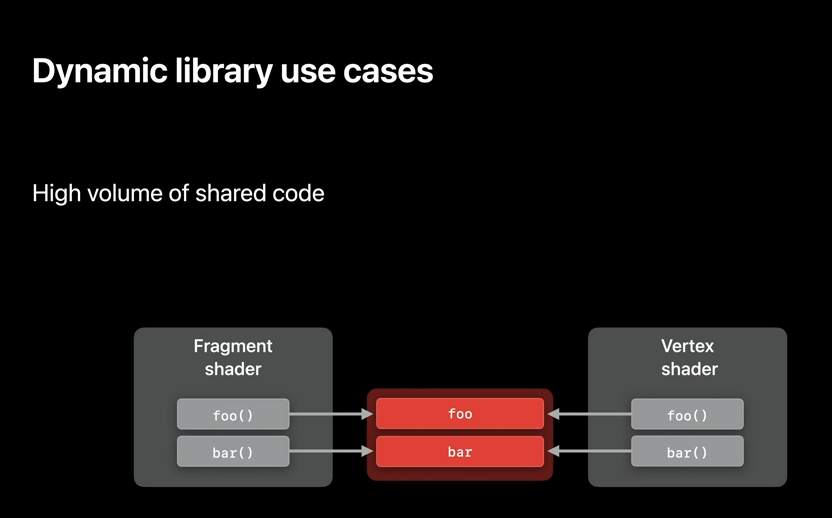
And now that we know what dynamic libraries are, it's time to talk about some of the use cases. Helper functions are often used across general compute, vertex, fragment, and tile shaders. With the addition of dynamic libraries to render pipelines, you can now manage large amount of utility code and share it across all of your workloads.
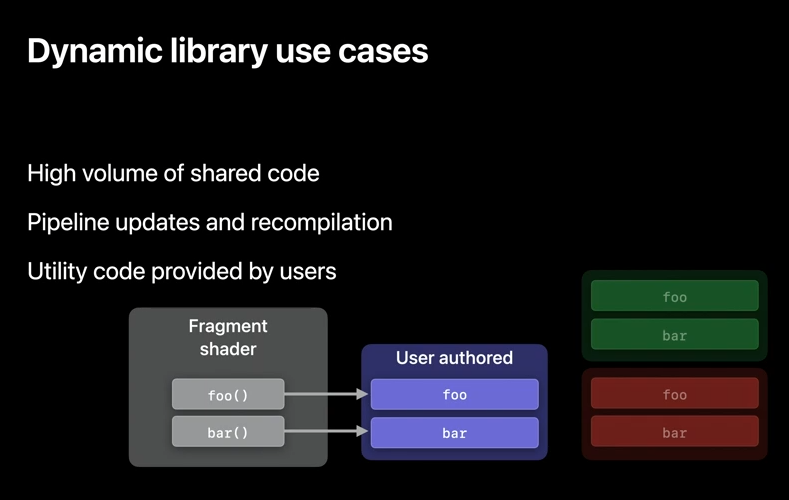
You can precompile the libraries that may be used at runtime without experiencing the compilation slow down, and even swap out functions of the runtime, simply by changing the libraries that are loaded while creating the pipeline.

They also help your users to author shader code that you can load as part of your pipeline without needing to provide the source.
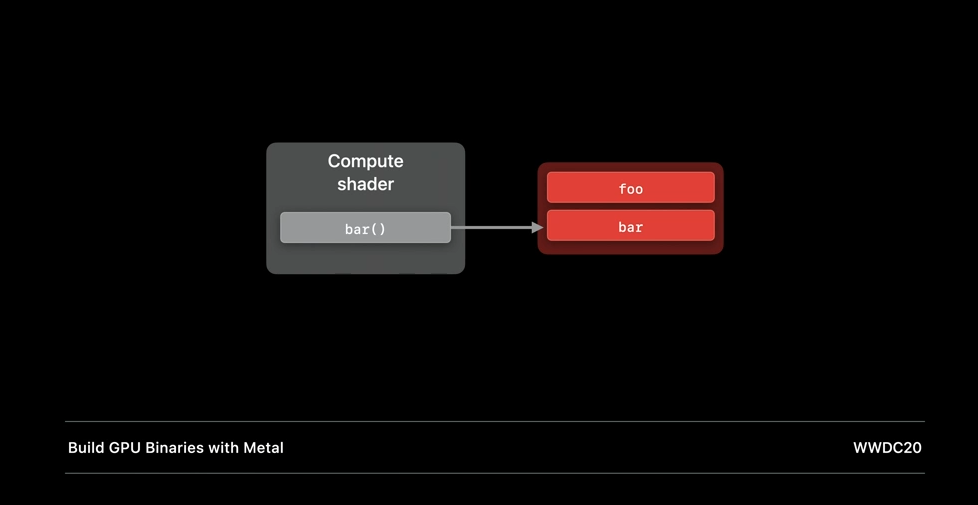
So, we have talked about when to use dynamic libraries. Let's now look at how to build and work with them. In our example fragment shader, we call functions foo() and bar(), but we do not provide the implementation for either at compile time. Instead, the implementation for these functions exist in a Metal library that we later link when creating our render pipeline.
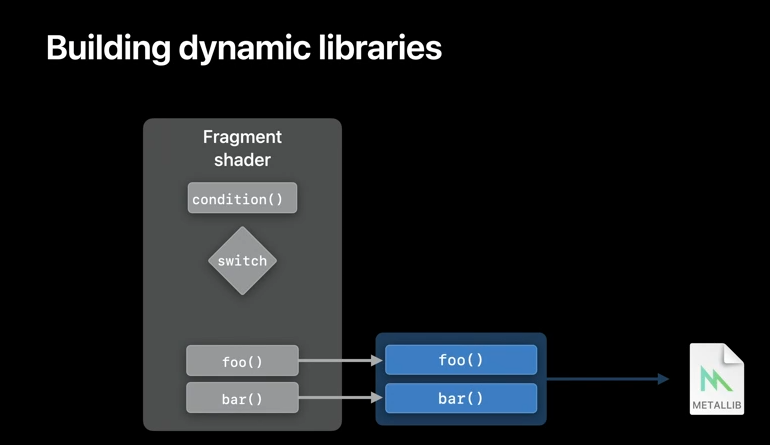
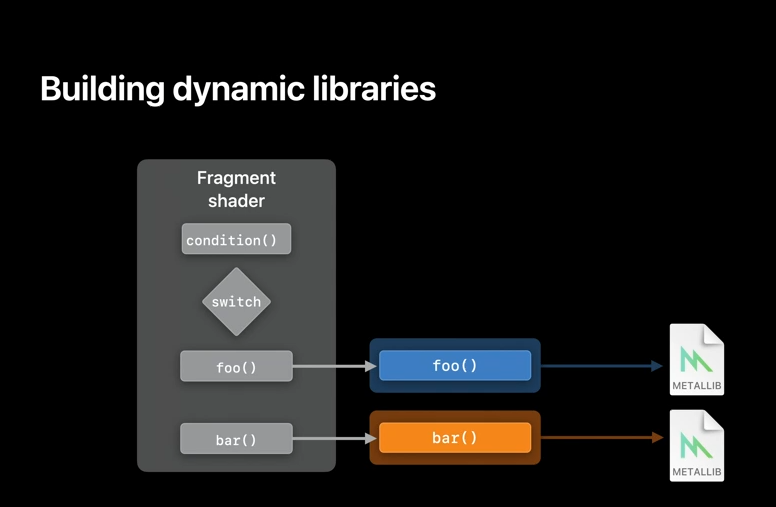
And it's also possible to provide separate libraries for each of the functions that you may use.
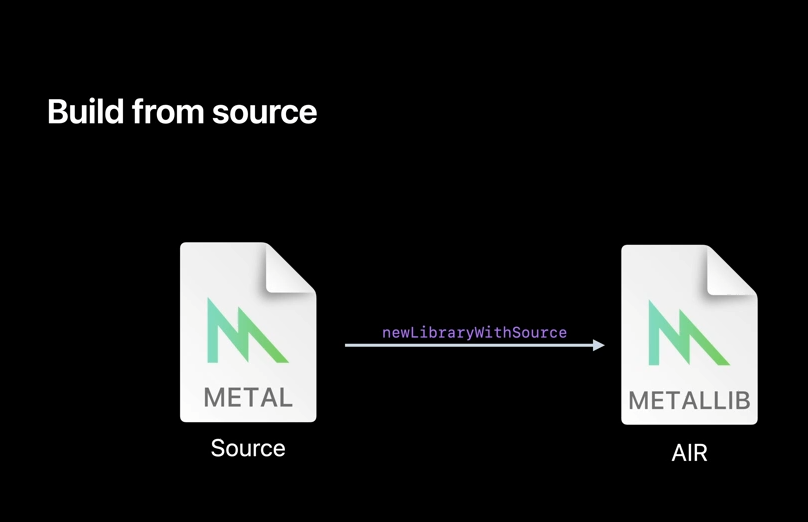
Let's now discuss the tools and flexibilities you have by building dynamic libraries in Metal. You first need to compile your Metal shader source to AIR, and you can do that either by using Xcode's Metal toolchain as part of your build process, or by compiling from source by using newLibraryWithSource API at runtime.
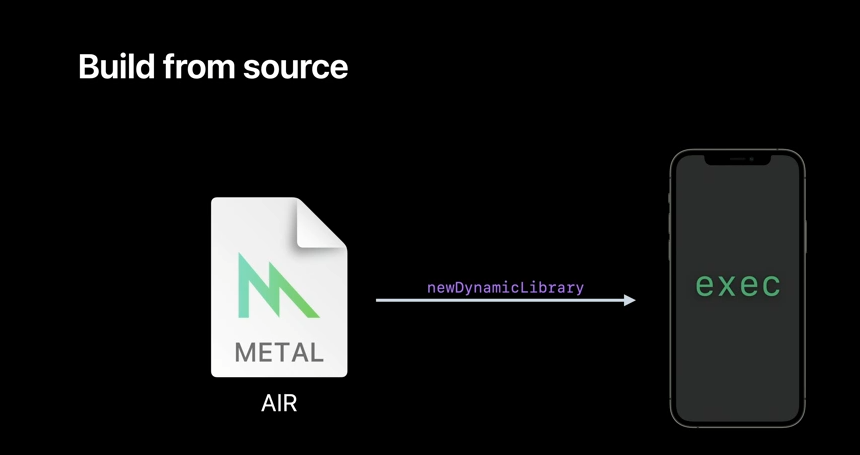
With your compiled Metal shader in AIR, you can now create a dynamic library simply by using the newDynamicLibrary API. This library is ready to be used in its GPU binary format.
But what if you want to reuse it in later runs? To do that, you can serialize your dynamic library to disk, and this can be done using serializeToURL API. And later, you can reuse it by calling the newDynamicLibraryWithURL API.

Let's now go through an example which calls functions from dynamic library and fragment shader. In this example, we declare functions foo() and bar() using the extern keyword, but we do not provide definitions for them. To use them, we simply call these functions from our fragment shader.

And you can provide an implementation for the extern functions when building your Metal library.
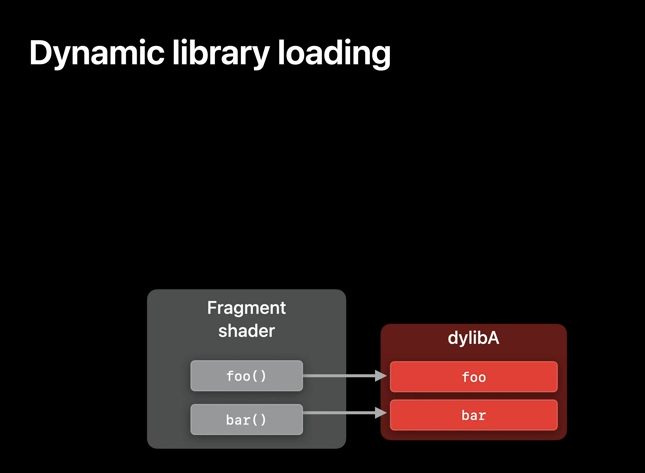
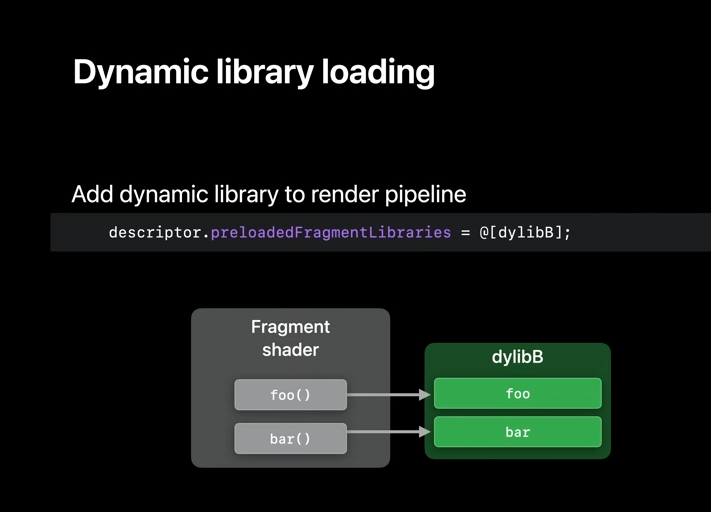
Now, keep in mind that it's also possible to replace those implementations with something different at the runtime. And to do this, you just need to add your dynamic libraries to the appropriate preloaded libraries array. In our case, it's fragment, but a similar property is available for each stage and pipeline. And the symbols will be resolved in the same order in which the libraries are added to this array. This workflow is well suited for experimenting with new implementations.
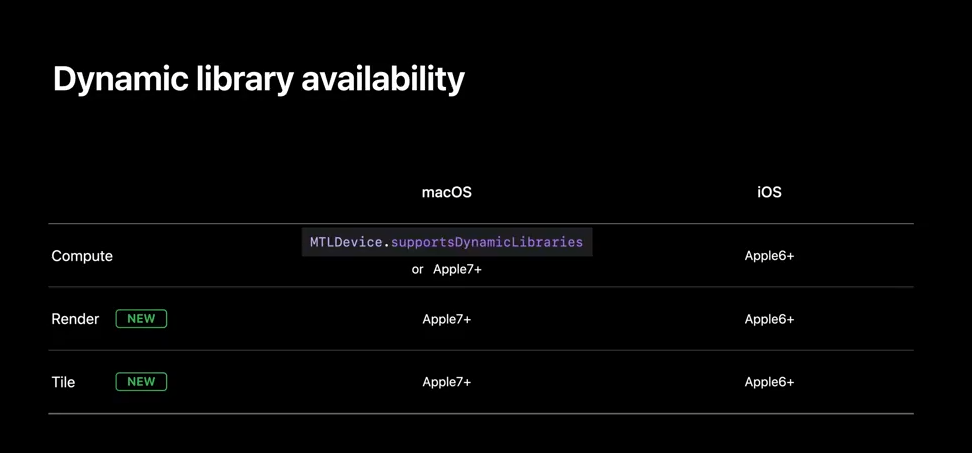
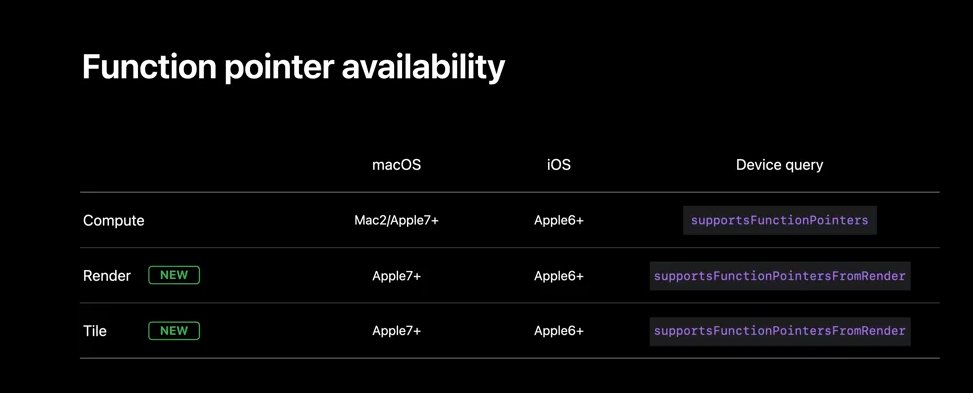
And that's it for the dynamic libraries. If you are looking to use Metal dynamic libraries, the support is available for compute pipelines on Apple GPU family 7 and above in macOS Monterey. It's also available for other GPUs, as well as most Mac family 2 devices, although you’ll need to call Metal device supports dynamic libraries. On iOS 15, this feature is available on all Apple 6 devices and above. Render and tile pipeline support is available on all devices that support Apple 6 feature set.
Function pointers in render
Next, let's talk about the improvements to function pointers coming this year.

Function pointer is a simple construct for referring to a code that we can call to make your code extensible by allowing you to call functions that we have not seen before. Last year, we introduced compute pipeline function pointers, and for that, I recommend you to check out our previous year's presentation, "Get to know Metal function pointers."

This year, we are extending function pointer support to the render and tile pipelines on Apple Silicon. Similar to dynamic libraries, function pointers allow creating customizable pipelines. With function pointers, a GPU pipeline can call code that has not been seen during the pipeline compilation. With function pointer tables, code execution behavior can change dynamically, either when you bind the different function table or when the GPU pipeline indexes into the function pointer table. You can also decide how to balance compilation performance against the runtime performance using function pointers. For fastest compilation, for example, you can precompile function pointers to a GPU binary and quickly deal-in the pipeline. For the best runtime performance, on the other hand, you can have your pipeline reference AIR representations of functions, allowing the compiler to do maximum optimizations.

Let's now see how you can set the function pointers in your code. There are three basic building blocks. We start by instantiating the function, then configuring a pipeline with these functions, and finally, creating function tables. Once this is done, using a new render loop doesn't involve much code.

So let's dive in to the details of each of the steps. To start using function pointers, we first declare the function descriptor and instantiate to compile a GPU binary version of the function. This will accelerate pipeline creation time, and it's as simple as declaring a descriptor and setting the option to compile to binary. When the Metal function foo is created from library using this descriptor, the function will be compiled by the GPU backend compiler.

Next, we need to configure the render pipeline descriptor. First, we add the functions via the pipeline descriptor to the stage where they'll be used, which can be vertex, fragment, or tile stage. We can choose to add functions in AIR or binary form. When adding AIR functions, the compiler will statically link the visible functions, allowing for the backend compilers to optimize the code. Adding binary functions, on the other hand, will inform the driver which externally-compiled functions are callable from a given pipeline.

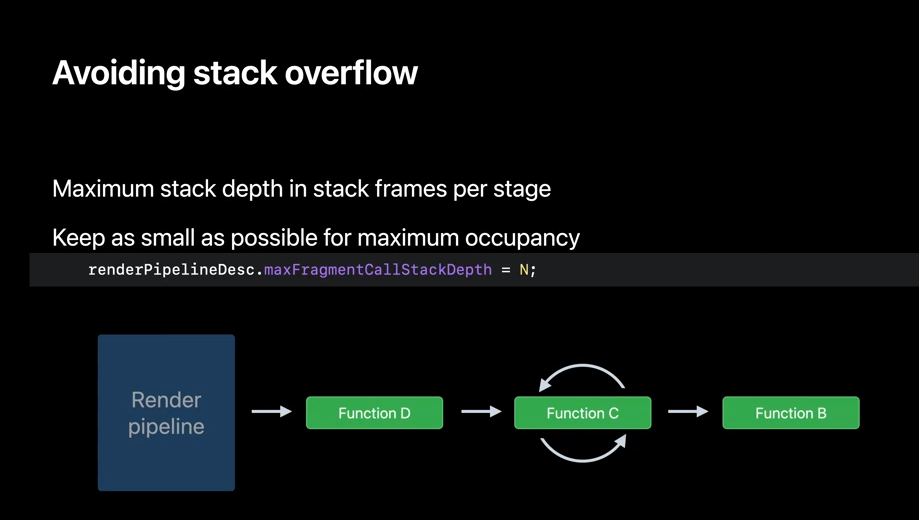
One additional thing to note here is when you create a pipeline that uses binary functions and if the code that you are calling has a complex call chain, as illustrated here, it's important to specify the maximum call stack depth necessary, as the compiler cannot do static analysis to determine the depth. The compiler will default to maximum depth to be run, and you may get a stack overflow if the depth isn't specified correctly. In contrast, specifying the depth correctly leads to a better resource conception and optimal performance. So once the descriptor is fully set up, you can create your pipeline that's ready to use function pointer.
After creating your pipeline, the next steps are to create visible function tables and populate them with function handles in the API. First, we create a visible function table using a descriptor and specify a render stage. Then, we create function handles to reference those functions. Both the function handles and table are specific to a given pipeline and selected stage. You can then insert the handles into the function table using setFunction API.

Let's now see how do you use this function tables after we have done all the set up. First, as a part of the command and coding, we bind the visible function table to a buffer index. In the shader itself, the visible_function_table is passed as a buffer binding, and we can then call our functions through this table. And that was a simple case of using function pointers.

When using function pointers, it's not uncommon to create a pipeline just to find out later that you need to access one or more additional functions.

Now, if you could achieve that by creating the second pipeline from an identical descriptor, which adds the additional functions, but that would trigger a pipeline compilation. To accelerate this process, Metal lets you specify if you plan on extending the original pipeline. This way, a new pipeline can be created faster from an existing pipeline, and it can use all the function pointer tables that were initially created for the original pipeline.
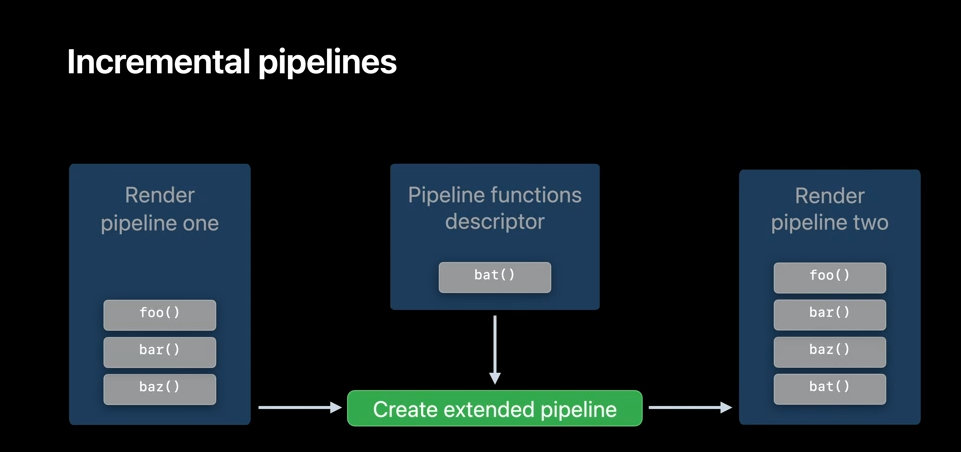
To do that from code, when creating the original pipeline, set supportAddingBinaryFunctions option to YES, for all the stages that you wish to extend. Then when you need to create an extended pipeline, create RenderPipelineFunctionDescriptor and include new binary function bat() on the fragment length function list. Finally, call new RenderPipelineState with additional binary functions on renderPipeline1 to create renderPipeline2, which will be identical, but includes the additional function pointer bat.

And that's pretty much it. Now that we have seen how to use function pointers, here is where you can use them. Function pointers in compute pipelines are supported on Apple GPU family 6 and above, in macOS Big Sur, and iOS 14. They are also supported on Mac family 2 devices. And this year, we are extending function pointer support for render and tile pipelines on Apple GPU family 6 and above, in Mac OS Monterey, and iOS 15.
Adding functions to archives
The next topic I'd like to talk about is managing binary function compilation overhead. Compiling shaders can be extremely time intensive, and you may want to control the overhead it brings to an application. To help with that, we added binaryArchives to Metal last year. BinaryArchives can collect and store the compiled binary versions of the pipeline to disk, saving compilation time and subsequent runs and reducing the memory cost associated with the compilation.

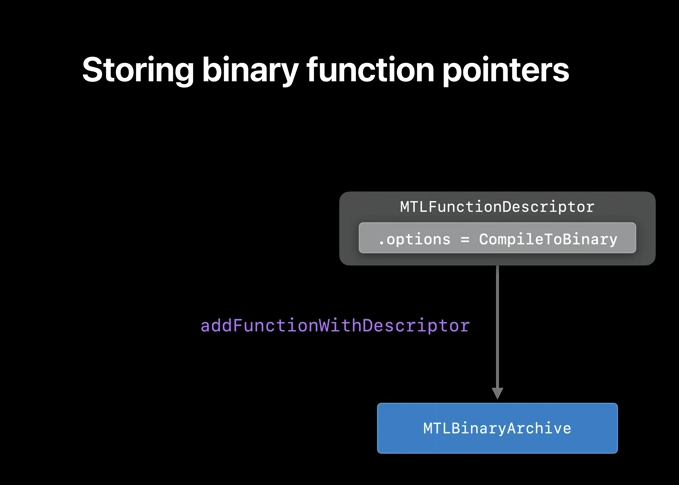
This year, we are adding the ability to store visible and intersection function to binaryArchives, allowing you to significantly reduce the overhead.

So, let's take a look at how you store into and load from binaryArchives. To add a function to BinaryArchive, simply call addFunctionWithDescriptor and pass the function descriptor and source library as arguments.
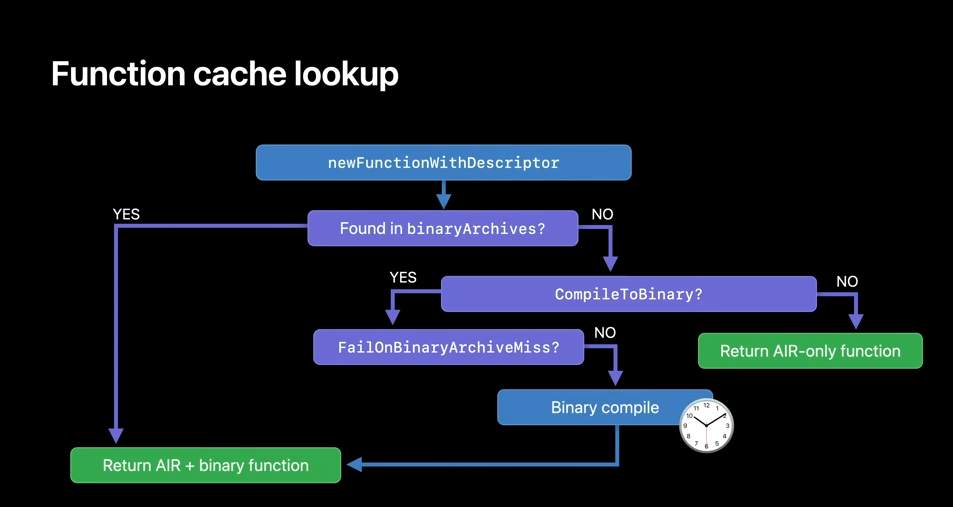
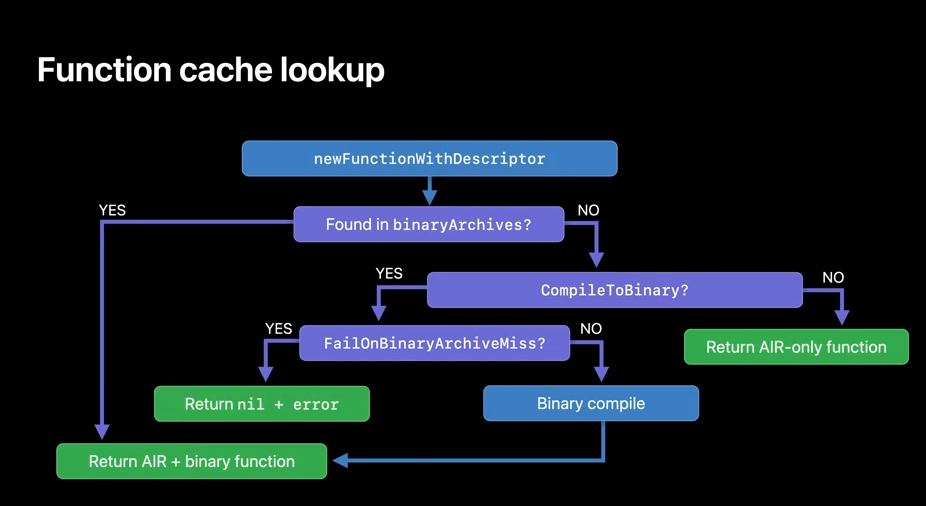
To load the binary function pointer from BinaryArchive, place the BinaryArchive on the function descriptor's binaryArchives array, and then call Metal library method newFunctionWithDescriptor.
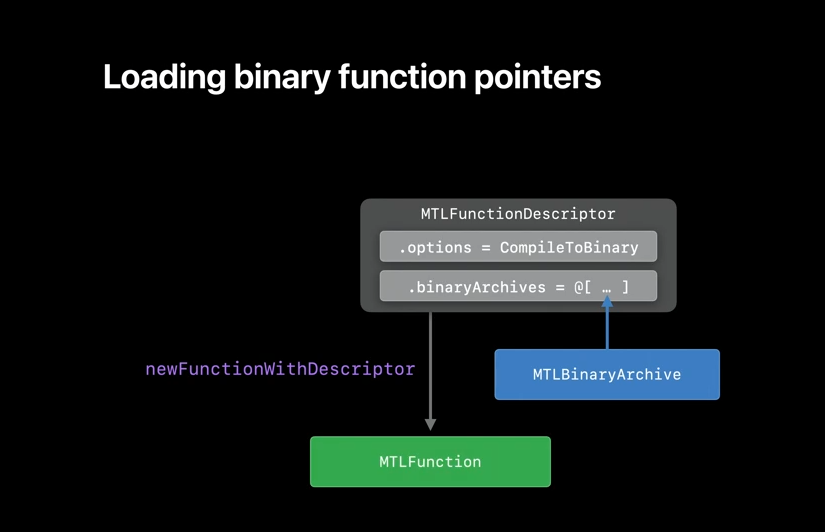
If any of the archives in the array has the compiled function pointer, it will be returned immediately, without having to recompile. Here are some of the rules that illustrate how newFunctionWithDescriptor will behave with the binaryArchives. We first search for the binary version of the function in the BinaryArchive list. If the function is found, it will be returned, and if it's not found, we'll check the CompileToBinary option and return AIR version of the function, if binary compilation wasn't requested. On the other hand, if the binary compilation was requested, then depending on the pipeline option, FailOnBinaryArchiveMiss will either compile the function binary at runtime or return nil.
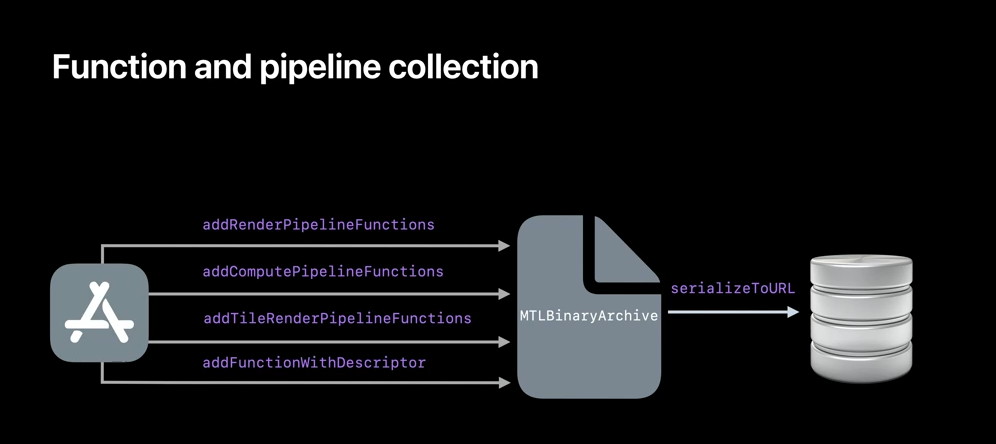
When you integrate MTLBinaryArchive into your application, you can use the same archive to store all your GPU-compiled code. Your render, tile, and compute pipelines, as well as your binary function pointers. And after your archive has been prepopulated with the pipeline state objects and binary functions, you can serialize it to a disk. Collecting and storing your GPU binaries this way will help accelerate shader compilation on to subsequent application runs.
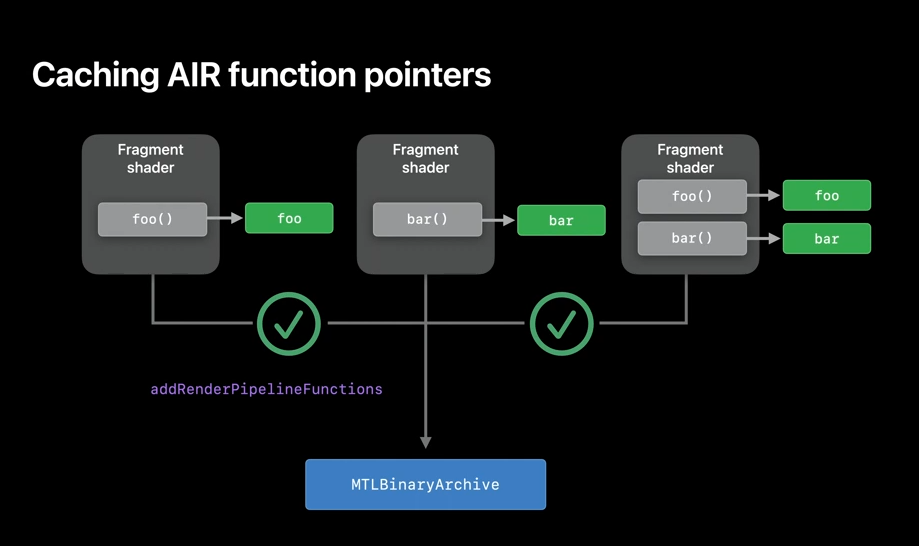
When using a pipeline with function pointers, you might want to cache the pipeline state object itself. But why should you cache when you have a pipeline that comes with different function pointer combinations? For example, here, there are three pipeline descriptors which are identical, except for their user function pointers. So, if you are using AIR function pointers, you need to cache all permutations of the pipeline.
However, when using the binary function pointers, it's enough to cache a single variant because the pipeline binary code doesn't change when a new function pointer is added to it. And you can use that archive to find all other variants of the pipelines, independent of which binary function pointers are used in the pipeline descriptor. To wrap it up, you always want to use binaryArchives in Metal, as it's a great tool to control your pipeline compilation cost.
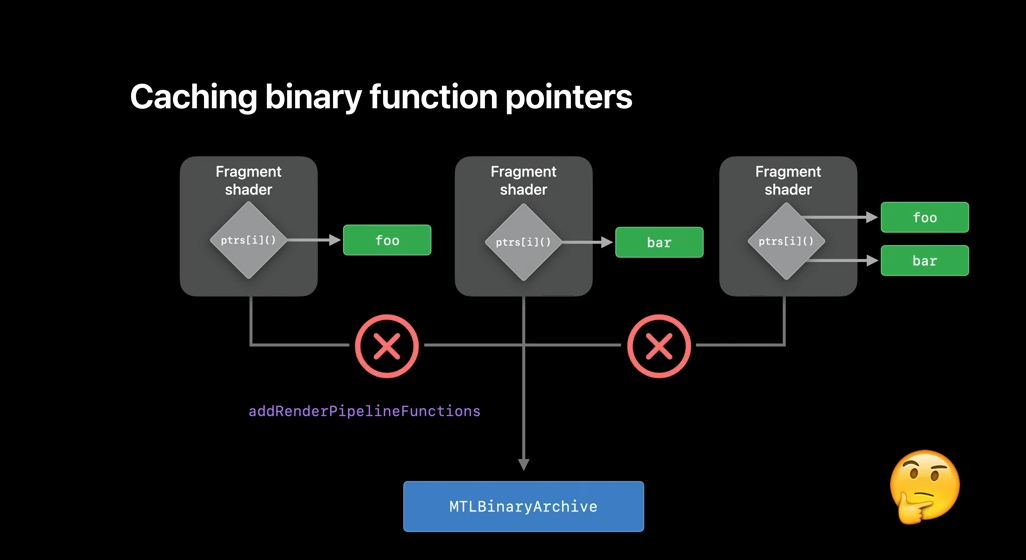
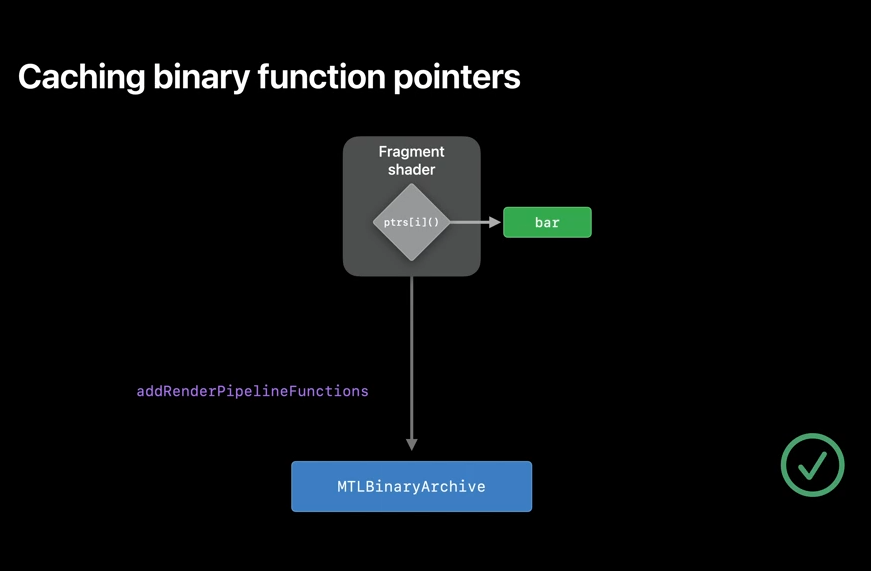
The support for binaryArchives is available on all devices, but adding function pointers to a BinaryArchive depends on the function pointer ability.

private linked functions
Now, I'd like to briefly talk about our next addition this year, which is private linked functions.

So far, we have discussed how dynamic libraries and function pointers provide a lot of flexibility to your shader development pipeline, but sometimes, for performance reasons, you may want to statically link an external function into your pipeline. Last year, we added linkedFunctions API with a support for statically linking AIR functions. However, this requires function pointer support, as these are usable in a function table.

This year, we are introducing privateFunctions. Both functions and privateFunctions are linked statically at the AIR level, but since those are private, no function handling can be made for a function pointer, and this allows compiler to fully optimize your shader code.

So, where are they available? Because this feature works with code at the AIR level, it is available on all devices in macOS Monterey and iOS 15.

function sitching
Moving on to the last addition I'd like to discuss today, function stitching.

Some applications need to generate dynamic content at the runtime. For example, to implement customizations for the graphic effects based on user input. Or, say, complex compute kernel based on incoming data. Function stitching is a great tool to solve this. Prior to function stitching, the only way to do this was by generating Metal source strings. The string-manipulation technique can be somewhat inefficient, and it also implies that the translation from Metal to AIR will happen at runtime, which can be an expensive opration.

So let's take a look at how function stitching works. Function stitching provides a mechanism to generate functions from computation graphs and precompiled functions at runtime. The computation graph is a Directed Acyclic Graph. And in a graph, there are two kind of nodes: input nodes that represent the arguments of the generated function, and function nodes that represent function calls. There are also two kind of edges: data edges that represent how data flows from one node to another, and control edges that represent the order in which function calls should be executed.
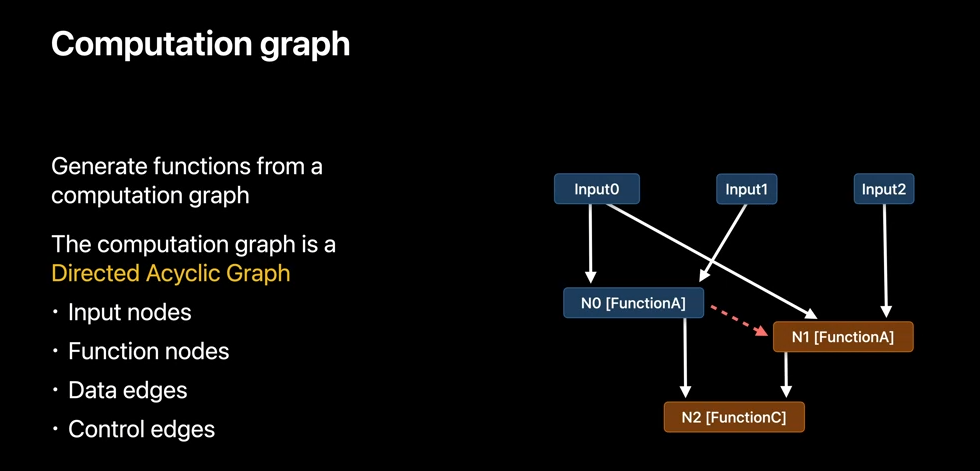
We'll see how function stitching uses a computation graph to generate a function. We'll start with the notion of stitchable functions. The function in a graph must have the stitchable attribute. Such function is a visible function, which can be used with the functionStitching API. The stitchable functions can be part of the Metal library shipped with your application bundle to avoid Metal to AIR translation cost. The stitching process generates the functions directly in AIR and completely skipping the Metal frontend. The generated function is a regular stitchable function, so it can be linked into a pipeline, or used directly as function pointer, or it can be used for generating other functions. So, consider the previous graph, and let's assume that we have dual functions A and C from library as described previously.

Let's now see what happens when we bind these functions to the graph. The stitcher here associates a corresponding function type to each function node. N0 and N1 get the type from FunctionA, and N2 gets the type from FunctionC. After that, the stitcher infers the types for the input nodes by looking at the parameter types of the functions using them. For example, Input0 is inferred to be the type devised in pointer because it's the first argument for N0 and N1. The stitcher then generates a function equivalent to the following one described in Metal. With the functionStitching API, we can generate a library containing such functions directly from AIR.
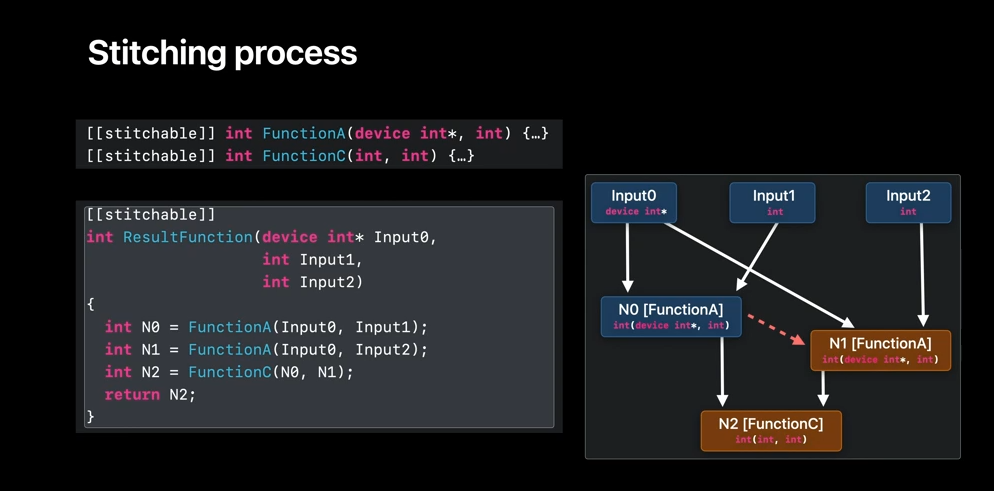
And now that we have fair idea on how stitching works, here is how you can use it in the API. First, we need to define the stitched function inputs. In this case, we simply make enough input nodes to account for all the arguments. Next, we create function nodes for each function we wish to call in our graph. For each function call, we define the name, arguments, and control dependencies if we have any explicit ordering requirements. And finally, we create the graph with the function name, the function nodes used in a graph, and any function attribute we want to apply. You also assign an outputNode, which will return the output value of the resulting stitched function. So, we have our graph.

Now, we can create a function using it. The first step is to create a StitchedLibraryDescriptor. We add our stitchableFunctions and functionGraph to this descriptor. We then create a library using the descriptor, and now, we can create our stitched function out of this library. This stitched function is now ready to be used anywhere a stitchable function is expected, including as a function in another stitching graph. And that's it for the function stitching.

This API is also available across all devices in macOS Monterey and iOS 15.

recap
So, as a quick recap, today, we looked at dynamic libraries and function pointers for render pipelines. Private linked functions, which can be used to statically link visible functions. And how function stitching can save compilation time when dynamically creating shaders.

So, when would you choose one over the other? Dynamic libraries are an excellent choice to link helper and utility functions. And they are best used when you have a fixed set of utility functions, and those functions do not change very frequently.

Function pointers add the ability for a shader to invoke functions that it knows nothing about, other than their signature. It doesn't need to know how many functions exist, the names, or even what speed-flexibility trade-off the developer has made using AIR or binaries. And this year, you can also cache function pointers.

Private functions offer you a way to statically link functions to a pipeline state object by name. They are internal to the pipeline, so they cannot be encoded in a visible function table, but they allow the compiler to do maximum optimization, and they are supported across all GPU families.

And finally, function stitching gives you a way to precompile snippets of your code directly to AIR and perform function compilation at runtime. If you are compositing Metal shader strings today and have to pay the cost of compiling from source at runtime, then function stitching would greatly accelerate this workflow.

I hope that you can leverage these compiler features to develop new experiences using Metal. Thanks for watching, and enjoy the rest of WWDC 2021.

虽然并非全部原创,但还是希望转载请注明出处:电子设备中的画家|王烁 于 2021 年 10 月 26 日发表,原文链接(http://geekfaner.com/shineengine/WWDC2020_GettoknowMetalfunctionpointers.html)