本节内容,来自Target and optimize GPU binaries with Metal 3
关联阅读:
- WWDC2020_Build GPU binaries with Metal
- WWDC2021_Discover compilation workflows in Metal
- WWDC2020_Get to know Metal function pointers
Metal Shader compilation model
In this session, Eylon and I are excited to share how you can improve your app's GPU binary generation with Metal 3.
First, I'll describe how offline compilation can help you reduce in app stutters, first launch, and new level load times.
Then Eylon will explain how you can use the optimize for size compiler option, to tune code expanding transformations and improve your compile times.
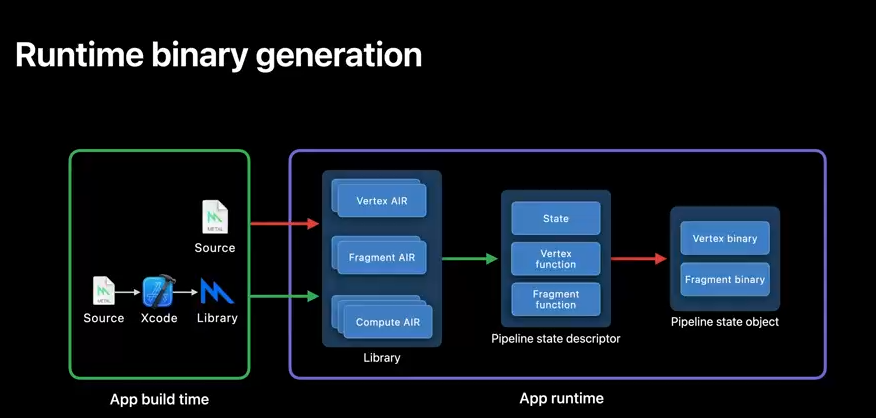
Offline compilation lets you move GPU binary generation to project build time.
To fully understand the benefits adoption can bring to your Metal application, I'll start by reviewing the ways in which you can already generate a GPU binary.

For example, suppose you instantiate a metal library from source.
This generates at app runtime Apple's Intermediate Representation, also known as AIR.
This can be a CPU intensive operation, which you can move to app build time by pre-compiling your source to a Metal library, and instantiating from a file instead.
Once your Metal library is in memory, creating a Pipeline State Descriptor containing state and functions is a lightweight operation.
Until you create your pipeline state object, which can be another CPU intensive operation, where just-in-time GPU binary generation takes place.
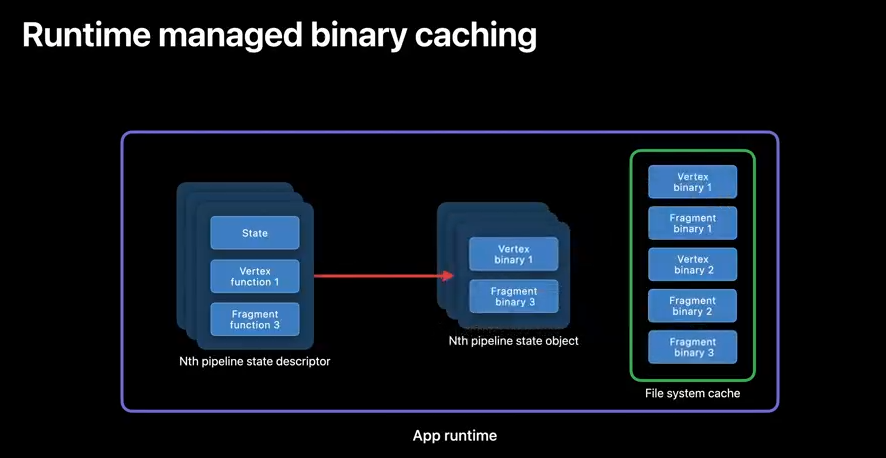
Since GPU binary generation at runtime can be a CPU intensive operation, Metal helps you speed up pipeline state object creation.
When you instantiate a PSO, Metal stores your GPU binaries in its file system cache.
And every time a new PSO is created, any newly generated functions are added.
So any previously generated binaries that are referenced will be loaded from the cache.
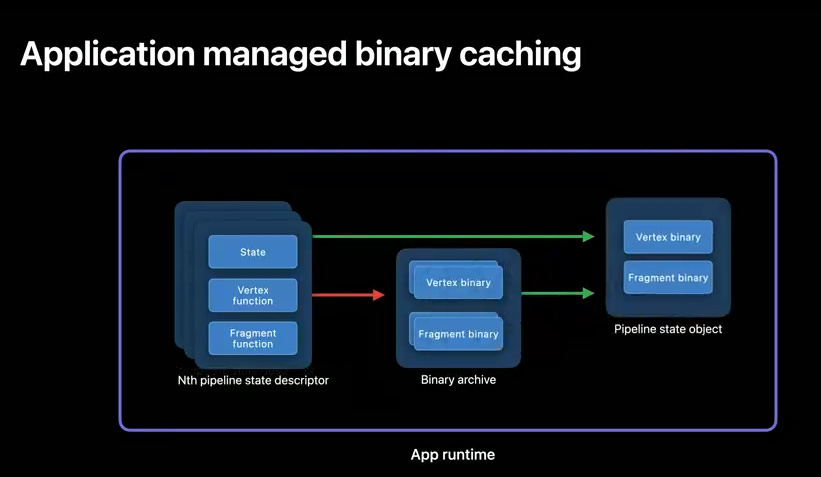
Metal also lets you explicitly control when and where GPU binaries are cached using Binary Archives.
Simply use a PSO descriptor to cache a GPU binary in an archive, as many times as you need.
Then your PSO creation becomes a lightweight operation.
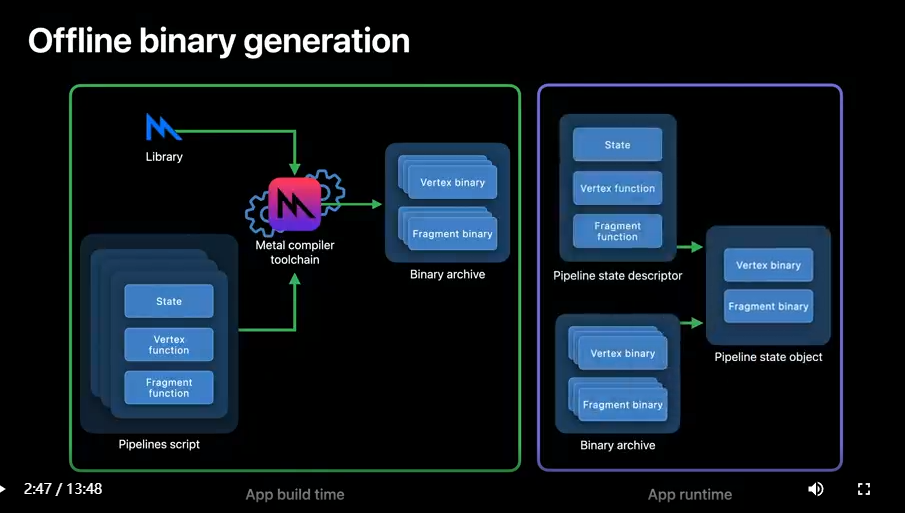
Binary archives enable more flexible caching, but they still have to be generated at runtime.
In many cases, what you really want is to generate those archives at build time, and now you finally can.
With offline binary generation, you specify a new artifact at project build time called Metal pipelines script, along with Metal source or a Metal library.
A pipelines script is your compiler toolchain equivalent to a collection of pipeline descriptors in the API.
The output of your compilation process is a binary archive.
No further GPU code generation takes place at app runtime.
Merely load your binary archive built offline to accelerate your PSO creation.
Offline compilation benefits your app by reducing runtime CPU overhead, which is at the core of what makes Metal a low level API.
Further, adoption can improve your app's experience in two noticeable ways.
First launch and new level load times can become dramatically faster, potentially resulting in greater engagement and interaction.
Stutters or frame rate drops, due to runtime compilation can be removed at last, without the memory or CPU cost of pre-warming frames.

I'll explore these benefits in more detail next.
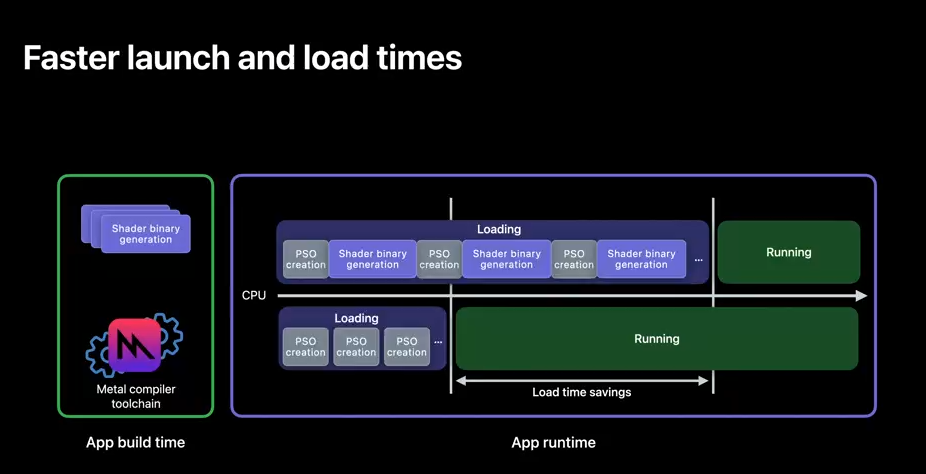
Here you have your traditional app runtime binary generation.
In this example, your app spends roughly 2/3 of its time compiling GPU binaries behind a loading screen, before you can begin interacting with it.
But with offline compilation your runtime shader generation moves to app build time, PSO creation happens in a fraction of the time, and you are able to interact with your app sooner instead of idling away at a load screen.
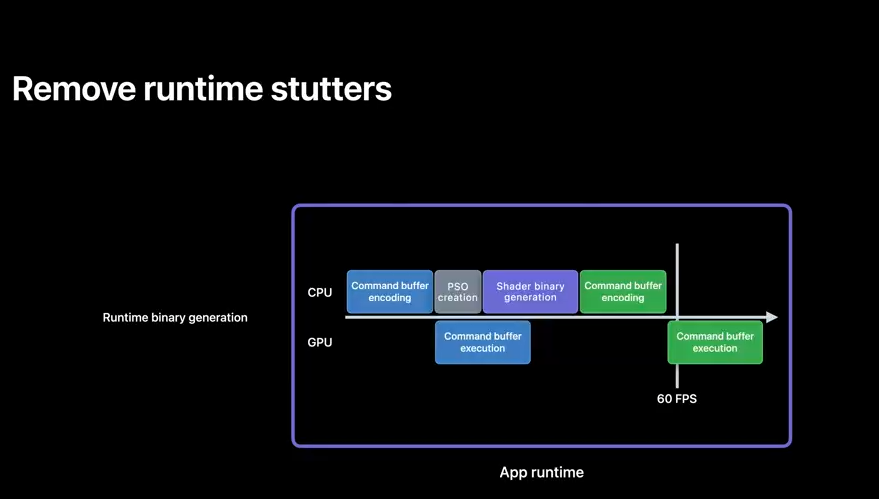
Offline compilation also helps to reduce stutters.
With traditional runtime binary generation, you may have too many pipeline states to create at load time, so you might instead be creating some just-in-time.
And when that happens, you may experience frame drops caused by compilation temporarily interrupting your command encoding.
Offline compilation removes those pesky bubbles, because you can compile many more shaders at app build time.
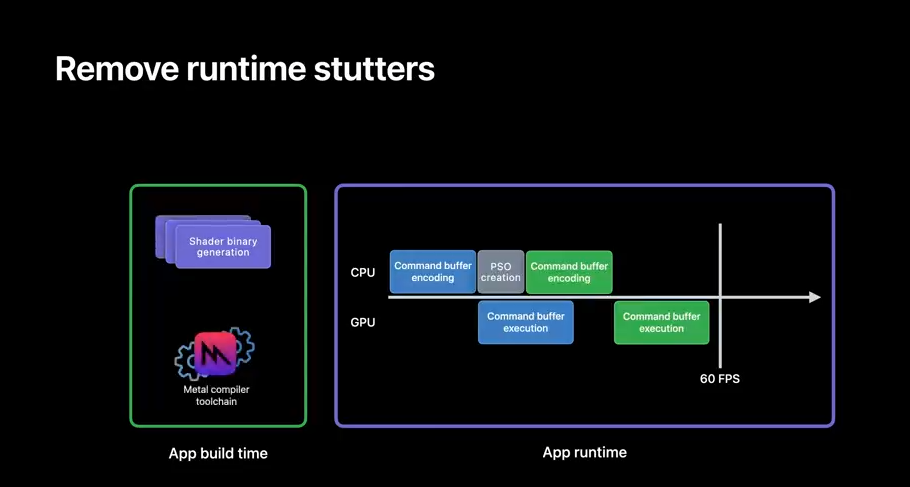
Next, I will share a new developer workflow to help you harness the benefits of offline compilation.
In the following workflow you'll learn how to use new toolchain features to build GPU binaries offline.
I'll show you how to generate your new pipelines script input artifact.
Then, how to invoke the toolchain to generate a GPU binary.

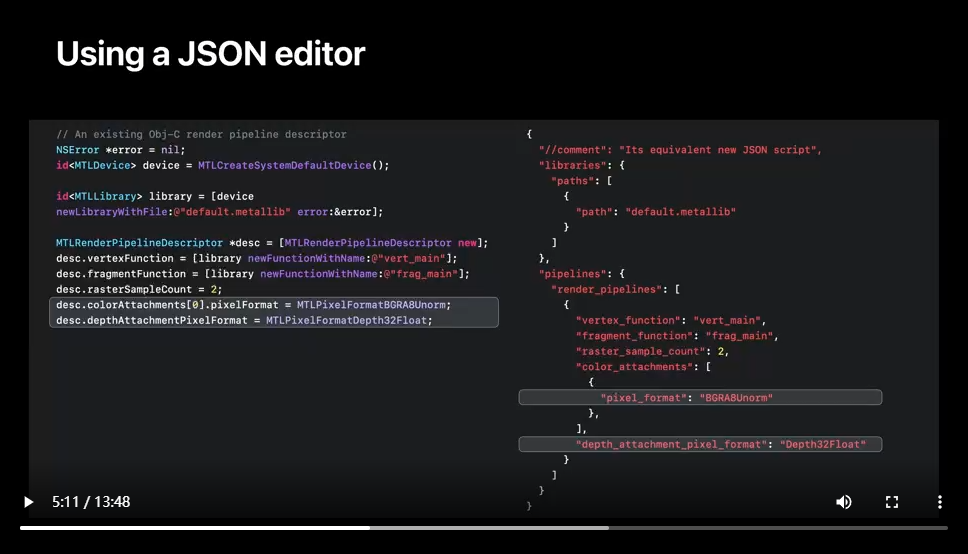
A pipelines script artifact is a JSON formatted description of one or more API pipeline state descriptors and can be generated in many ways.
For example, author them in your favorite JSON editor, or Harvest them from binary archives serialized during development and testing.

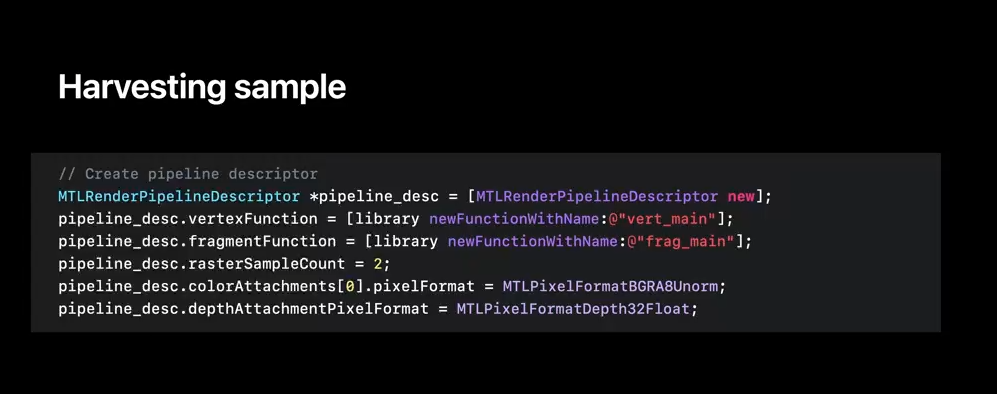
Here you have a snippet of Metal code that generates a render pipeline descriptor with state and functions and its equivalent JSON representation.
First, your API metal library file is specified as a libraries path property.
Then your API render descriptor function names as render pipelines properties.
Lastly, other pipeline state, like raster_sample_count or pixel formats, are also captured as script properties.
Look for further JSON schema details in Metal's developer documentation.
You also may want to kickstart JSON script generation, and using the Metal runtime can help.
Simply generate your binary archives at runtime, and serialize them during your development and testing process.

Now I'll show you how you can accomplish this with the Metal API.
You begin the runtime harvesting process by creating your pipeline descriptor with state and functions, adding it to an archive, which generates GPU binary, and serializing it to the file system to import into and load from your app's bundle.
The Metal 3 runtime stores your pipeline descriptor alongside the GPU binary.
Now I'll show you how to extract them.
metal-source allows you to extract your JSON pipelines script from an existing archive.
This is handy for migrating your binary generation from runtime to app build time.
Just invoke metal-source with the flatbuffers and output directory options.
The result is a pipelines script file, which you can edit to generate additional binaries.

Now, I'll show you how to invoke the toolchain.
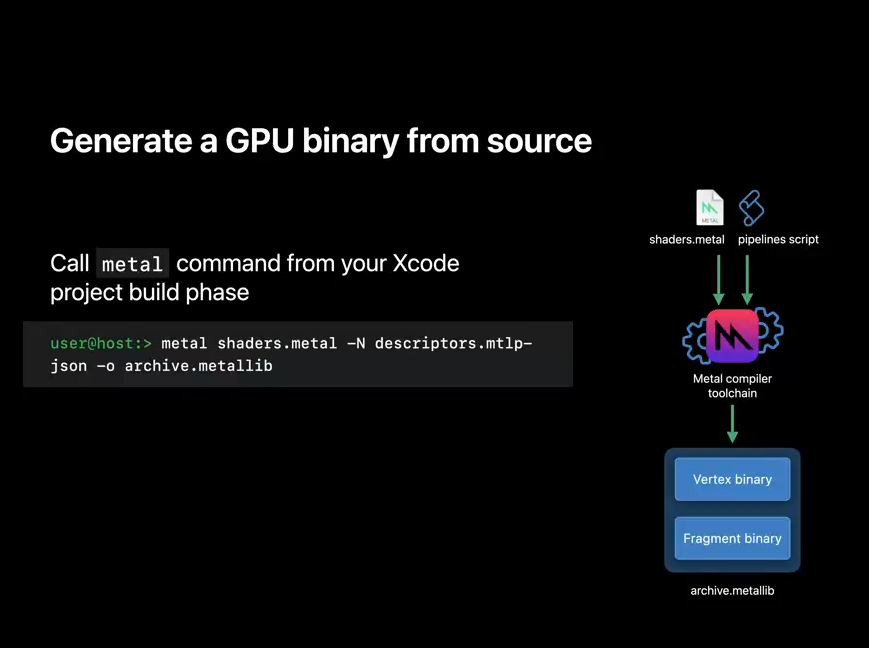
Generating a GPU binary from an Xcode project build phase is easy.
Simply invoke metal as you would from the terminal with your source, pipelines script, and output file.
Your output metal library now contains GPU binary, and can be deployed across any toolchain supported device.
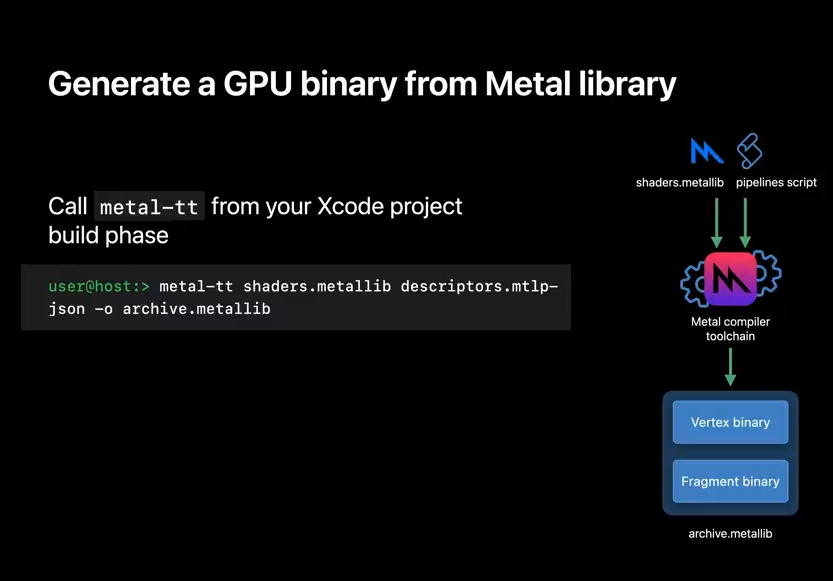
And if instead of source, you have a Metal library, you can pass that to the toolchain too.
Generating a binary from a pre-existing Metal library is just as easy with Metal translator tool.
Just call metal-tt as you would in a terminal with your source, pipelines script, and output file.
Your resulting Metal library now contains GPU binary for all toolchain supported devices.
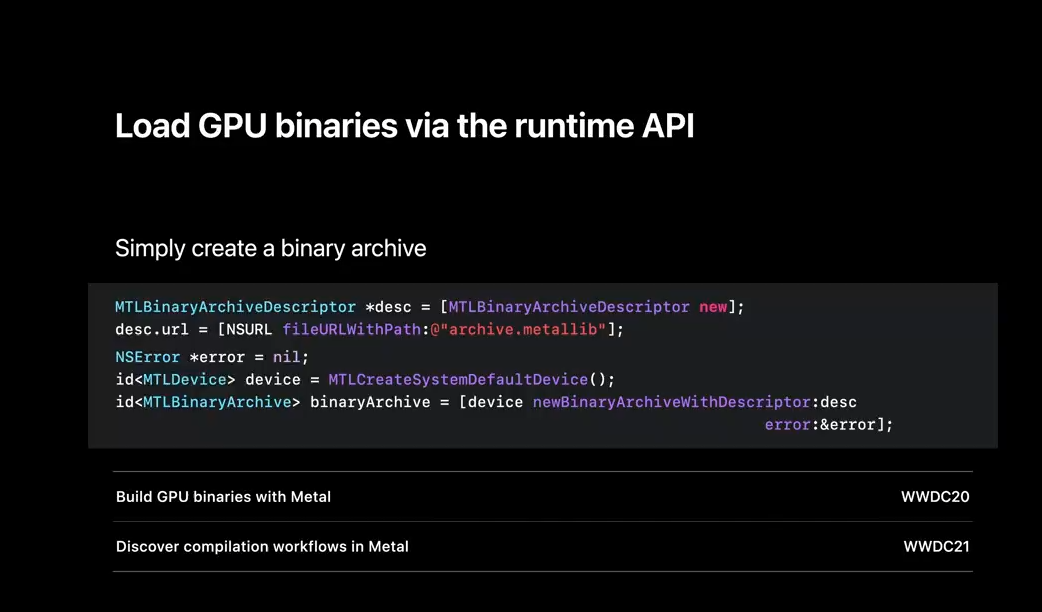
Now that you know how to create binaries offline, I'll review how to load them.
Simply provide the binary URL when creating an archive descriptor and use it to instantiate an archive.
That's it! For more information about Metal's binary archive API, please refer to our previous years' talks.
Finally, a note on how Metal handles GPU binary compatibility for offline generated artifacts.
To ensure your offline generated binaries are forward compatible with future OS versions and products.
Metal gracefully upgrades your binary archives during OS updates or at app install time.
It does so asynchronously, and in the background.

I can't wait for you to harness the benefits of offline compilation to remove runtime stutters and reduce first launch and new level load times.
Such improvements can be tangible to others and enhance their overall app experience.
Next, I'll introduce the new compile option, optimize for size. The Metal compiler optimizes code aggressively for runtime performance. Some optimizations expand the GPU program size, which may introduce unexpected costs. For example, function inlining is an optimization to avoid the overhead of a function call. It works by inlining the body of the called function into the call site. This example kernel doesn't look like a lot of code, but after inlining, it would contain a copy of functions 'f' and 'g', and potentially also of functions called from 'f' and 'g', such as helpers and non-primitive library functions. Another optimization is loop unrolling, which inlines additional copies of a loop body, to expose parallelism across iterations and to avoid branching overhead. The compiler may unroll as few as two iterations of the loop or as many as all the iterations of a loop that has fixed bounds. When optimizations like these create a very large program, the compiler also has to spend a lot more time compiling it, and in some situations, you may prefer to avoid those costs. Xcode 14 introduces a new Metal optimization mode: optimize for size. This mode limits size-expanding transformations, such as inlining and loop unrolling, when the compiler applies performance optimizations. The intended benefit is to keep the GPU binary smaller, and the compile time shorter, in cases when default optimization proves to be too expensive. When optimizing for size, it is possible for the result to have lower runtime performance. Whether that actually happens depends on the program, so you will need to try both optimization modes and compare. Optimize for size may not improve size and compile time for all shaders. It is most likely to have benefit for large programs with deep call paths and loops, where inlining and unrolling are common. The option is worth trying whenever you encounter an unexpectedly long compile time from default optimization. The option is available whether compiling at project build time or at app runtime. Here's a case where optimize for size can make a difference. Cycles is a an open source project implementing a production renderer for the Blender 3D design environment, and was recently updated to support Metal. Apple recently joined the Blender Development Fund, and one of the things we learned was that Blender's path tracing algorithms use large compute shaders, with many helper functions and loops, and its compile times can add up to minutes. It turns out those are exactly the kind of shaders that can benefit from Metal 3's new optimize for size option. When rendering these scenes on an Apple Silicon GPU, enabling optimize for size improved Blender's Setup Time, which includes compiling shader pipelines, by up to 1. 4x. And it provided that speedup with little or no degradation in Render Time. Some renders slowed up to 4%, and some did not slow at all. So lower runtime performance is possible. But in some cases, optimize for size can also improve runtime performance. Here's an example. These are Render Time speedups for the same scenes from enabling optimize for size on Intel GPUs. The benefit was not just faster compiles, but also some faster renders, by up to 1. 6x. How? Because a smaller GPU program can avoid some of the runtime penalties that come with large size: it may enjoy fewer instruction cache misses, or need fewer registers, which translates to fewer spills to memory or even more threads in parallel. Keep in mind, these results are not typical of all shaders and scenes, and a performance drop is possible. For your project, you will need to evaluate the actual impact to both compile time and runtime performance. You can enable optimize for size when compiling from Metal source, in three different environments. In the Xcode 14 user interface, specify optimize for size as a build setting. Under "Metal Compiler - Build Options" find the setting "Optimization Level". Level "Default" optimizes for performance, as Metal has done in the past. Level "Size" enables optimize for size. When compiling Metal source by command line, specify optimize for size using option'-Os'. The first example specifies the option to a single compile-and-link command. The second example has two compile commands and specifies the option to just one of them to enable it for only some shaders. The option does not need to be passed to the link command or to any subsequent commands. And you can use optimize for size either with, or without, generating a GPU binary using the commands presented earlier in this talk. Finally, when compiling Metal source at app runtime with a Metal Framework API such as 'newLibraryWithSource', specify optimize for size in a 'MTLCompileOptions' object using property 'optimizationLevel'. The optimization level may be 'default' or 'size'. I hope your project will benefit from this new optimization mode in the Metal compiler. Galo: To wrap up, I presented offline compilation, a new workflow for generating GPU binaries entirely at app build time, to reduce in-app stutters, first launch, and new level load times. Eylon: Then I presented optimize for size, a new Metal optimization mode when compiling from source, to reduce program size and compile time. Galo: We hope these improvements help your app or game deliver an improved user experience. Eylon: With shorter setup and load times, fewer stutters, and new workflows, thanks to lower compile costs at runtime.
虽然并非全部原创,但还是希望转载请注明出处:电子设备中的画家|王烁 于 2022 年 7 月 21 日发表,原文链接(http://geekfaner.com/shineengine/WWDC2022_TargetandoptimizeGPUbinarieswithMetal3.html)