本节内容,来自Optimize GPU renderers with Metal
I'm excited to talk to you about optimizing GPU renderers using Metal.
Modern digital content creation applications and game-engines empower content creators to interactively create and modify materials for their 3D assets.
There are several common techniques for handling these complex and dynamic materials at runtime.
Some applications compile materials into individual shaders and others use data-driven solutions such as uber shaders or shader virtual machines.
These material-centric workflows have two main performance goals.
Authoring of materials should be responsive for fast iteration and the best experience.
Rendering performance should be as good as possible for real-time interactivity and efficient final-frame rendering.
In this demonstration of Blender 3D, material editing is responsive.

When you modify a material slider in the user interface, the results are shown instantly in the viewport without any stutters due to shader re-compilation.
Once the material is modified, the resulting rendering performance is fast and interactive, giving content creators the ability to efficiently view the results of their work.
To achieve a responsive and performant workflow in your application, you can leverage key Metal features and implement Metal best practices.
Metal can help you maximize complex shaders' performance, leverage asynchronous compilation to keep the application responsive, compile faster with dynamic linking and tune your compute shaders with new Metal compiler options.

Maximize shader performance
Optimizing your shaders is the key to performance.
An uber shader is an example of a long and complex shader that can be used to render any possible material.
These types of shaders have lots of branches for any possible combination.
When artists create material, the material parameters are stored in a Metal buffer, used by the material shader.
This buffer gets updated when you change the parameters, but there is no recompilation required.
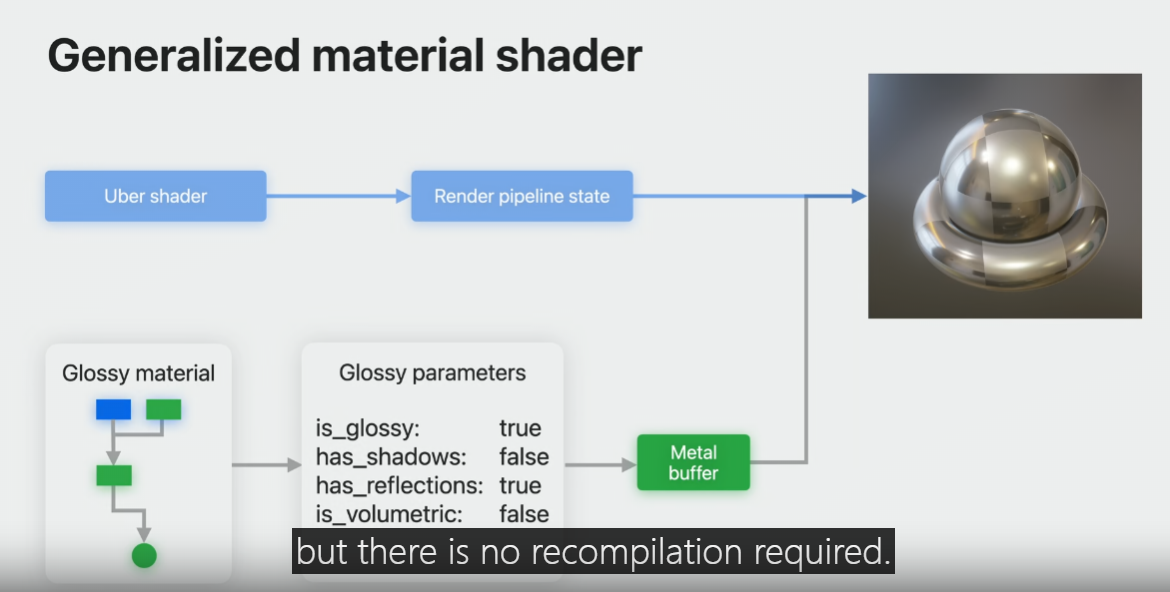
This approach provides a great responsive authoring experience.
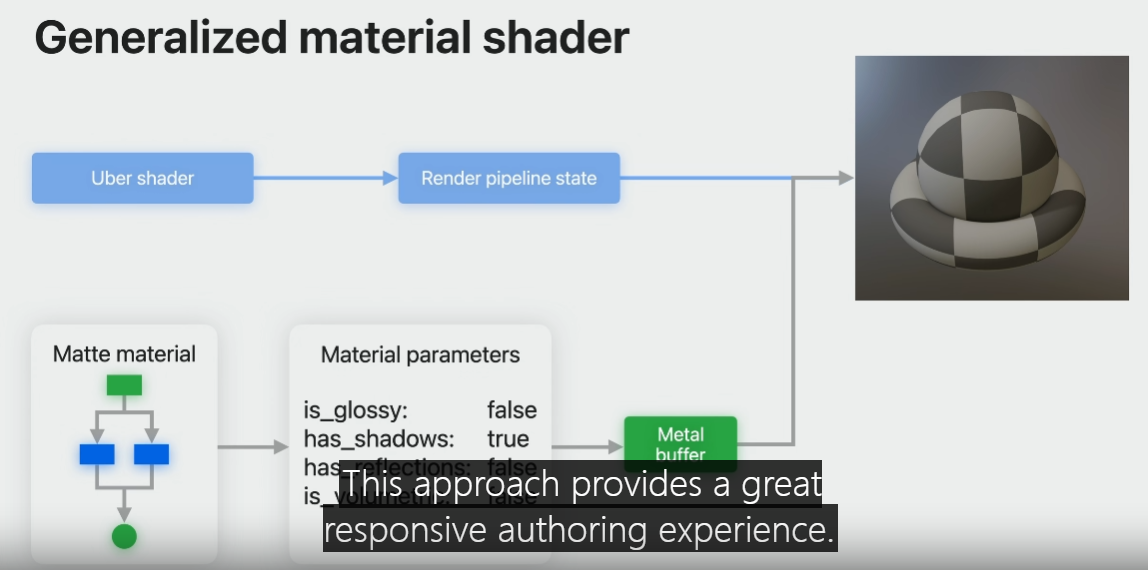
However, uber shaders are not optimal since they have to account for all the possible options.
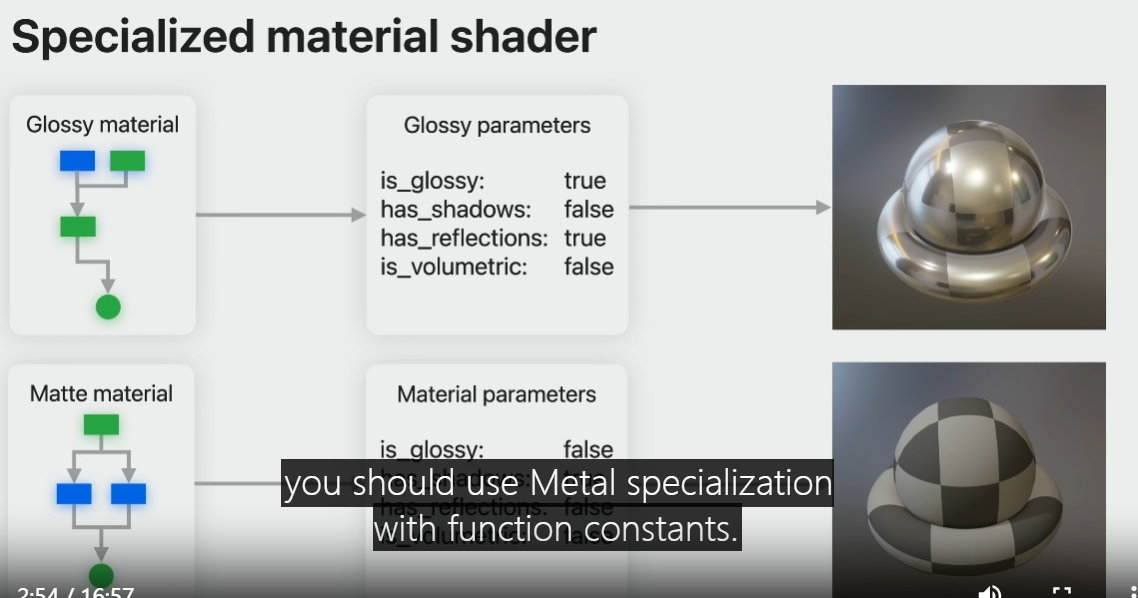
To make the most optimal shader variant, you should use Metal specialization with function constants.
Simply declare function constants in your Metal shader and set their values at runtime when they are changed.
The material buffer contents simply become constants in your shader pipeline states, dynamic branching is eliminated.
Specialized materials give you the most performance.
This is a comparison of real-time performance data from two common test assets in Blender 3D, Wanderer and Tree Creature.
First is the baseline performance in frames per second of the scenes using an uber shader.
Second is the specialized shader approach with function constants that performs much faster.

In order to make the fastest specialized shader variant, use function constants to disable unused features and eliminate branching.
An uber shader would query material parameters from a buffer doing conditional branches at runtime to enable and disable features.

With function constants you declare one constant per material feature.
Now the dynamic branch for the feature codepath is replaced with the function constant, eliminating all unused code.


Here is the same uber shader now using function constants.
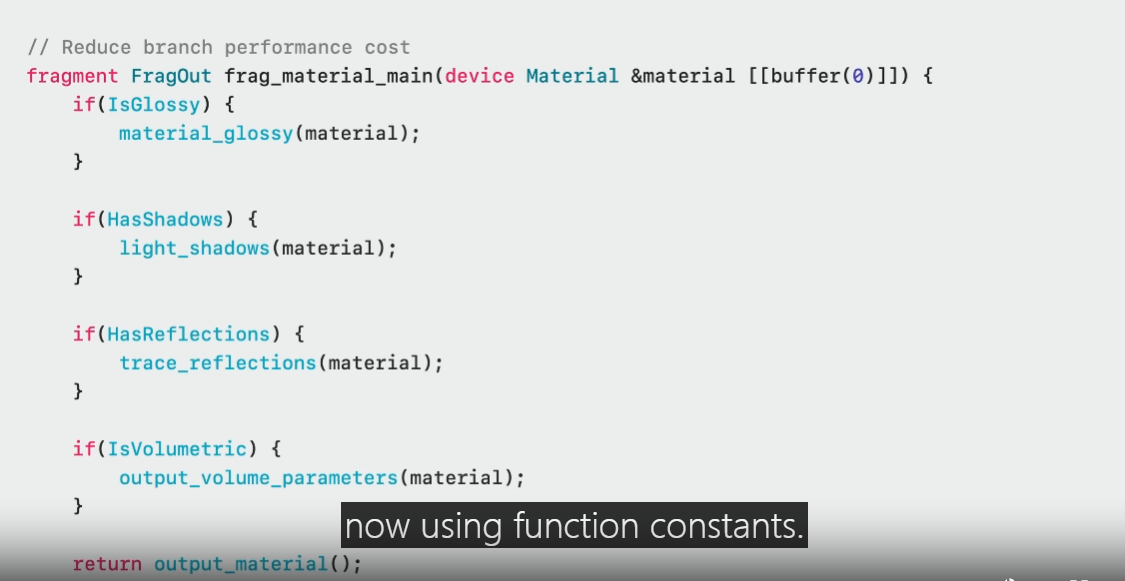
The Metal compiler can fold these as constant booleans and remove unused code.
Branch expressions that resolve to false will be optimized out, leaving only the true branches.
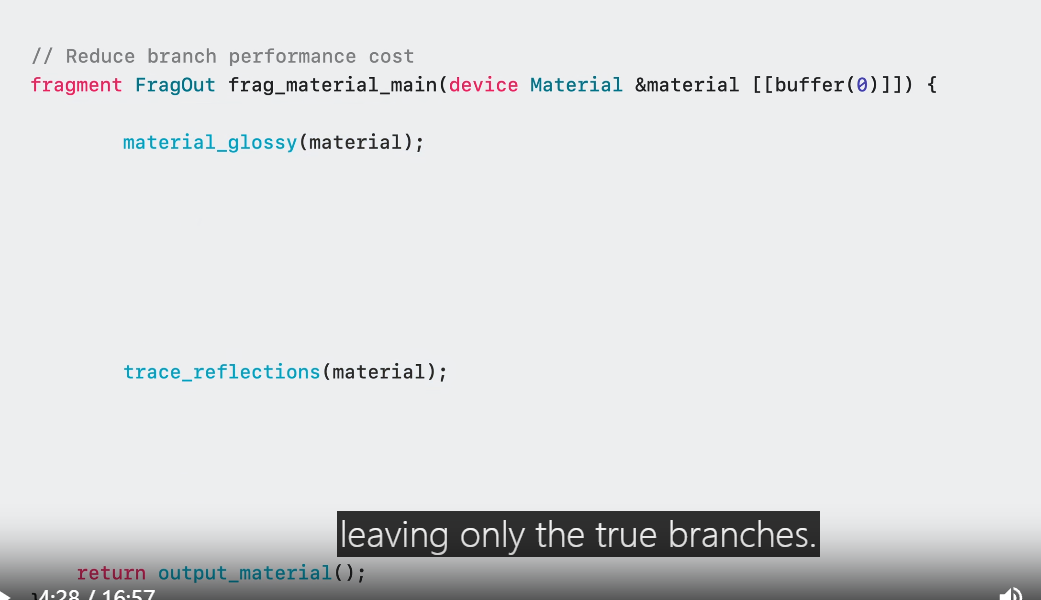
All the unused control flow is optimized out.
Specialized shader now does not need to query material data, having a much simpler control flow.
Memory loads and branches have been removed resulting in faster runtime performance.
Function specialization also helps with constants folding.

Material parameters that don't change are replaced with constants.
This example material uses a collection of input parameters from a Metal buffer.
The parameters could be color, weight, sheen color, and many more.

At material creation time, these static parameters can be replaced with function constants.
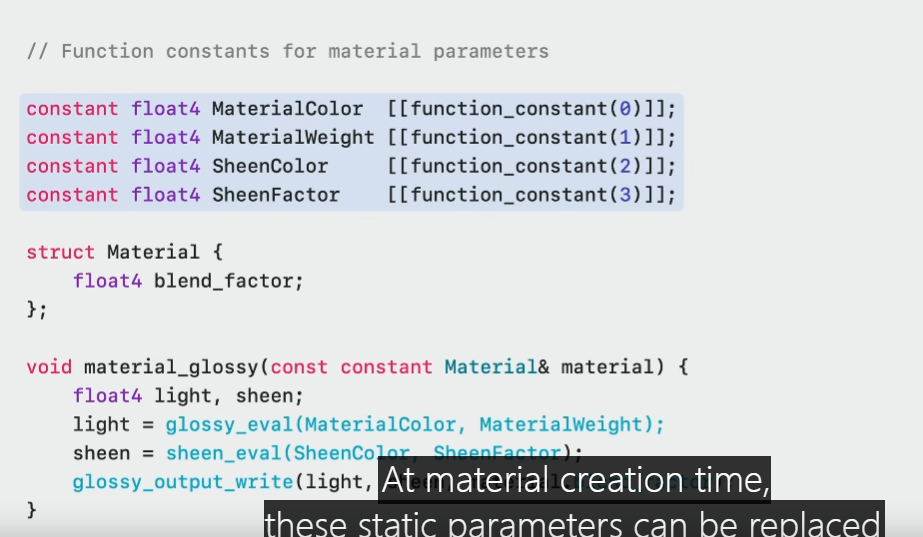
Function constants produce the most optimal code with no buffer reads required.
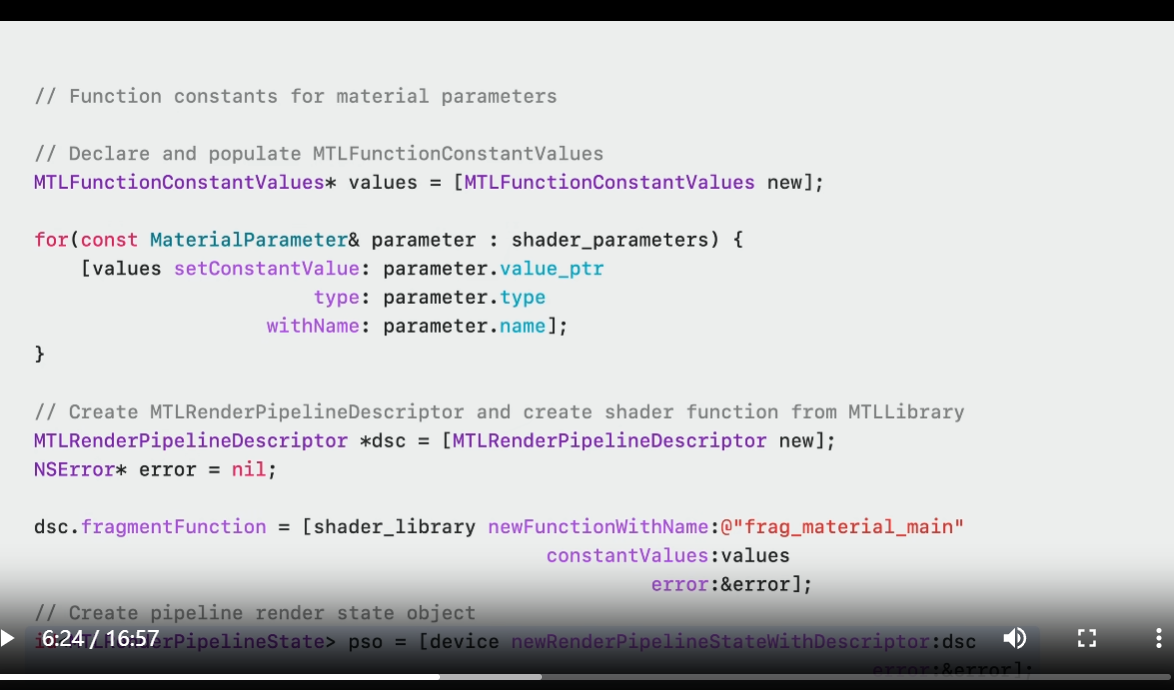
On the host side, function constant values are provided when creating a specialized pipeline state.

MaterialParameter structure can be used to represent all parameters that are constant for a material.
IsGlossy is an example of a boolean material feature flag controlling glossiness.
MaterialColor is an example of a vector parameter used to describe color.

To create a specialized Pipeline State Object, iterate over a MetalFunctionConstantValues set and insert the values using setConstantValue.
Then just create a Render Pipeline as usual.
The only difference is when creating the fragment function, you'd use the variant of newFunctionWithName with constantValues.
Finally, create your Pipeline State Object.
The resulting shader is the most optimal performing variant of this material.
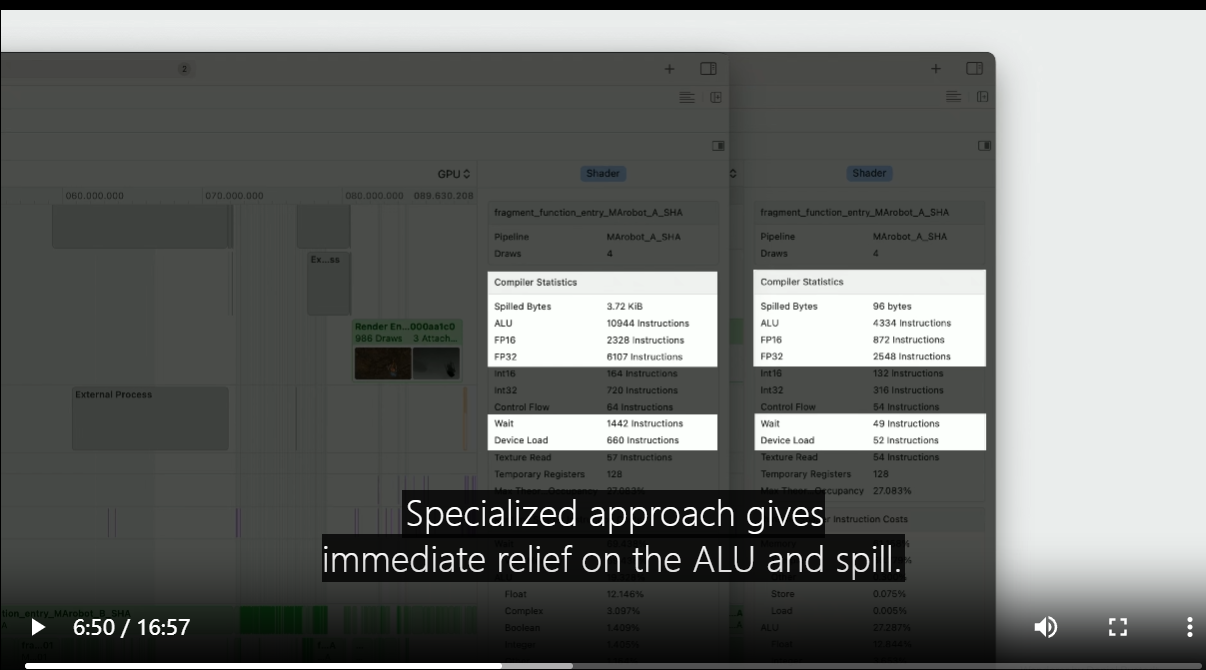
Always use Xcode's GPU Debugger Performance section to confirm the impact of using function constants.
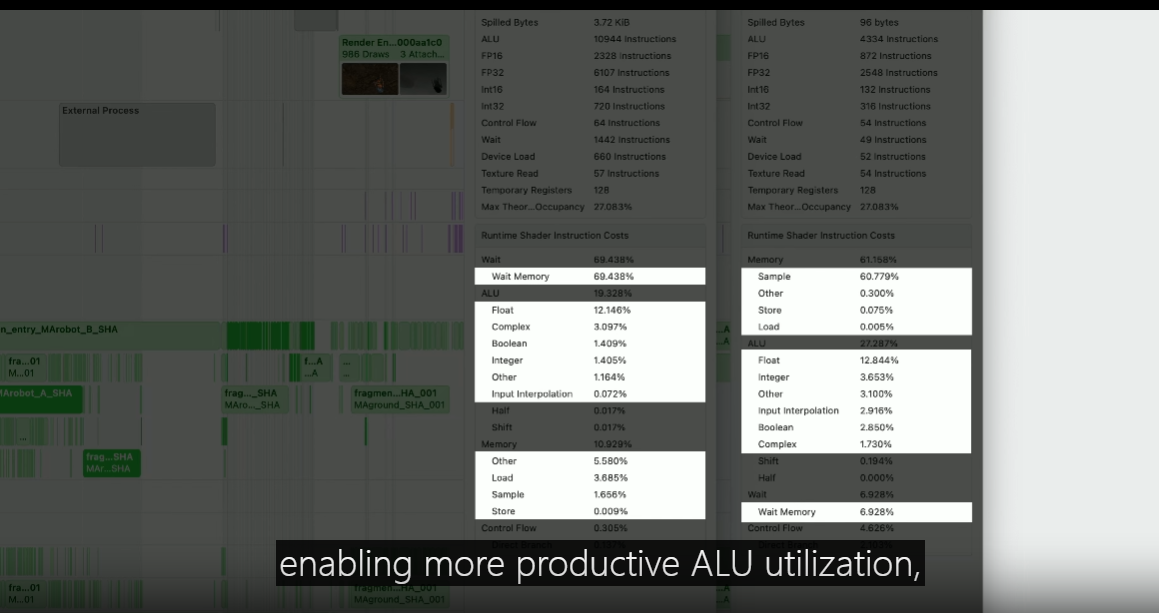
The original uber shader shows a high number of ALU instructions and a large amount of spill.
The number of memory waits is also large.
Specialized approach gives immediate relief on the ALU and spill.
This is due to dead code elimination and constants folding.
Also, the number of memory waits is significantly smaller.
Observing the original uber shader in runtime shader execution costs, the GPU is spending significant time on memory waits.
Specialized approach, in contrast, spends far less time on memory waits, enabling more productive ALU utilization, along with other efficiency benefits.
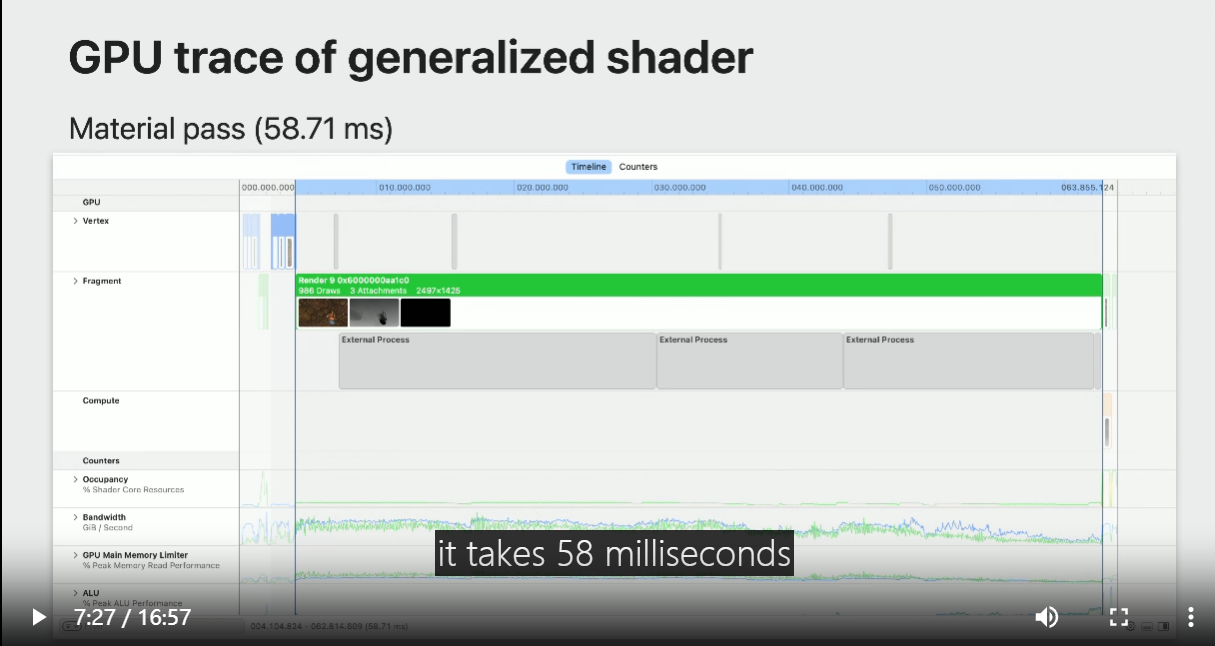
In the GPU Debugger timeline view, it takes 58 milliseconds to render the material pass using the uber shader.
And only 12.5 milliseconds to render with specialized versions.
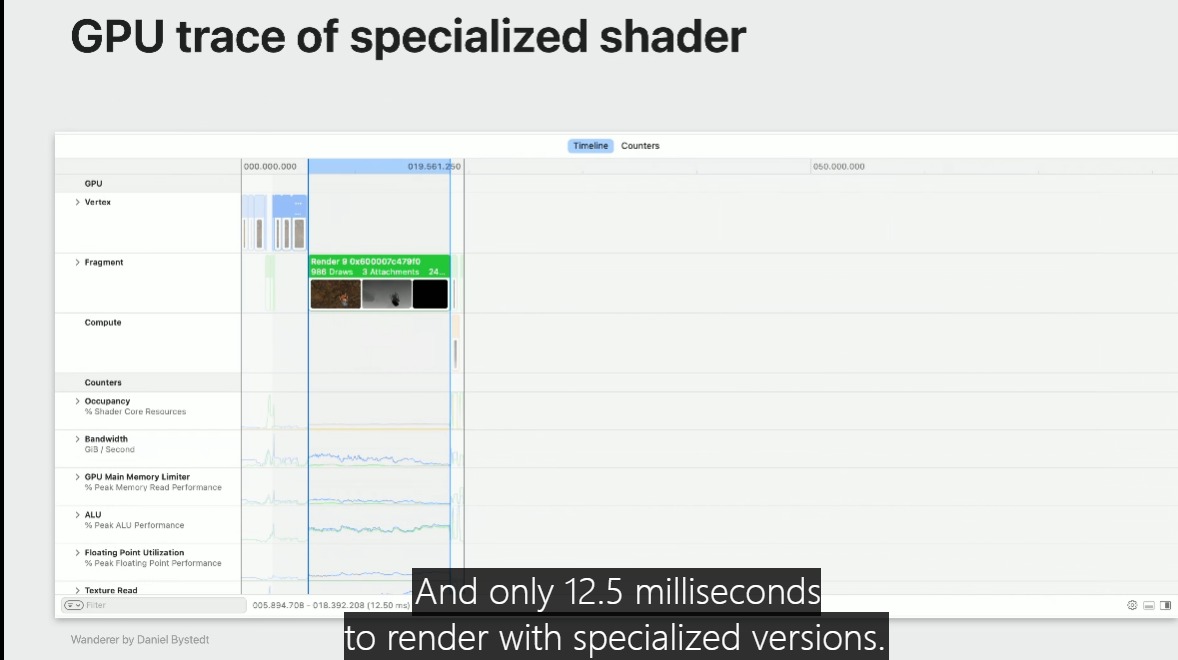
It's a pretty dramatic improvement.
Material specialization requires runtime shader compilation and this will often result in hitching if you block and wait for these specialized materials to be created.
Asynchronous compilation
The Metal asynchronous compilation APIs allow you to use generic uber shaders and keep user experience interactive and responsive, while generating specialized versions in the background.
To opt in to the asynchronous pipeline state creation, provide a completion handler.
These calls will return immediately allowing you to keep the user experience interactive and responsive.
Completion handler will be called when specialized pipeline state is ready, and you can switch to the optimal shader right away.

This is a diagram of an asynchronous material workflow.
By default, when the material has not yet been specialized, you use your uber shader.
At the same time, Metal compiles the specialized shader in the background.
Once this is done, you can switch out the uber shader for the fast specialized material.

Runtime Metal shaders compilation is designed to provide a balanced level of parallelism.
However, modern content creation applications need to provide multi-material editing workflows, resulting in many shader re-compilations.
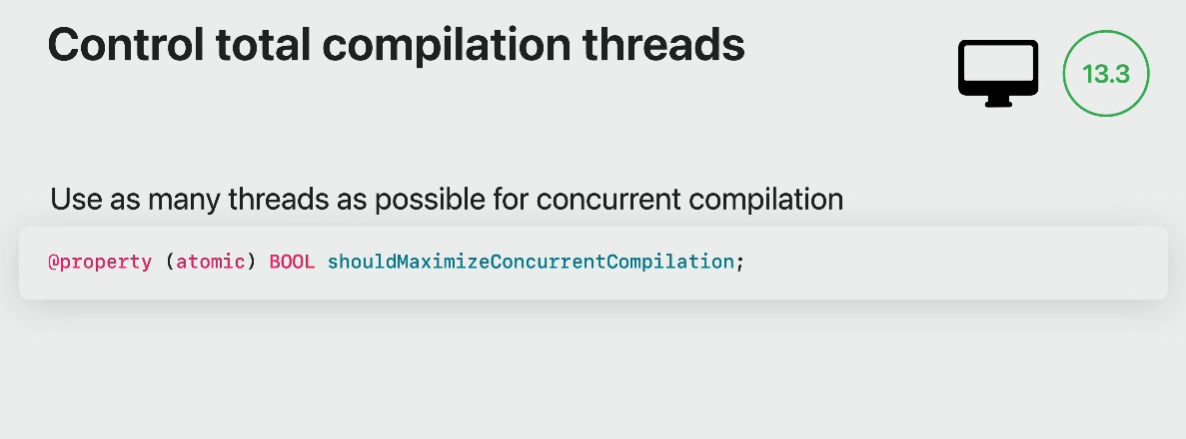
To help such heavy authoring needs, you may want to ask Metal to maximize shader compilation parallelism.
Metal device has a new property in macOS13.3 called should-Maximize-Concurrent-Compilation.
When you set it to Yes, Metal compiler will make the best use of your CPU cores.
Maximizing concurrent compilation is really great for multi-material authoring workflows.
With additional compiler jobs available, specialized material variants are available much sooner.
Here is how it all works in practice.

When material parameters are changed, the current specialized variants of the material are invalidated, there is a switch back to using the uber shader to keep authoring fluid.
A new async job is queued and once it completes, you can observe a substantial performance improvement once the specialized material is engaged.
Fast runtime compilation
Most modern apps have extremely complex materials, so it can take a significant amount of time for a specialized variant to be ready.
Dynamic libraries in Metal can be used to pre-compile the utility functions and reduce overall material compile time.
You do this by splitting up groups of functionality into separate dynamic libraries.
For even faster runtime compilation, utility libraries could be precompiled offline.
And you end up compiling much less code at runtime.

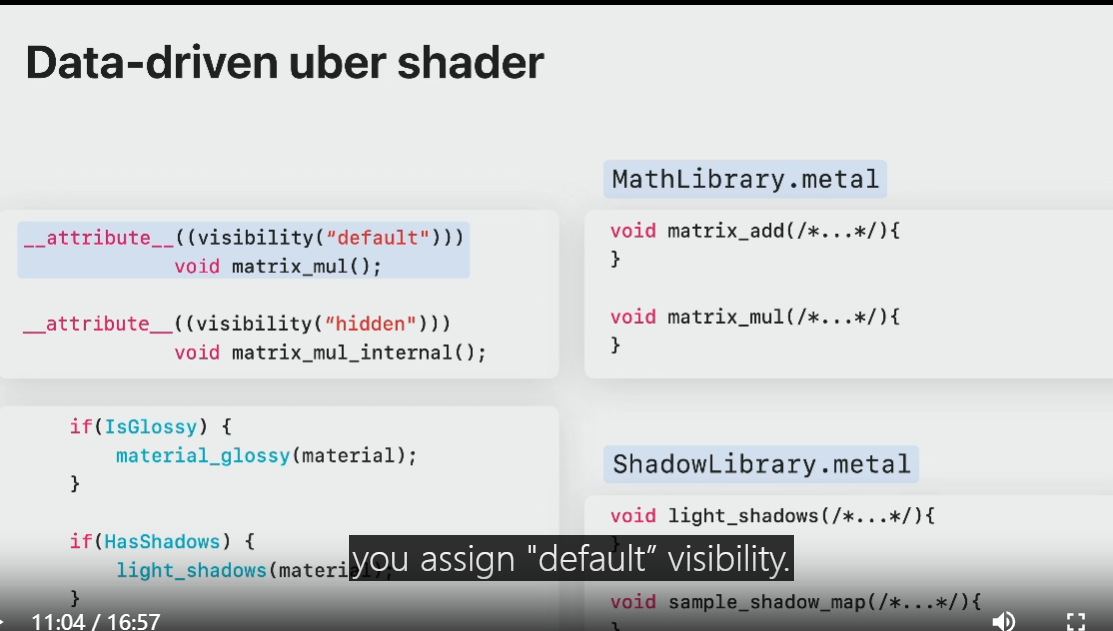
If I were to take the previous uber shader and split it into dylibs.
one approach is to split it by common groups of functionality.
In this case, one math utility library and another for lighting functions.
To make function symbols visible for linking, you assign "default” visibility.
Symbols can also be hidden from external programs by assigning visibility to "hidden".
There are two properties to check if your Metal device supports dynamic libraries.
For render pipelines you should use the supportsRenderDynamicLibraries property of the Metal device.
This is currently available on devices with Apple6 and above GPU families.
For compute pipelines you should query the supportsDynamicLibraries property.
This is available on Apple6 and above and for most of the Mac2 GPU families.

To create a dynamic library from an existing Metal library, simply call newDynamicLibrary and pass it a Metal library.
To create from the URL, call the newDynamicLibraryWithURL method and provide the path to the stored dynamic library.

You can precompile dynamic libraries offline using the metal compiler tool chain.
When loading precompiled dynamic libraries at runtime, compilation is completely avoided.

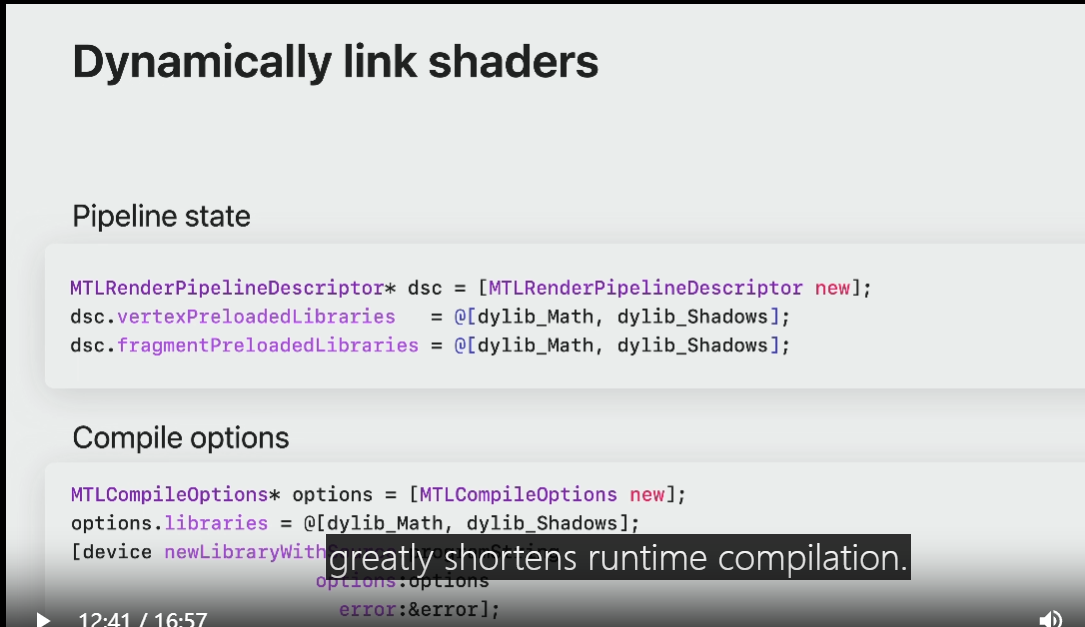
To specify dylibs in the linking phase: pass an array of Metal Dynamic Library Objects into the preloadedLibraries parameters on the pipeline descriptor.
There is also the option to provide this array of dynamic libraries via Metal Compile Options when compiling other shader libraries.
Moving large parts of utility code into dynamic libraries greatly shortens runtime compilation.
Tune compiler options
And finally, compiler options tuning is really important for compute cases like path tracing in the final production quality renders.
and there is one additional Metal feature to get the most performance out of your final rendering.
Metal compiler options and occupancy hints, enable you to tune the performance of any of these compute kernels specifically when working with dynamic linking.
Every GPU workload has a performance sweet spot that needs analysis and evaluation.
There is a Metal API to target desired GPU occupancy, that is also available for dynamic libraries now.
This can unlock performance for an existing workload without changing original code or algorithm.
It's worth noting that any tuning needs to be performed per-device as performance characteristics can vary depending on the GPU architecture.

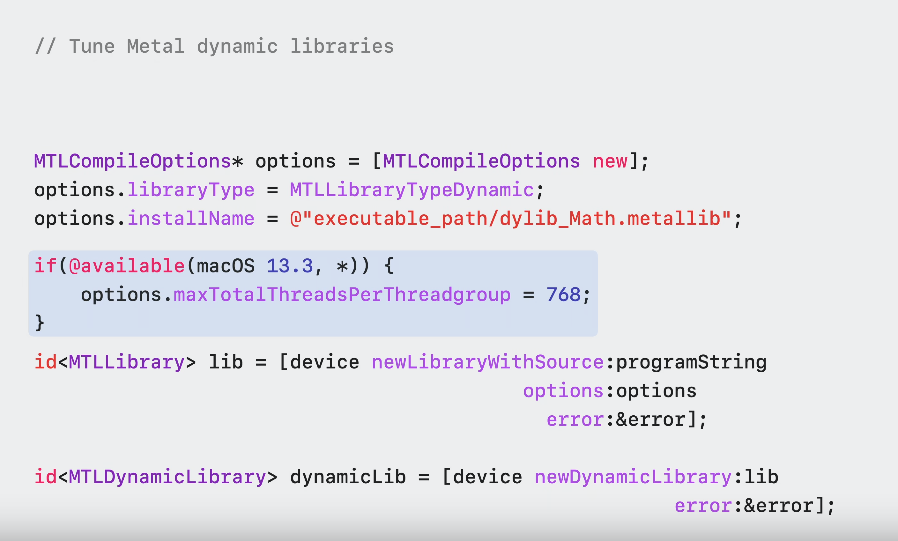
The Metal compute pipeline descriptor property allows you to express the desired occupancy level by specifying the Max-Total-Threads-Per-Threadgroup value.
The higher the value, the higher occupancy you hint the compiler to aim for.

Now, using this new Metal-Compile-Options property for dynamic libraries, you can match the pipeline state object desired occupancy level.
Max-Total-Threads-Per-Threadgroup is available for MetalCompileOptions in iOS 16.4 and macOS 13.3.

Now you can simply match the Pipeline State Object desired occupancy while tuning Metal dynamic libraries for the optimal performance.
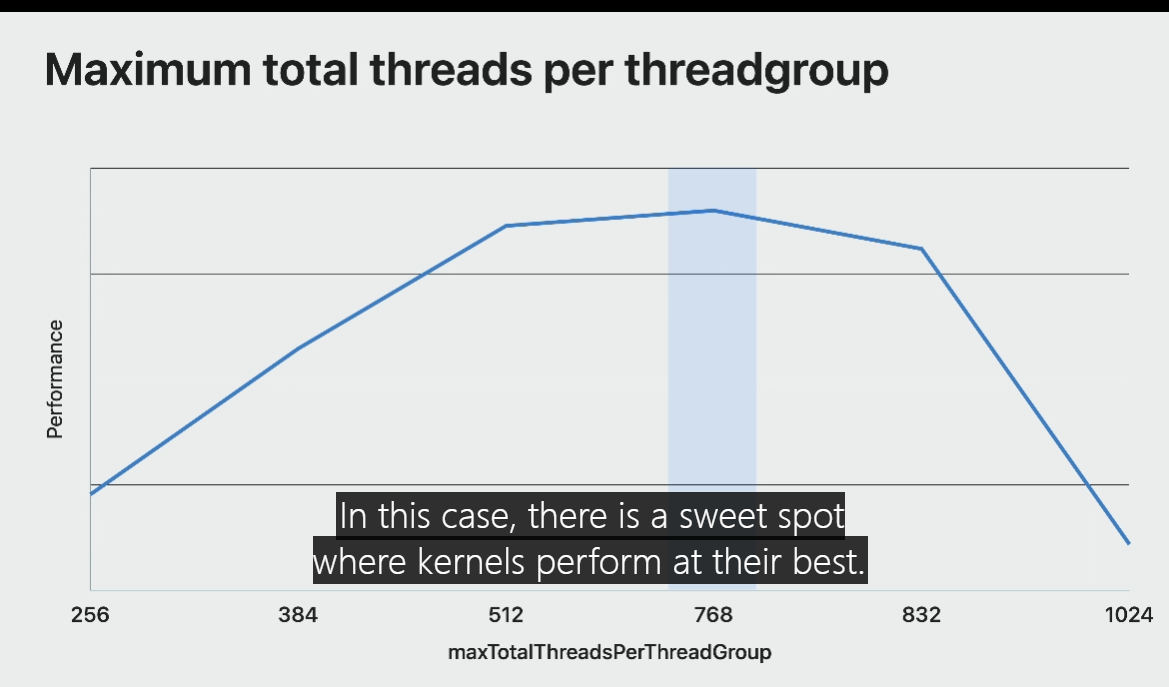
This graph of the Blender Cycles shading and intersection compute kernels performance shows the impact of changing Max-Total-Threads-Per-Threadgroup.
That was the only variable changed for the pipeline state object and the dylibs.
In this case, there is a sweet spot where kernels perform at their best.
Each workload and device is unique and the optimal value of Max-Total-Threads-Per-Threadgroup differs depending on the nature of the kernel.
The optimal value is not always necessarily the maximum number of threads per threadgroup a GPU supports.
Experiment with your kernels to find the optimal value you want to use and bake in the code.
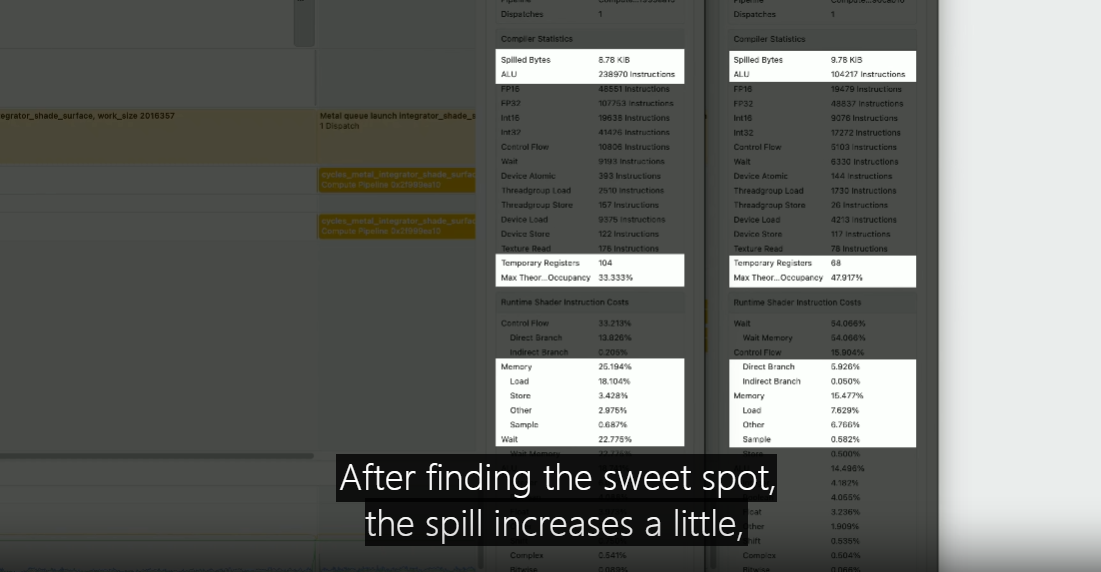
Here is a Blender Cycles shading kernel, The compiler statistics demonstrate that the kernel is very complex.
There are several parameters that affect the actual runtime.
The amount of spill, the number of registers used, and other operations like memory loads.
By tuning the Max-Total-Threads-Per-Threadgroup, you can change target occupancy and find that performance sweet spot.
After finding the sweet spot, the spill increases a little, but increased overall occupancy has led to significantly better kernel performance.
The Cycles path tracer within Blender 3D 3.5 is now well-optimized for Metal, and it uses all the best practices I covered today.
Remember to maximize shader performance of large and complex shaders using function specialization, use asynchronous compilation to keep the application responsive while generating optimized shaders in the background, enable dynamic linking for faster compilation at runtime, and tune your compute kernels with new Metal compiler options to get the optimal performance.
Be sure to check out previous sessions where you can learn how to scale compute workloads for Apple GPUs and discover more compilation workflows in Metal.

Thank you for watching.
虽然并非全部原创,但还是希望转载请注明出处:电子设备中的画家|王烁 于 2023 年 8 月 1 日发表,原文链接(http://geekfaner.com/shineengine/WWDC2023_OptimizeGPUrendererswithMetal.html)